こんにちは、ソリューションアーキテクトの蒸野(ムシノ)です。
今回は、Red Hat Developerのブログ Get started with Red Hat OpenShift Connectors | Red Hat Developer の翻訳記事を紹介させて頂きたいと思います。 一部、記事の内容を分かりやすくするため、オリジナルにない画面表示や補足事項を追加しています。ご承知おきいただけらと思います。
はじめに
「Red Hat OpenShift Connectors」は、Red Hat が提供する新しいクラウドサービスです。 システム間で迅速かつ信頼性の高い接続を実現するためのコネクタを提供するサービスであり、これらコネクタはフルマネージドで提供され、Apache Kafka向けのマネージドクラウドサービス である Red Hat OpenShift Streams for Apache Kafka と密接に統合されています。
Red Hat OpenShift Connectors は、現時点ではサービスプレビュとなっています。
サービスプレビュープログラムの一環とし、現在最大4つのコネクタをデプロイできますが、48時間後にはクリアされます。
コネクタにはソースコネクタとシンクコネクタがあり、ソースコネクタは外部システムから OpenShift Streams for Apache Kafka にデータを送信し、シンクコネクタは OpenShift Streams for Apache Kafka から外部システムへデータを送信することが可能です。現時点では50以上のコネクタを提供しており、これらには Camel K に基づく様々なクラウドサービスへのコネクタ、および、チェンジデータキャプチャの Debezium プロジェクトに基づくデータベース用のソースコネクタが含まれています。
利用可能なコネクタについては、下記で詳細を確認することができます。 www.redhat.com
それでは、OpenShift Connectors の基本的な使い方を紹介していきたいと思います。
前提環境
利用環境として、OpenShift Streams for Apache Kafka の利用を前提としており、事前にKafkaインスタンスの作成を行っておく必要があります。 また、Kafkaインスタンスのステータスが「Ready」状態であることも必要となっています。
例えば、下記のような Kafkaインスタンス を事前に用意下さい。

Kafkaインスタンスを作成するための手順については、下記を参照してください。 developers.redhat.com または、こちらの記事も是非ご参照ください。 rheb.hatenablog.com
OpenShift Streams for Apache Kafkaの設定
Red Hat OpenShift Connectors で使用するため、OpenShift Streams for Apache Kafka にはいくつかの設定が必要となります。 まず、 OpenShift Streams for Apache Kafka には、データソース側 が送信したメッセージを コネクタ が利用できるようにするための Kafkaトピック の作成が必要です。次に Kafka インスタンスとコネクタを接続して認証するためのサービスアカウントの作成、および サービスアカウントに対するアクセス権限の設定(コネクタによる Kafka トピックへのアクセスと使用方法の定義)が必要となります。
では、 OpenShift Streams for Apache Kafka の設定を行っていきましょう。
1. Kafkaトピックを作成する
まずは、Kafkaトピックを以下を参考に作成します。
- Red Hat アカウントで、https://console.redhat.com のハイブリッドクラウドコンソールにログインします。
- 「Application and Data Services」>「Streams for Apache Kafka」>「Kafka instances」 に移動し、前提環境で作成した Kafka インスタンスを選択します。
- 「Topic」タブを選択し、「Create Topic」をクリックします。
- トピックに名前(例:test-topic)を入力します。パーティション数やメッセージ保持、およびレプリカについては任意に設定ください。

2. サービスアカウントの作成
次に、OpenShift Streams for Apache Kafka にアクセスするためにのアカウントが必要です。以下のようにサービスアカウントを作成します。
- ハイブリッドクラウドコンソールで、「Service Accounts」を選択し、「Create a service account」をクリックします。
- サービスアカウントに名前を入力し、「作成」をクリックします。
- 「Client ID」と「Client Secret」が作成されます。これらの認証情報はコネクタを構成する際に使用しますので、安全なところに保存しておきます。
- サービスアカウント作成後「I have copied the client ID and secret」チェックボックスを選択し、「Close」 をクリックします。

3.サービスアカウントのアクセスレベルを設定する
サービスアカウントが作成できたら、次は必要なパーミッションを設定します。 今回の例ではサービスのコンシューマと別のサービスのプロデューサになる必要がありますので、両方のパーミッションを有効にセットします。 アクセスレベルを次のように設定します。
- ハイブリッドクラウドコンソールで、「Streams for Apache Kafka」>「Kafka instances」を選択します。前回同様、作成済みのKafkaインスタンスを選択します。
- 「Access」タブをクリックします。Kafkaインスタンスの現在のアクセス制御リスト(ACL)が表示されますので、[Manage access]をクリックします。
- 「アカウント」を選択するメニューが表示されるので、作成済みのサービスアカウントを選択し、[次へ]をクリックします。
- 「Assign Permissions」で、「Add permission」をクリックします。
- 「Add permission」のドロップダウンメニューから、[Consume from a topic] を選択します。すべてのリソース識別子の条件を is にし、すべての識別子の値を * に設定します。
- 「Add permission」のドロップダウンメニューから、[Produce to a topic] を選択します。すべてのリソース識別子の条件を is にし、すべての識別子の値を * に設定します。
パーミッション追加の設定画面は下記のようになります。

最終的にパーミッション設定後、次のようになっていれば問題ありません。

これで OpenShift Streams for Apache Kafka が、コネクタで使用できるようになりました。
ソースコネクタの作成
ソースコネクタは、外部データソースから Kafkaメッセージ を生成します。今回は、「Data Generator」 ソース コネクタを使用したいと思います。 このコネクタは、実際には外部システムからデータを取得しませんが、一定間隔でトピックにKafkaメッセージを通知します。 次のようにコネクタを作成します。
1.ハイブリットクラウドコンソールで、[Connectors]を選択し、[Create a Connectors Instance]をクリックします。
2.データソースとして使用するコネクタを選択します。利用可能なコネクタのカタログを参照するか、コネクタを名前で検索し、シンクまたはソースコネクタを見つけることができます。たとえば、「Data Generator」 ソース コネクタの場合には、検索ボックスに data と入力します。そうすると、「Data Generator」 コネクタのみが表示されます。「Data Generator」をクリックしてコネクタを選択、「Next」 をクリックします。

3.次に、先程コネクタ用に設定した OpenShift Streams for Apache Kafka インスタンスを選択し、「Next」をクリックします。

4.「Namespace」では「Create preview namespace」をクリックして、コネクタを所属させるための Namespace を作成します。
この Namespace は48 時間経つと削除されます。また、1 つのネームスペースにつき、最大 4 つのコネクタを作成することができます。
では、Namespace が作成できたら該当 Namespace を選択し、Next をクリックします。

5.コネクタのコンフィギュレーションを以下のように設定します。
5.1.コネクタの名前を指定します。 また、コネクタ用に作成したサービスアカウントの「Client ID」と「Client Secret」を入力し、Next をクリックします。
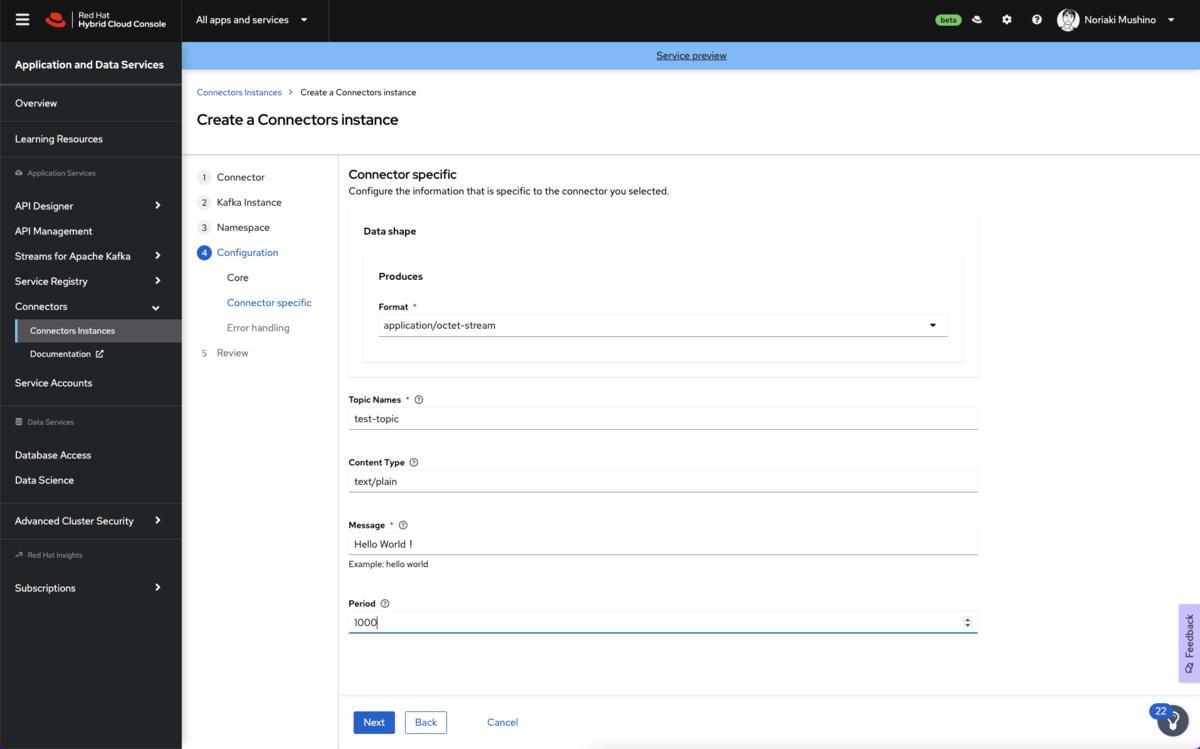
5.2.コネクタ固有の設定値をセットします。
- データ形式フォーマット:デフォルトのapplication/octet-streamとします。
- トピック名:コネクタ用に以前に作成したトピック名(例:test-topic)を入力します。
- コンテンツタイプ:デフォルトの text/plain とします。
- メッセージ:コネクタがKafkaトピックに送信するメッセージの内容を入力します。ここでは、「Hello World!」と入力します。
- 実行間隔:コネクタがKafkaトピックにメッセージを送信する間隔(ミリ秒単位)を指定します。今回は10秒ごとにメッセージを送信するので「10000」と設定します。
5.3.コネクタインスタンスのエラー処理ポリシーを設定します。
デフォルトは「stop」で、エラーが発生するとコネクタはシャットダウンします。
今回は、標準のまま「stop」を選択します。
5.4.設定内容のレビュー
最後に設定内容をもう一度確認し、「Create Connector」を行います。
コネクタインスタンスが表示され、コネクタの状態が表示されると思います。
数秒後、コネクタインスタンスが作成され、ステータスが Ready 状態に変わります。これでソースコネクタが作成できました。
ちなみにコネクタの停止、起動、削除する場合には、コネクタのオプションアイコンをクリックして操作を行うことができます。
5.5.Kafka Topicを確認する
既に、コネクタによってKafka トピックへの送信が開始されています。
Kafkaトピックの「message」タブをからメッセージの送信状況が確認できます。

シンクコネクタの作成
シンクコネクタは、Kafkaトピックからメッセージを取得して外部システムにメッセージを送信します。 今回は「HTTP Sink」コネクタを使用します。 HTTP Sink コネクタは、Kafkaトピックから Kafka メッセージを取得し、HTTP エンドポイントにメッセージを送信します。
Webhook.site サービスは、簡単にHTTP エンドポイントを取得するサービスを提供します。
今回は、これを使ってHTTPシンクコネクタからデータを送付します。
まずは、https://webhook.site に移動します。
このWebhookサービスのページにアクセスすると、下記のようにデータシンクとして使用できる URL が発行されます。

URL を取得したら、次のようにエンドポイントを設定します。
1.「Connectors」 を選択し、「Create Connectors instance」をクリックします。
2.HTTP Sink コネクタを見つけるには、検索フィールドに http と入力します。
3.HTTP Sink コネクタをクリックし、「Next]」をクリックします。

4.コネクタが連携する OpenShift Streams for Apache Kafka インスタンスを選択します。

5.「Namespace」ページで、ソースコネクタを作成したときに作成した Namespace を選択し、「Next」 をクリックします。

6.コネクタのコンフィギュレーションを以下のように設定します。
6.1. コネクタの名前を入力します。また、コネクタ用に作成したサービスアカウントの「Client ID」と「Client Secret」を入力し、[Next] をクリックします。
6.2. コネクタ固有の設定値をセットします。 HTTPシンクコネクタの場合、以下の情報を提供します。
- データ形式フォーマット:デフォルトのapplication/octet-streamとします。
- メソッド:デフォルトのPOSTのままにします。
- URL:Webhook.siteから取得したURLを入力します。
- トピック名:ソースコネクタに使用したトピック名前(例:test-topic)を入力します。

6.3. エラー処理ポリシーを停止に設定します。
6.4. 設定内容のレビュー コネクタの設定値をもう一度確認し、[Create Connector] をクリックします。 コネクタインスタンスが表示され、数秒後コネクタインスタンスのステータスが Ready 状態に変わります。 コネクタはKafkaトピックからメッセージを取得し、HTTPエンドポイントに送信します。
Webhook.siteのサービス上 から取得した固有の URL にアクセスすると、
ソースコネクタで定義した「Hello World!」メッセージが10秒間隔で表示されていることが分かります。

これで初めての Red Hat OpenShift Connector インスタンスを作成し OpenShift Streams for Apache Kafka にメッセージの送信と取得することが確認できました。 Red Hat OpenShift Connectors は外部システムやクラウドサービスへコネクタを使って連携することができます。是非とも他のコネクタを作成して機能を試してみて下さい。 次の記事では、Red Hat OpenShift Connector を使用してクラウドベースのデータベースに接続し、そのデータベースからデータ変更イベントを取得する方法を紹介します。
最後に
如何でしたでしょうか?
基本的な Red Hat OpenShift Connectors の利用でしたが、始め方が分かったのではないでしょうか?
また、サービスプレビュ版のため、一部の制限が掛かっていますが、便利なことは実感いただけたのではないでしょうか。
是非一度ご利用いただくことをお勧めいたします。