こんにちは、Red Hatでソリューションアーキテクトをしている石川です。 前回に引き続きRed Hat OpenShift Data Science(RHODS)についての記事となります。 rheb.hatenablog.com
今回はRHODSで利用できるカスタムイメージの作り方や、その他役立つ設定などをご紹介していきます。
カスタムイメージについて
前回の記事の中で、RHODSではデフォルトで利用可能な5つのコンテナイメージがあることに触れました。
・Minimal Python
・Standard Data Science
・CUDA
・PyTorch
・TensorFlow
それぞれのイメージの中身について詳しくは以下のドキュメントをご参照下さい。
access.redhat.com
しかしながら実際の機械学習においてはこれらのイメージの中で提供されるライブラリでは不足するケースがあるかと思います。
その場合、以下二つの選択肢が考えられます。
1) デフォルトのイメージを起動後、追加のライブラリをインストールする
2) 追加ライブラリを含むカスタムイメージを作成し、そちらを利用する
まず一つ目についてですが、アドホックに試したいライブラリを追加しながら開発をするという点では良いと思われます。ただし、無計画にpipでライブラリをインストールするとバージョンや依存関係の管理が困難となるため、Poetryやpipenvなどの管理ツールを利用するのが良いと思われます。
二つ目のカスタムイメージとはデフォルトで提供されるコンテナイメージとは別にユーザー自身が作成し登録、管理するイメージです。 複数のユーザーで共通的に使われることが分かっているライブラリなどがある場合は、予めそれを含めた形でコンテナイメージを作成しておくことで、ユーザー側でのインストール作業を無くし、環境準備に必要な手間や時間を節約することができます。 一方でデフォルトイメージではRed Hatがイメージに含まれるPythonのライブラリも含め管理しており、それらのバージョンアップも提供しますが、カスタムイメージではこうした作業はユーザー自身で行う必要があります。
カスタムイメージの作成方法としてゼロから自分でイメージを作成する方法もありますが、より簡単な方法としてデフォルトのイメージに対して必要なライブラリを追加し、別のコンテナイメージとしてビルドするやり方が考えられます。
今回はこの方法でカスタムイメージを作成し、RHODSに追加してみたいと思います。
カスタムイメージの作成1
まずデフォルトイメージの取得元を確認したいと思います。
RHODSをクラスタにインストールすると、デフォルトのコンテナイメージをredhat-ods-applicationsプロジェクト以下に見つけることができます。
oc get imagestream -n redhat-ods-applications --- NAME IMAGE REPOSITORY TAGS UPDATED minimal-gpu default-route-openshift-image-registry.apps.mycluster2.ljxh.p1.openshiftapps.com/redhat-ods-applications/minimal-gpu py3.8-cuda-11.4.2-2 2 hours ago pytorch default-route-openshift-image-registry.apps.mycluster2.ljxh.p1.openshiftapps.com/redhat-ods-applications/pytorch py3.8-cuda-11.4.2-2 2 hours ago s2i-generic-data-science-notebook default-route-openshift-image-registry.apps.mycluster2.ljxh.p1.openshiftapps.com/redhat-ods-applications/s2i-generic-data-science-notebook py3.8-v1 2 hours ago s2i-minimal-notebook default-route-openshift-image-registry.apps.mycluster2.ljxh.p1.openshiftapps.com/redhat-ods-applications/s2i-minimal-notebook py3.8-v1 2 hours ago tensorflow default-route-openshift-image-registry.apps.mycluster2.ljxh.p1.openshiftapps.com/redhat-ods-applications/tensorflow py3.8-cuda-11.4.2-2 2 hours ago
例えばここでs2i-generic-data-science-notebookの中身を見てみると、annotationの記載内容からイメージ取得元のQuayのリポジトリやコードを管理しているGitHubのアドレスを見つける事ができます
oc get imagestream s2i-generic-data-science-notebook -o yaml -n redhat-ods-applications
---
apiVersion: image.openshift.io/v1
kind: ImageStream
metadata:
annotations:
kfctl.kubeflow.io/kfdef-instance: rhods-nbc.redhat-ods-applications
opendatahub.io/notebook-image-desc: Jupyter notebook image with a set of data
science libraries that advanced AI/ML notebooks will use as a base image to
provide a standard for libraries avialable in all notebooks
opendatahub.io/notebook-image-name: Standard Data Science
opendatahub.io/notebook-image-order: "20"
opendatahub.io/notebook-image-url: https://github.com/red-hat-data-services/notebooks/tree/main/jupyter/datascience/ubi8-python-3.8 # GitHubリポジトリ
openshift.io/image.dockerRepositoryCheck: "2023-03-13T03:28:45Z"
creationTimestamp: "2023-03-13T03:28:44Z"
generation: 2
labels:
component.opendatahub.io/name: jupyterhub
opendatahub.io/component: "true"
opendatahub.io/notebook-image: "true"
name: s2i-generic-data-science-notebook
namespace: redhat-ods-applications
resourceVersion: "89518"
uid: 67a69042-65b9-43d9-b7d1-12130aaef565
spec:
lookupPolicy:
local: true
tags:
- annotations:
opendatahub.io/notebook-python-dependencies: '[{"name":"Boto3","version":"1.17"},{"name":"Kafka-Python","version":"2.0"},{"name":"Matplotlib","version":"3.4"},{"name":"Numpy","version":"1.19"},{"name":"Pandas","version":"1.2"},{"name":"Scikit-learn","version":"0.24"},{"name":"Scipy","version":"1.6"}]'
opendatahub.io/notebook-software: '[{"name":"Python","version":"v3.8"}]'
openshift.io/imported-from: quay.io/modh/odh-generic-data-science-notebook # Quayリポジトリ
from:
kind: DockerImage
name: quay.io/modh/odh-generic-data-science-notebook@sha256:ebb5613e6b53dc4e8efcfe3878b4cd10ccb77c67d12c00d2b8c9d41aeffd7df5
generation: 2
importPolicy:
importMode: Legacy
name: py3.8-v1
referencePolicy:
type: Source
コンテナイメージについては、
quay.io/modh/odh-generic-data-science-notebook
ソースコードについては、
https://github.com/red-hat-data-services/notebooks/tree/main/jupyter/datascience/ubi8-python-3.8
で管理されていることがわかりました。
それではこちらのGitHubリポジトリにアクセスしましょう。
 開くと
開くとubi8-python-3.8というディレクトリの中にコンテナイメージを作成するためのDockerfileや、Pythonのライブラリ依存関係を表すファイルなどがあるのがわかります。
Pipfile、Pipfile.lockはpipenvというPythonの依存関係管理ツールで利用されるファイル形式です。
Pythonでよく用いられるpipによるインストールでは、requirements.txtというファイルに使用したいライブラリのバージョンを書きますが、pip-toolsなどを使わない場合、各ライブラリのハッシュ値を含めた厳密な依存関係の管理を行うことができません。
pipenvではライブラリのインストール時にPipfile.lockというロックファイルを作成し、厳密な依存関係管理を可能としています。
またpipenv以外でよく使用されるツールとしてはPoetryがあります。こちらはPipfileを使用するpipenvとは異なり、ライブラリの依存関係等をpyproject.tomlというPEP518で標準化された形式で表現します。Poetryはpyproject.tomlからpoetry.lockというロックファイルを作成します。
Pipfileにライブラリを追加するパターン
まずはシンプルにPipfileへ利用したいライブラリを追記してみましょう。
先ほどのGitHubリポジトリでは同じStandard Data Scienceのイメージでも、UBI8 + Python 3.8、UBI9 + Python 3.9というベースイメージとPythonのバージョンが異なる複数のコードを管理しています。
今回はPython 3.9の方のPipfileを取得し、そこに追加したいライブラリの情報を加えます。
[[source]] url = "https://pypi.org/simple" verify_ssl = true name = "pypi" [dev-packages] [packages] # Datascience and useful extensions boto3 = "~=1.26.69" jupyter-bokeh = "~=3.0.5" elyra-python-editor-extension = "~=3.14.2" kafka-python = "~=2.0.2" matplotlib = "~=3.6.3" numpy = "~=1.24.1" pandas = "~=1.5.3" plotly = "~=5.13.0" scikit-learn = "~=1.2.1" scipy = "~=1.10.0" jupyterlab-lsp = "~=3.10.2" jupyterlab-widgets = "~=3.0.5" jupyter-resource-usage = "~=0.6.0" jupyterlab-s3-browser = "~=0.10.1" # Parent image requirements to maintain cohesion jupyterlab = "~=3.5.3" jupyter-server = "~=2.1.0" jupyter-server-proxy = "~=3.2.2" jupyter-server-terminals = "~=0.4.4" jupyterlab-git = "~=0.41.0" nbdime = "~=3.1.1" nbgitpuller = "~=1.1.1" # --- thamos = "~=1.29.1" wheel = "~=0.38.4" # 追加ライブラリ ray = "~=2.3.0" xgboost = "~=1.7.4" [requires] python_version = "3.9"
ここからpipenvコマンドでロックファイルを作成します。
作業環境にpipenvが無い場合はまずpipでインストールしましょう。
## pipenvのインストール # pip install pipenv # ロックファイルの作成 pipenv lock
これで追加ライブラリを含んだPipfile.lockが作成されました。
あとはこれをイメージに追加しコンテナをビルドします。
以下が今回利用するDockerfileです。
FROM quay.io/modh/odh-generic-data-science-notebook:v2
# Install Python packages and Jupyterlab extensions from Pipfile.lock
COPY Pipfile.lock ./
RUN echo "Installing softwares and packages" && micropipenv install && rm -f ./Pipfile.lock
# Fix permissions to support pip in Openshift environments
RUN chmod -R g+w /opt/app-root/lib/python3.9/site-packages && \
fix-permissions /opt/app-root -P
ベースイメージとして、先ほど確認したQuayのリポジトリからUBI9+Python3.9のイメージのタグを指定しています。
またCOPY句で、作成したPipfile.lockをコンテナ内に配置し、こちらを元にライブラリのインストールを行います。
ライブラリのインストールには先ほど使用したpipenvではなくmicropipenvを使用しています。 通常のpipenvはライブラリのインストール時に自動でPython仮想環境を作成しますが、micropipenvはコンテナでの利用を前提とし、仮想環境の作成を行わずライブラリのインストールのみを行います。 micropipenvはPipfile.lockだけでなく、Poetryが使用するpoetry.lockや、requirements.txtという複数の形式に対応しているのが特徴です。 より詳しくはGitHubや以下のブログ(英語)をご参照下さい。 developers.redhat.com
このDockerfileをPodmanでビルドします。 DockerfileとPipfile.lockがあるディレクトリで以下のコマンドを実行しましょう。
podman build . -t custom-datascience-image:pipfile
ビルドしたらQuay.ioにプッシュします。
# ログイン podman login # タグ付け podman tag custom-datascience-image:pipfile quay.io/jishikaw/custom-datascience-image:pipfile # プッシュ podman push quay.io/jishikaw/custom-datascience-image:pipfile
今回はパブリックなリポジトリにイメージを置いたためこちらからアクセスできます。 ここまででPipfileを使って依存関係を管理しながらカスタムイメージのビルドができました。
Poetryで依存関係を管理するパターン
もう一つのパターンとして既存でPoetryを使用して依存関係を管理しているパターンについても考えましょう。
この場合はPipfileに対してライブラリを追加するのではなく、Poetryのpyproject.tomlにPipfileに書かれたライブラリを追記します。
今回は下記のpyproject.tomlを作成しました。
[tool.poetry] name = "my custom notebook" version = "0.1.0" description = "my custom notebook" authors = ["jpishikawa"] [tool.poetry.dependencies] python = "~=3.9" elyra = "^3.11.0" mlflow = "^1.28.0" # 以下はPipfileから追記 # Datascience and useful extensions boto3 = "~=1.26.69" jupyter-bokeh = "~=3.0.5" elyra-python-editor-extension = "~=3.14.2" kafka-python = "~=2.0.2" matplotlib = "~=3.6.3" numpy = "~=1.24.1" pandas = "~=1.5.3" plotly = "~=5.13.0" scikit-learn = "~=1.2.1" scipy = "~=1.10.0" jupyterlab-lsp = "~=3.10.2" jupyterlab-widgets = "~=3.0.5" jupyter-resource-usage = "~=0.6.0" jupyterlab-s3-browser = "~=0.10.1" # Parent image requirements to maintain cohesion jupyterlab = "~=3.5.3" jupyter-server = "~=2.1.0" jupyter-server-proxy = "~=3.2.2" jupyter-server-terminals = "~=0.4.4" jupyterlab-git = "~=0.41.0" nbdime = "~=3.1.1" nbgitpuller = "~=1.1.1" # --- thamos = "~=1.29.1" wheel = "~=0.38.4" [tool.poetry.dev-dependencies] [build-system] requires = ["poetry-core>=1.0.0"] build-backend = "poetry.core.masonry.api"
このファイルがあるディレクトリで以下を実行しロックファイルを作成します。 作業環境にpoetryが無い場合はインストールします。
## Poetryのインストール # pip install poetry # ロックファイルの作成 poetry lock
実行すると以下が表示されロックファイルの作成が中断されました。
Updating dependencies
Resolving dependencies... (3.9s)
The current project's Python requirement (>=3.9,<4.0) is not compatible with some of the required packages Python requirement:
- scipy requires Python <3.12,>=3.8, so it will not be satisfied for Python >=3.12,<4.0
- scipy requires Python <3.12,>=3.8, so it will not be satisfied for Python >=3.12,<4.0
Because no versions of scipy match >1.10.0,<1.10.1 || >1.10.1,<1.11.0
and scipy (1.10.0) requires Python <3.12,>=3.8, scipy is forbidden.
So, because scipy (1.10.1) requires Python <3.12,>=3.8
and my custom notebook depends on scipy (~=1.10.0), version solving failed.
• Check your dependencies Python requirement: The Python requirement can be specified via the `python` or `markers` properties
For scipy, a possible solution would be to set the `python` property to ">=3.9,<3.12"
For scipy, a possible solution would be to set the `python` property to ">=3.9,<3.12"
https://python-poetry.org/docs/dependency-specification/#python-restricted-dependencies,
https://python-poetry.org/docs/dependency-specification/#using-environment-markers
どうやらscipyのバージョン1.10.0をインストールする場合、Pythonのバージョンは3.12未満であることを明記する必要があるそうです。 メッセージの内容に合わせ元のpyproject.tomlを修正します。
[tool.poetry] name = "my custom notebook" version = "0.1.0" description = "my custom notebook" authors = ["jpishikawa"] [tool.poetry.dependencies] # 変更 python = ">=3.9,<3.12" elyra = "^3.11.0" mlflow = "^1.28.0" # 以下はPipfileから追記 # Datascience and useful extensions boto3 = "~=1.26.69" jupyter-bokeh = "~=3.0.5" elyra-python-editor-extension = "~=3.14.2" kafka-python = "~=2.0.2" matplotlib = "~=3.6.3" numpy = "~=1.24.1" pandas = "~=1.5.3" plotly = "~=5.13.0" scikit-learn = "~=1.2.1" scipy = "~=1.10.0" jupyterlab-lsp = "~=3.10.2" jupyterlab-widgets = "~=3.0.5" jupyter-resource-usage = "~=0.6.0" jupyterlab-s3-browser = "~=0.10.1" # Parent image requirements to maintain cohesion jupyterlab = "~=3.5.3" jupyter-server = "~=2.1.0" jupyter-server-proxy = "~=3.2.2" jupyter-server-terminals = "~=0.4.4" jupyterlab-git = "~=0.41.0" nbdime = "~=3.1.1" nbgitpuller = "~=1.1.1" # --- thamos = "~=1.29.1" wheel = "~=0.38.4" [tool.poetry.dev-dependencies] [build-system] requires = ["poetry-core>=1.0.0"] build-backend = "poetry.core.masonry.api"
改めてpoetry lockを実行しロックファイルを作成しましょう。
私の環境では大体3分弱でpoetry.lockが作成されました。
あとはPipfileの時と同様にロックファイルをコピーしコンテナをビルドします。 micropipenvを使ってpoetry.lockからライブラリをインストールする場合、pyproject.tomlも必要になるためそちらもコピーします。
FROM quay.io/modh/odh-generic-data-science-notebook:v2
# Install Python packages and Jupyterlab extensions from poetry.lock
COPY poetry.lock pyproject.toml ./
RUN echo "Installing softwares and packages" && micropipenv install && rm -f ./poetry.lock && rm -f ./pyproject.toml
# Fix permissions to support pip in Openshift environments
RUN chmod -R g+w /opt/app-root/lib/python3.9/site-packages && \
fix-permissions /opt/app-root -P
このDockerfileを使ってビルドします。ビルドしたら先ほどと同様に Quayリポジトリにプッシュします。
podman build . -t custom-datascience-image:poetry podman tag custom-datascience-image:poetry quay.io/jishikaw/custom-datascience-image:poetry podman push quay.io/jishikaw/custom-datascience-image:poetry
これで無事コンテナイメージを作成することができました。 既にPoetryを使って依存関係の管理をしている場合はこちらの方法を取ると良いでしょう。
RHODSへのカスタムイメージの追加
ここからはRHODSのコンソールを使用し、先ほど作成したカスタムイメージをインポートします。

画面左の"Settings -> Notebook images"からインポート画面に移ります。
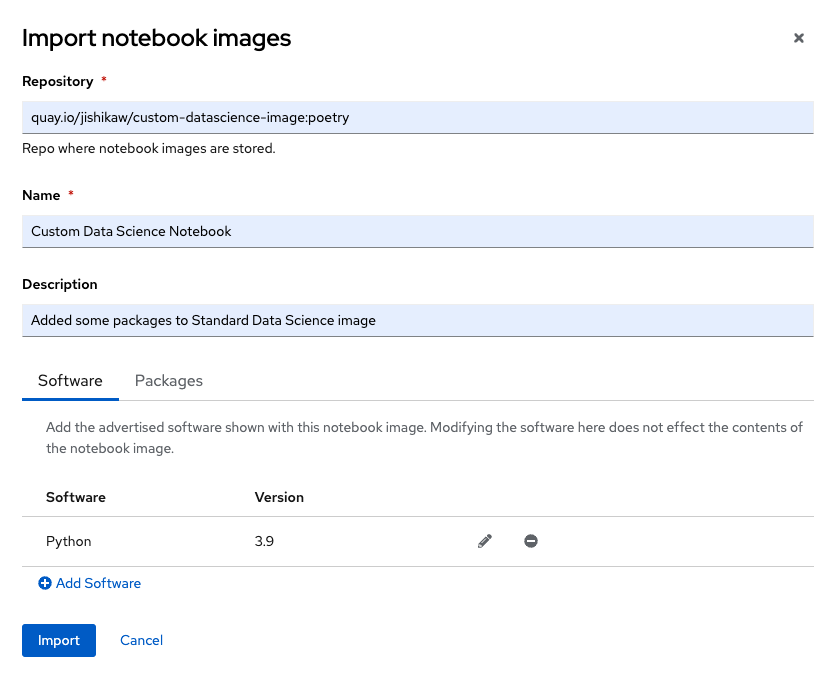 インポートするコンテナイメージの場所や、RHODS上で表示する名前、説明、含まれるパッケージ等の情報を入力していきます。
入力が完了したら"Import"を実行しましょう。
インポートするコンテナイメージの場所や、RHODS上で表示する名前、説明、含まれるパッケージ等の情報を入力していきます。
入力が完了したら"Import"を実行しましょう。

無事にインポートができました。
カスタムイメージ一覧の画面では"Enable"のトグルにより、ユーザーがNotebook作成時にこのカスタムイメージを選択できるか管理することができます。

Notebookの起動画面を見ると追加したカスタムイメージが表示されていることを確認できます。
あとはデフォルトのイメージと同様に起動するとNotebook画面が表示されます。

Notebookの自動停止
最後にRHODS上でアクティブでないNotebookの自動停止設定について見ていきたいと思います。
RHODSコンソールの"Settings -> Cluster settings"を選択すると、
"Stop idle notebooks"という項目があります。

これはアクティブでないNotebookを一定時間後に自動で停止し、Podに割り当てたリソースを回収してくれる機能です。
例えば、GPUを使った学習などを行なっている場合、なるべくGPUを稼働させておきたいため、Notebook停止までの時間を短くすることでリソースを有効に活用することが可能となります。
停止されたNotebookについても作業中のデータはアタッチされたPVに保存されるため、再度Notebookを立ち上げてもすぐに作業を再開できます。
デフォルトではオフとなっていますが上記のような場合では設定しておくとよいでしょう。
まとめ
今回はRHODSのカスタムイメージの作成や、そのインポート等についてご紹介しました。 Pythonでは他の言語と異なり依存関係の管理について色々なやり方があり、慣れないと大変な面もありますが、今回の内容を参考に是非カスタムイメージ作成にチャレンジしてみて下さい。
また今回の記事で作成したファイルはこちらに置いています。
- 今回ご紹介する方法はあくまで参考となります。カスタムイメージの作成は利用者自身の責任となるため予めご了承下さい。↩