みなさんこんにちは、レッドハットでソリューションアーキテクトをしている暮林といいます。
SREのためのMetrics-driven transformation(MDT) というタイトルで数回の連載をしたいと思います。
Metrics-driven transformationとは?
聞き慣れない方が多いかと思いますがこちらに英語の短いビデオがあって説明されています。
このビデオでは、Digital TransformationのためにDevOpsをするぞ!となっても、いざやってみると何をどうかえていけばわからないという問題に直面するよね、ということを述べた後に、では組織として計測するべきKPIは何でしょう?というところを少しだけ語って終わってしまいます。
計測すべきKPIについては少し先で解説しますが、そもそもなんのためにKPIを計測するのか?ということを紐解くと、ビデオの登場者はこういうことであるといっています。
- MetricsはPractice(習慣の意味が近い)に情報を与える (さもなくばどうやってPracticeを評価するのか?)
- PracticeはCultureを変化させる(Cultureはトップダウンでは変化させられない)
- Cultureの変化がTransformationをUnlockする
きれいかつ少々強引とも言える3段論法ですが、もし自分の所属している組織の文化改革はむずかしい!と考えている方がいらっしゃるのであれば、まずは数値として組織の状態を計測するところから始める、ということを頭の片隅においてみてください。(ダイエットの開始も体重を測るところからですよね!?)
Pelorusとは
PelorusはKonveyerのProjectの1つで、Kubernetes上でのSoftware Delivery Performanceを計測するためのツールです。
本連載では「SREのための」と銘打ってますが、本来の意味でPelorusが目指すのは組織全体のTransformationの可視化なので、SRE組織に限定せず経営可視化用のダッシュボードを目指しています。
PelorusのダッシュボードはCloud Native界隈では有名なGrafanaを用いており、下記のような姿をしています。
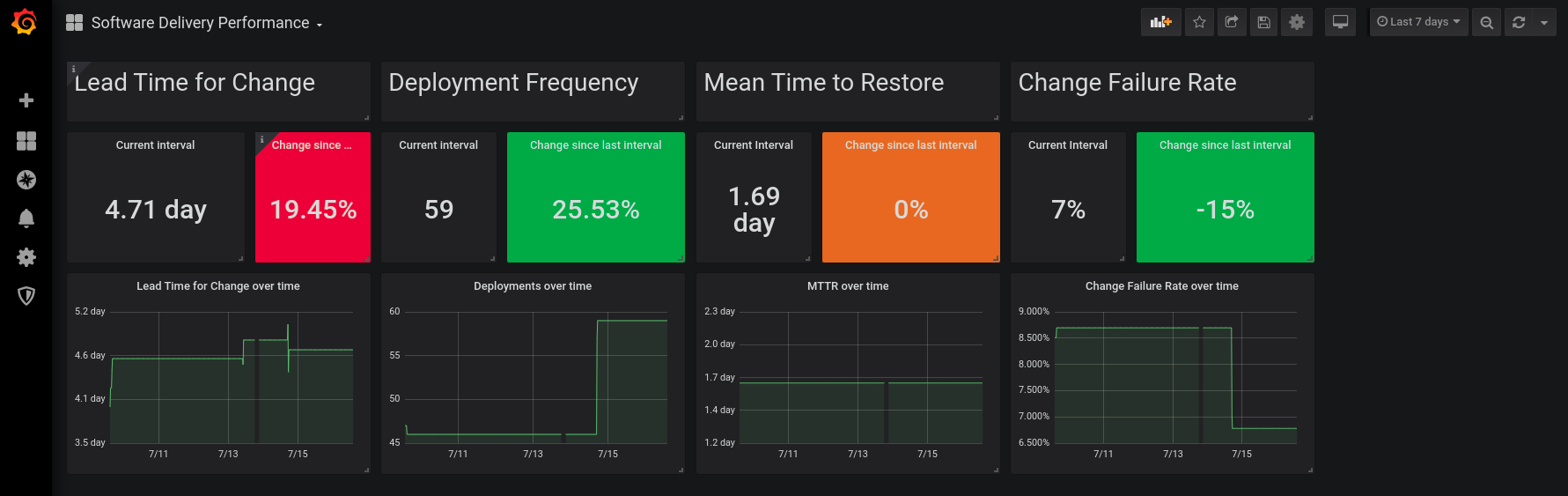
PelorusがKPIとしている数値は以下の4つです。
- Lead Time for Change
- Deploy Frequency
- Mean Time to Restore
- Change Failure Rate
ここで思い出していただきたいのはSREの本来の役割です。SREは経営に対して約束したSLAを維持しつつ、Error Buggetの消費を極力抑えながら高速Deploymentを行い続ける集団です。従来の分業体制ではSLAを維持する係とDeploymentを行う係は分業されており、両者には利害関係が発生するためSLAの維持と高速Deploymentは相反する要素になってしまっていました(OpsのSLAがDevのDeploymentを阻害する)。これを解決していく考え方がSREです。
SREについてはちょっとしたまとめが下記のサイトにあります。ここで登場するSLI(サービスレベルインジゲーター)の役割の一部を担うのがPelorusです。
Pelorusのアーキテクチャー
Pelorusのアーキテクチャーは下記のドキュメントで解説されています。
Pelorusが主に利用しているのは、Grafana、Prometheus、Thanosの3つですが、このなかではThanosに聞き覚えがない方が多いと思います。
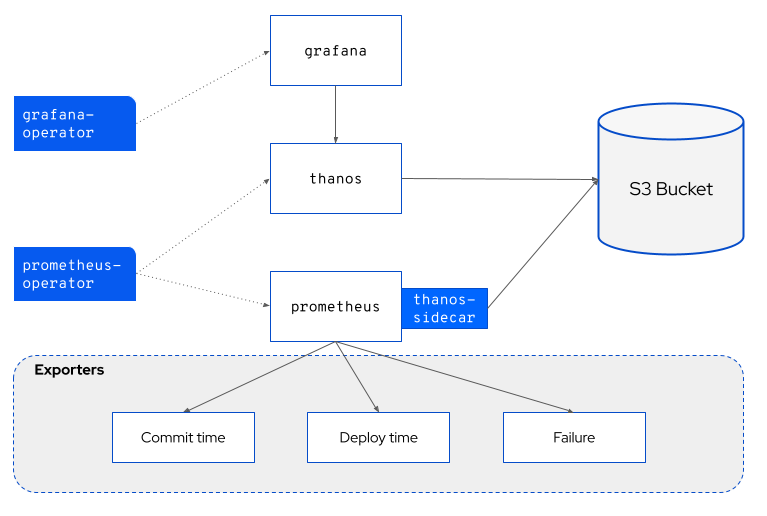
ThanosはCNCFのIncubation ProjectでPrometheusするMetricsを収集するための高可用性メトリックシステムのコンポーネントです。
Thanosのアーキテクチャーもなかなか興味を惹かれる部分ではありますが、一旦脇において話をすすめていきましょう。
Pelorusのインストール
Pelorusのインストールには以下の条件が必要です。
- OpenShift 3.11 以上の環境
- インストールを行えるPC
- OpenShift Command Line Tool (oc)
- Helm3
- jq
- git
これらに加えて、Software Delivery PerformanceをGithubやJiraから取得する場合は、それらのAccess Tokenが必要になります。
次回予告
次回は実際のOpenShift環境でPerolusをインストールして、下記の簡単なデモの様子をみていきます。
このデモでは、Pelorusがアプリケーションの配信サイクルを通じてどのように変更を捉えていくするかを見ることができます。
- Pelorusを初期化すると、既存の保存されたデータを確認してベースラインが設定されます
- デモスクリプトを実行すると、パイプラインを実行するための新しいコミットが作成されます
- 新しいバージョンが公開されるたびに、MetricsとTrendが変化するのを見てください
次回につづく