みなさん、こんにちは。 Red HatでOpenShiftのソリューションアーキテクトをしている小野です。
主にエッジコンピューティングを推進しています。
今回は、エッジデバイスへOpenShiftをインストールする 「MicroShift」をご紹介します。
MicroShiftとは
MicroShiftは、エッジデバイスでOpenShiftを利用できる様にOpenShiftをRe-パッケージしたソフトウェアです。 Red HatのCTOオフィスのEdge Computingチームにより推進される実験プロジェクトとして、開発が進められています。
Red Hat Enterprise Linux (RHEL)がインストールされたエッジデバイスに、オプションでデプロイできるアプリケーションを目指しており、 MicroShiftのライフサイクルは、OSのライフサイクルから切り離されています。

MicroShiftは現状、実験プロジェクトということで、製品化されておらず、オープンソースとして公開されています。 5月に開催されたRed Hat Summit 2022にて、2022年末にリリース予定のOpenShift 4.12より、Early Access Program(※1)として利用可能とする計画が発表されました。(※1)Red Hat Cloud Suite Early Access Support Policies - Red Hat Customer Portal
エッジデバイスとは
エッジデバイスとは、フィールドに大量に展開されるデバイスを指します。
例えば、
- POSやKIOSK端末
- 自動運転のAIを実行する車両内の小型デバイス
- 工場のラインに設置される産業用のPC
- 遠隔地の石油やガスプラントを監視し予知保全を実行するデバイス
- 衛星に搭載されるデバイス
など、別の言い方で「組み込みシステム」とも呼ばれます。
フィールドに展開される、ということで、エッジデバイスは、通常、電力とネットワークが安定しているデータセンタとは全く異なる環境に設置されます。 MicroShiftは、特にネットワーク環境が貧弱、またはネットワーク未接続で、遠隔管理・制御が難しい場所に大量展開されるデバイスもスコープにしています。
衛星といえば、先日、IBM / Red Hatの衛星エッジコンピューティングのプロジェクトがプレスリリースされました。
記事に記載されている取り組み内容をざっくり言うと、
- IBM Cloudに開発ポータルを構築
- 開発ポータルにPythonコードをプッシュ
- 脆弱性スキャンの後、地上局経由で衛星上で稼働するコンピュータへコードを展開・実行
というもので、衛星の磁力計、太陽センサー、電圧、温度などのテレメトリデータの取得や、衛星のカメラを使用して地球の写真を撮る、といったユースケースを目指しています。 この「衛星上で稼働するコンピュータ」に、本稿でご紹介するMicroShiftが使われています。

どの辺が "Micro" なの?
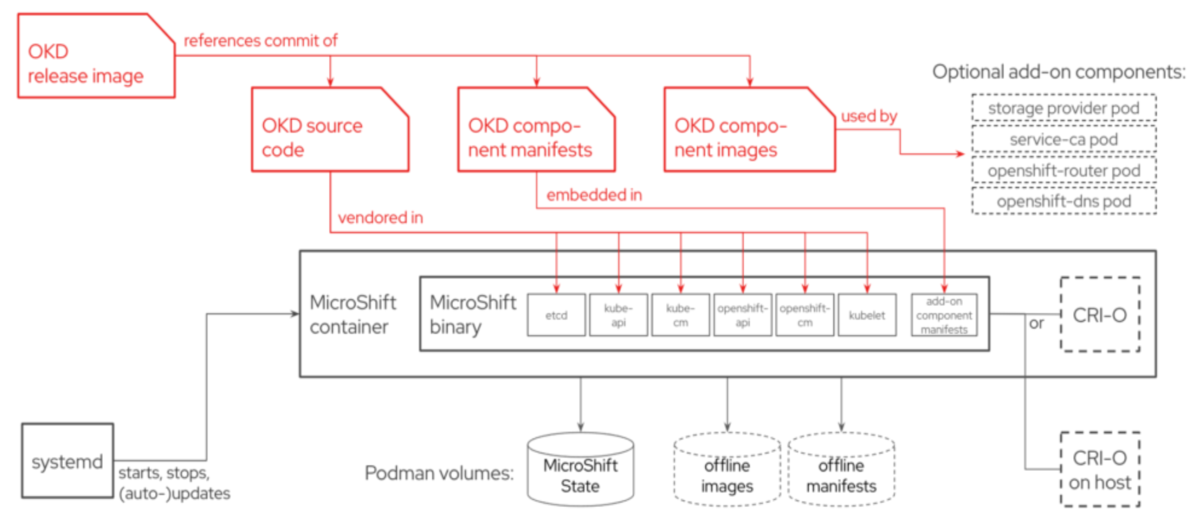
MicroShitは、OpenShiftのコアコンポーネント(※2)をバイナリサイズ160MB程度までダウンサイジングし、シングルバイナリかつsystemdでライフサイクル管理する、モノリスなOpenShiftとして実装されています。(※2)etcd、kube-apiserver、kube-controller-manager、kube-scheduler、openshift-apiserver、openshift-controller-manager
これだけだと、オープンソースのKubernetesと変わりありませんので、OpenShiftのコンポーネントをいくつかアドオンの形で展開できるようになっています。
現状だと、openshift-dns、openshift-ingress、service-ca、local-storage-provisionerがインストール時にデフォルトで展開されます。
OpenShiftのコアコンポーネントがシングルバイナリで提供されることによって、更新やロールバックなどの変更オペレーションを大幅に簡素化できるようになります。 そして、変更オペレーションに伴うコンポーネント間のオーケストレーションが不要となることで、OpenShiftクラスタを管理するCluster Operatorを削除でき、フットプリントの大幅な削減に成功しています。ただし、Cluster Operatorが使えないとなると、MicroShiftの想定するパラメーターの範囲外で設定が必要になった場合に、手動での構成が必要になるというデメリットも伴います。
エッジデバイスでKubernetesを使うことのメリット
エッジデバイスとサーバのプロビジョニングフローの違い
エッジデバイスは、多くの場合、以下のプロビジョニングフローで現場へ設置されます。
- メーカーやエンドユーザの開発・運用拠点などで一元的にキッティング
- 現場へ出荷
- 現場の担当者が、デバイスを設置
- 現場の担当者が電源ケーブルとLANケーブル挿入、電源ON・ネットワーク設定
この辺のプロビジョニングフローは、FIDOアライアンスが策定したFIDO Device Onboarding (FDO) 仕様が参考になります。
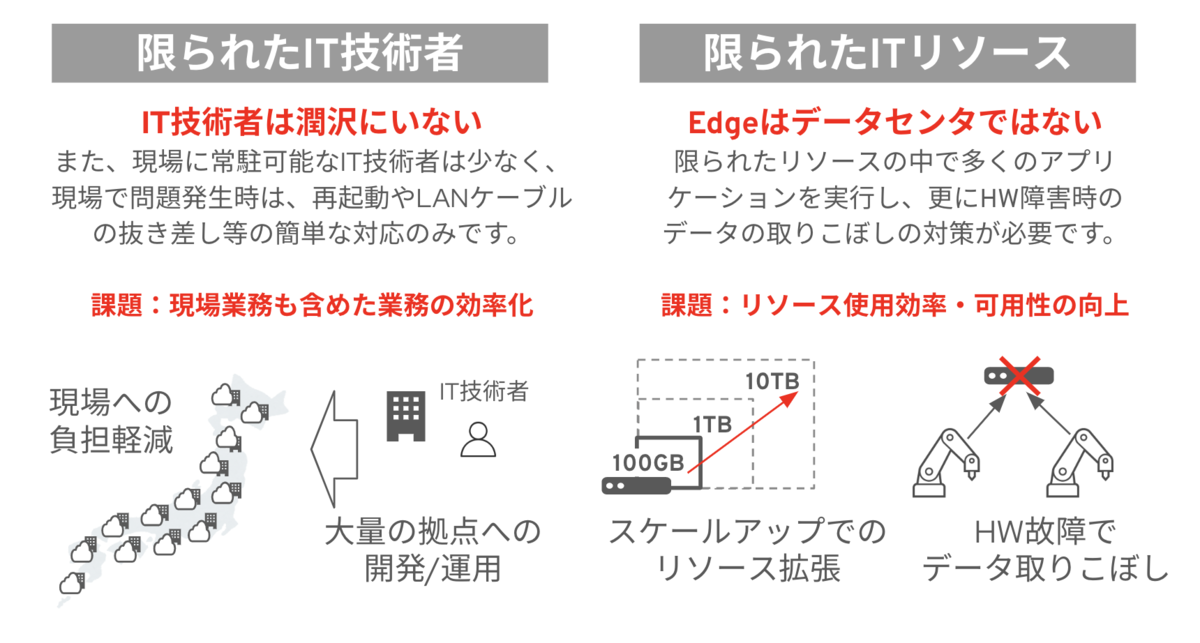
多くの場合、現場にIT技術者はいません。 データセンタへのサーバのプロビジョニングフローとは全く異なる、という点がポイントになります。
エッジのスケール時の課題
ところで最近、AIカメラなど、エッジデバイス上でAIを実行する「エッジAI」が流行しています。 このエッジAIを例にしても、エッジコンピューティングの事例として、従来サーバサイドで実行されていたAIなどのアプリケーションをエッジデバイス上で実行する、という動向が見受けられます。
プロビジョニングフローを踏まえると、エッジデバイスのスケールに対応する際、下記が課題となります。
- 大量のエッジデバイスのプロビジョニングの効率化
- 大量のエッジデバイスへサーバサイド・アプリケーションの実行環境の構築の効率化
- サーバサイド・アプリケーションのプロビジョニングの効率化
- 現場へエッジデバイスを設置した後のサーバサイド・アプリケーションの変更や機能追加の効率化
「小さいクラウドの自動生産ライン」を作る必要があると言えると思います。
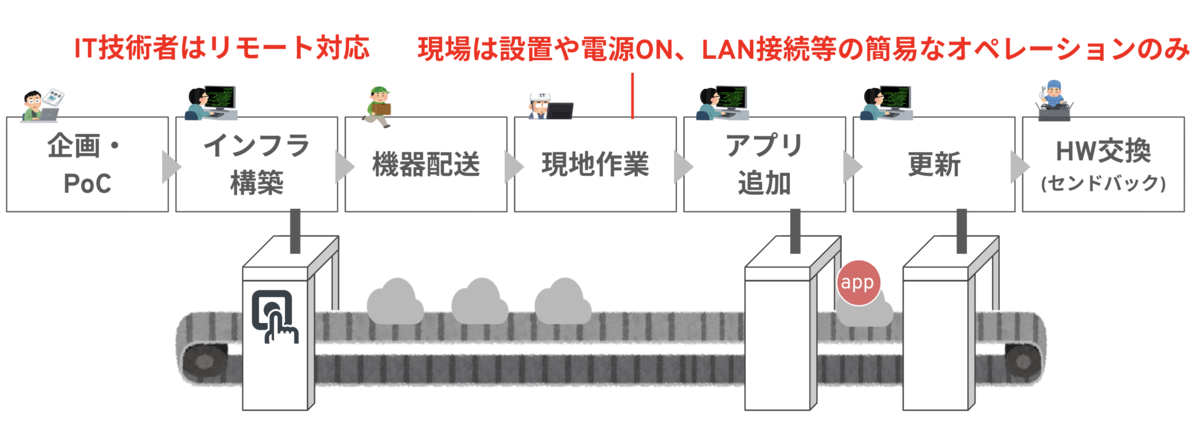
現場業務の簡素化とIT技術者によるエッジデバイスのプロビジョニング・運用効率化が、エッジのスケールに対応する上で重要な課題となります。
また、IoTの進展に伴い、センサーから生成されるデータをクラウドへ送る手前でエッジデバイスへ一次集約し、分析やAIの実行に活用するという事例が増えています。エッジデバイスは基本的にハードウェアとアプリケーションが密結合したパッケージとして現場へ配布されます。したがって、エッジデバイスのローカルディスクの容量が不足したり、エッジデバイスのハードウェアが故障すると、データの取りこぼしが起こり得ます。 PoCの段階では大きな問題にならなくても、データ・ドリブンでの意思決定の重要度が増す程、データ損失による業務破綻のリスクが高まってきます。
その様な背景から、エッジデバイスを複数台用意してスケーラビリティを向上させたい、ハードウェアを冗長化させたい、といったデータ収集の可用性向上に向けた課題も重要になってきます。
Kubernetesがエッジにもたらす価値
2021年にSlash Dataは、Cloud Native Computing Foundation(CNCF)の依頼を受け作成した「State of Cloud Native Development Report」というレポートを公開しました。 7000人のバックエンド開発者を対象に、Kubernetesとコンテナーに関する認識や利用形態の調査結果がまとめられています。
このレポートによると、Kubernetesはエッジコンピューティングの開発者による利用傾向が最も高い、というデータが出ています。
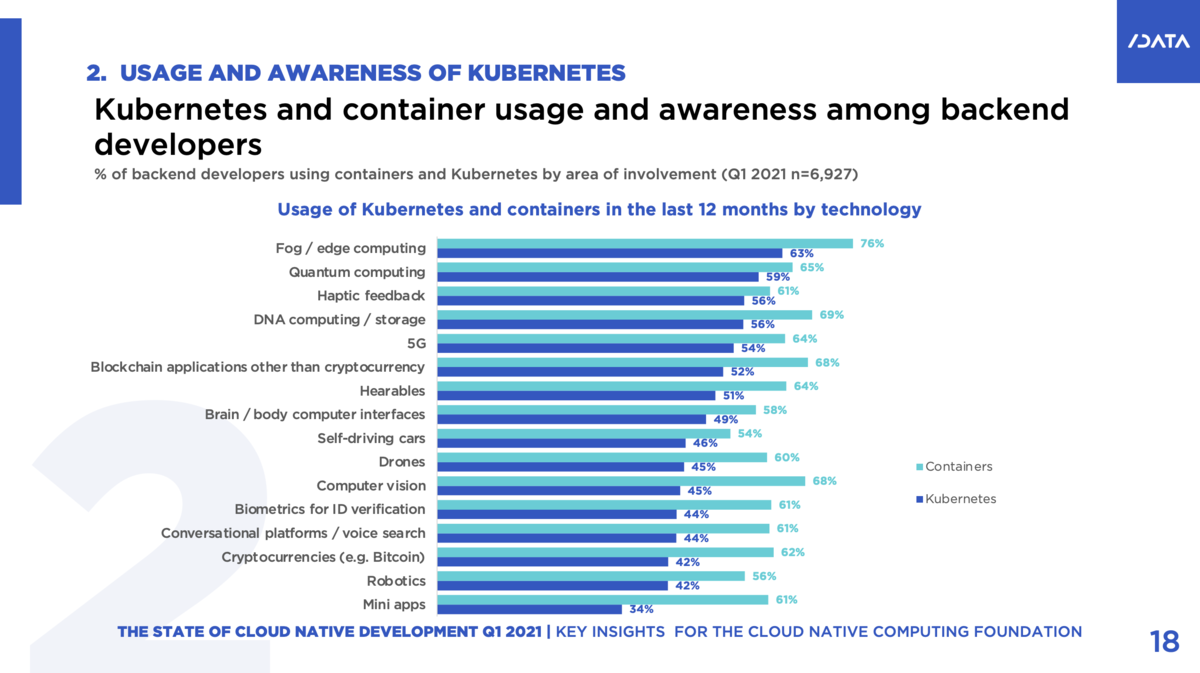
https://www.cncf.io/wp-content/uploads/2021/12/Q1-2021-State-of-Cloud-Native-development-FINAL.pdf
Kubernetesは、ITインフラストラクチャやアプリケーションの管理において強力な自動化機能を有し、複数台のノードでクラスタを構成することで、インフラストラクチャの可用性と拡張性の柔軟性を向上できるプラットフォームとして活用されています。この「自動化」と「可用性・拡張性の柔軟性」という点で、エッジコンピューティングの課題との親和性が高く、期待値として表れていると考えます。
MicroShiftは、正にその様な期待に応えるために開発されたエッジコンピューティングに最適化されたOpenShiftです。 マルチノードなど、まだまだ機能改善が図られているソフトウェアですが、クラウドとエッジで同じ運用モデルを適用できる様になることで、End-to-Endの業務の自動化を推進できます。
例えばOpenShiftの様に、Red Hat Advanced Cluster Management(RHACM)を用いて、MicroShiftがインストールされたエッジデバイスをクラスタとして管理でき、RHACMを単一のコントロールプレーンとして、Zero Touch Provisioningによりクラスタやアプリケーションを自動生産、かつセキュリティポリシを一括適用するといった運用が可能になります。

例えば、以下の様に、Tektonを用いたエッジ環境のプロビジョニング自動化の事例が存在します。
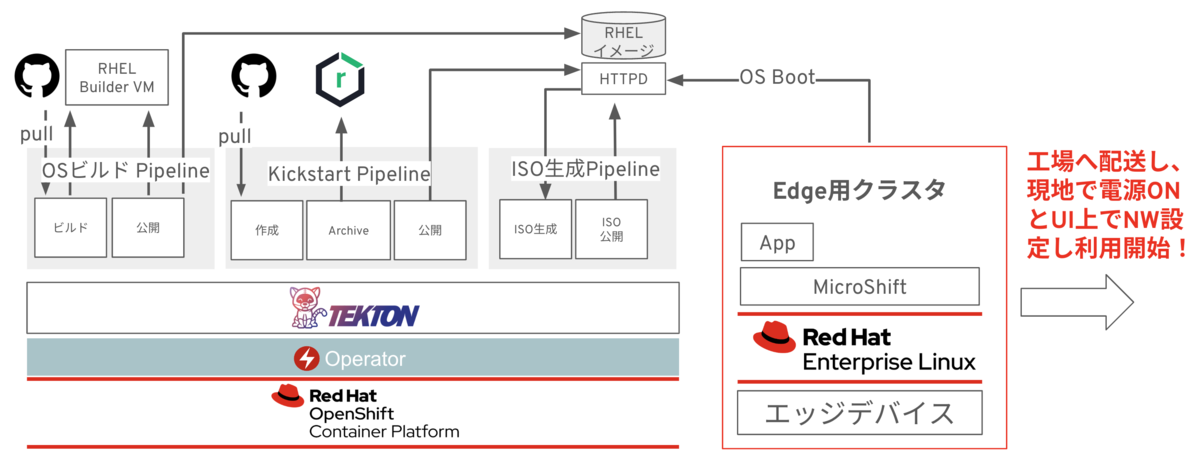
MicroShiftのインストール
それでは、MicroShiftを試しにインストールして触ってみましょう。 MicroShiftは、ホスト上で直接実行するか、Podman上でコンテナとして展開できます。 ここでは、PC上にFedoraの仮想マシンを実行し、仮想マシン上でMicroShiftを実行してみたいと思います。
MicroShiftの動作環境
ハードウェア要件:
- CPU: x86/64 / AMD64 / ARM64
- Red Hat Enterprise Linux 8.6以降
必要最低限のスペック:
- CPUコア数: 2 コア
- メモリ: 2GB
- DISK: 1GB
インストール
お手持ちのPCへVagrantをインストールします。 Vagrantのインストール方法は公式ドキュメントを参考にしてください。
以下のVagrantfileを作成します。
Vagrant.configure("2") do |config|
config.vm.box = "fedora/35-cloud-base"
config.vm.provider "virtualbox" do |v|
v.memory = 4096 # 4GB
v.cpus = 2 # 2コア
end
# localhostからアクセスできる様にポートフォワードしておく
config.vm.network :forwarded_port, guest: 6443, host: 6443, id: "console"
config.vm.network :forwarded_port, guest: 443, host: 443, id: "console"
config.vm.network :forwarded_port, guest: 80, host: 80, id: "console"
config.vm.network :forwarded_port, guest: 22, host: 22, id: "ssh"
# 任意のドメインを指定
config.vm.hostname = 'microshift.local.com'
config.vm.provision "shell", inline: <<-SHELL
dnf module list cri-o
dnf -y module enable cri-o:1.22
dnf -y install cri-o
curl https://copr.fedorainfracloud.org/coprs/g/redhat-et/microshift-nightly/repo/fedora-34/group_redhat-et-microshift-nightly-fedora-34.repo -o /etc/yum.repos.d/microshift-nightly-fedora34.repo 2>/dev/null
cat << EOF > /etc/cni/net.d/100-crio-bridge.conf
{
"cniVersion": "0.4.0",
"name": "crio",
"type": "bridge",
"bridge": "cni0",
"isGateway": true,
"ipMasq": true,
"hairpinMode": true,
"ipam": {
"type": "host-local",
"routes": [
{ "dst": "0.0.0.0/0" }
],
"ranges": [
[{ "subnet": "10.42.0.0/24" }]
]
}
}
EOF
dnf install -y microshift
hostnamectl set-hostname microshift.local.com
dnf -y install firewalld wget
systemctl enable firewalld --now
firewall-cmd --zone=public --permanent --add-port=6443/tcp
firewall-cmd --zone=public --permanent --add-port=30000-32767/tcp
firewall-cmd --zone=public --permanent --add-port=2379-2380/tcp
firewall-cmd --zone=public --add-masquerade --permanent
firewall-cmd --zone=public --add-port=80/tcp --permanent
firewall-cmd --zone=public --add-port=443/tcp --permanent
firewall-cmd --zone=public --add-port=10250/tcp --permanent
firewall-cmd --zone=public --add-port=10251/tcp --permanent
firewall-cmd --permanent --zone=trusted --add-source=10.42.0.0/16
firewall-cmd --reload
firewall-cmd --permanent --change-zone=eth0 --zone=public
systemctl enable crio
systemctl start crio
systemctl enable microshift
systemctl start microshift
ARCH=x86_64
wget -q https://mirror.openshift.com/pub/openshift-v4/$ARCH/clients/ocp/candidate/openshift-client-linux.tar.gz
mkdir tmp;cd tmp
tar -zxvf ../openshift-client-linux.tar.gz
mv -f oc /usr/local/bin
cd ..;rm -rf tmp
rm -f openshift-client-linux.tar.gz
echo "export KUBECONFIG=/var/lib/microshift/resources/kubeadmin/kubeconfig" >> /root/.bash_profile
SHELL
end
vagrantコマンドで仮想マシンを起動すると、自動でMicroShiftもインストールされます。
$ vagrant status Current machine states: default not created (virtualbox) $ vagrant up $ vagrant status Current machine states: default running (virtualbox)
MicroShiftの動作確認
KubeconfigをローカルPCにコピーし、ocコマンドでAPIを実行してみます。
$ ssh vagrant@localhost sudo cat /var/lib/microshift/resources/kubeadmin/kubeconfig > ./kubeconfig-mac $ oc --kubeconfig=./kubeconfig-mac get nodes NAME STATUS ROLES AGE VERSION microshift.local.com Ready <none> 111d v1.21.0 $ oc --kubeconfig=./kubeconfig-mac get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system kube-flannel-ds-24jwq 1/1 Running 2 111d kubevirt-hostpath-provisioner kubevirt-hostpath-provisioner-g9678 1/1 Running 2 111d openshift-dns dns-default-h74m9 2/2 Running 4 111d openshift-dns node-resolver-w2hs8 1/1 Running 2 111d openshift-ingress router-default-6c96f6bc66-m8btk 1/1 Running 2 111d openshift-service-ca service-ca-7bffb6f6bf-km6wq 1/1 Running 2 111d
まとめ
今回は、エッジデバイスへOpenShiftをインストールできるMicroShiftをご紹介しました。
エッジデバイスでもKubernetesを活用し、エッジのスケールに対応していきましょう!