こんにちは、レッドハットサポートのクリスです。この記事の英語版があります。
前回の記事の続きになります。今回も、システム2台があります:
- 測定用の制御システム
- 消費電力を測定しながらワークロードを実行するシスU(System Under Test, SUT)
SUTはpmcdとpmda-denkiを実行し、測定データを提供する。SUTはpmcdとpmda-denkiを実行してメトリクデータを提供し、制御システムはPCPを実行してデータを収集し、後で計算するためにアーカイブファイルに保存します。Ansible playbookを使って、両方のシステムに必要なパッケージをインストールする。
このセットアップを使用して、さまざまなLinuxシステムがどれだけ速く計算タスクを実行できるか、また、どれだけエネルギー効率よくタスクを実行できるかを比較する。もしかしたら、遅いシステムの方がエネルギー効率が高いかもしれない。
今回の用語:
- 電力とは、ある時点で消費されるエネルギーのことで、単位はワットまたはVAである。例えば、「このシステムは現在20ワットを消費している」ということ です。
- エネルギーは「時間経過に伴う電力」であり、ある時間スで使用されるエネルギー量です。例えば、ワット時(英文:Watthour)またはジュール(Joule)で測定されます。
pmda-denkiの電力関連のメトリクスを簡単にまとめます:
- RAPL: x86システム上で、CPU、RAM、オンボードGPUによって消費される電力を提供します
- 電池: 電池の放電を監視することで消費電力を計算します
- スマートプラグ: ネットワーク/APIを使って、消費電力を測定する機能を持つデバイス。この記事では、Tasmotaファームウェアを搭載したSwitchBotスマートプラグを使用する。代わりに他の多くのデバイスを使用することができる。
テストに最適なワークロードを探そう
この記事では、作業負荷の例を使用し、複数のシステムを比較しながら消費/エネルギー効率を測定する。例えば、SPEC ベンチマーク・スイートを実行したら、非常に時間がかかる。特に、ARM や RISC-V CPU の小型システムでも測定したいので、もっと軽い負荷を探そう。
システムに接続されたストレージへのI/Oを比較する代わりに、CPUとメモリ操作に焦点を当てる。そのために、僕は「一つの用事を何回も実行する」事に決めました。例えば、10分の間、以前圧縮したファイルを何回も解凍する。解凍の頻度やかかった電気量を測定する。この記事では、ファイルを解凍する操作:
bzcat httpd-2.4.57.tar.bz2 >/dev/null
それを一つか複数のスレッドで実行すると、スレッドをそれぞれのCPUコアに分散させることができる。終了してから、それぞれのコアで実行したコマンドの回数を数える。その後、10分間で消費された電力を調べ、1回の解凍でシステムが消費したエネルギーを計算することができます。圧縮されたファイルはメモリーに保存され、解凍されたデータは/dev/nullに送られ、ストレージサブシステムからの影響を減らします。
計算ジョブの基本的な流れは以下の通り:
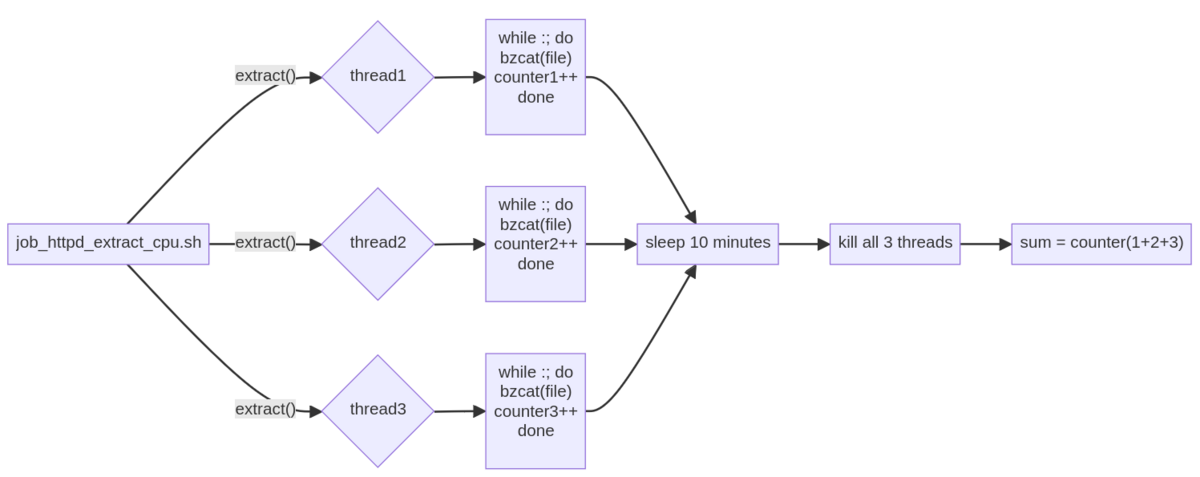
フローは左から始まり、job_httpd_extract_cpu.sh スクリプトが実行される。スクリプトでは、関数 extract() が 3 回実行され、3つのスレッドを生成される。これらのスレッドはそれぞれ、ファイルを解凍し、終了した解凍の回数を計算する。これらのスレッドはバックグラウンドで実行され、もともとのスレッドが実行されている間、「sleep 10分間」と実行する。その後、スレッドが終了し、成功した解凍ジョブの全体数が計算されます。PCPから電力メトリクスを読んだ後、エネルギー消費と効率を計算することができます。
正当な結果を得るために、テスト・ジョブはどれくらいの実行時間すればいいのか?
ファイルの解凍というワークロードを決定した。正当な結果を得るためには、消費電力を測定しながら、どれくらいの時間、連続的に解凍を行う必要があるでしょうか?
例えば、ファイルの解凍に60秒かかるのであれば、30秒だけジョブを実行しても結果はでません。しかし、連続解凍ジョブを5分間実行したとしても、その結果は複数回の実行でどの程度異なるのだろうか?意味のある結果を得るためには、2分か2時間か実行する必要があるのでしょうか?
次のグラフでは、あるジョブが例えば60秒間実行され、そのジョブは4つのスレッドを起動し、それぞれがループ内で可能な限り多くのファイル解凍を実行した。左側では、ジョブをわずか3秒間実行しただけで、複数の実行の間に大きな違いが見られます。右側の60秒の実行時間では、測定された消費量は複数の実行の間で安定している。紫色のマークはRAPL("Running Average Power Limit")の測定値で、CPUとメモリの消費量を測定している。紫色のマークは、電池のマークより安定です。このデータは、Steam Deckというシステムで測定したものです。
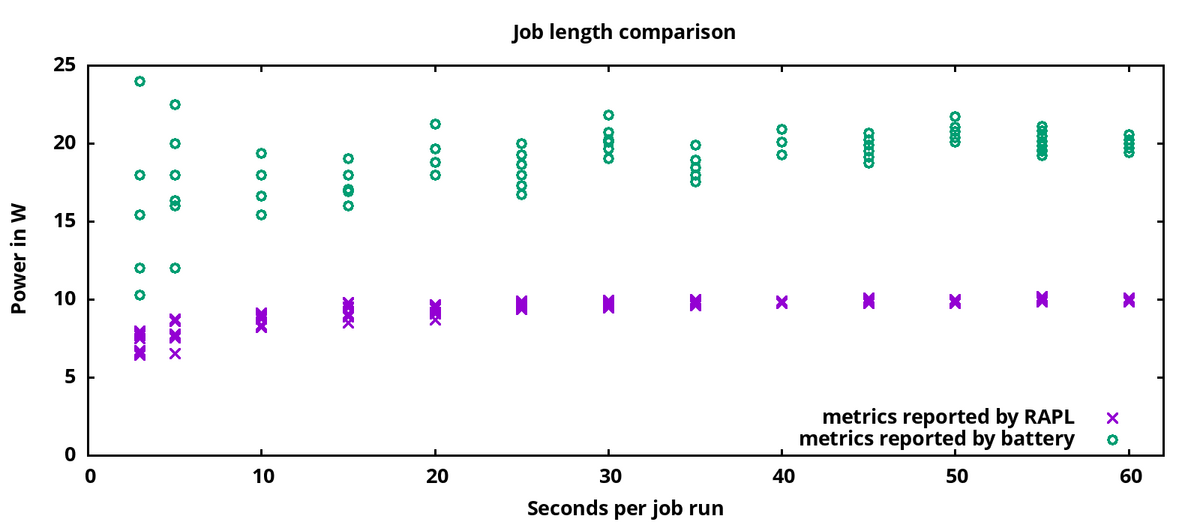
これらの結果に基づき、私は以下のテストのほとんどを10分間実行することを決めました。
smartplugのどの電力メトリクスが正しいのか?
RAPLと電池は単純のメトリクスになるので、使いやすい。それに対して、タスモタ・パワープラグは複数のメトリクスが出る:
$ http://192.168.0.2/cm?cmnd=Status%208
{
"StatusSNS": {
"Time": "2024-02-12T10:28:25",
"ENERGY": {
"TotalStartTime": "2023-10-27T13:19:18",
"Total": 12.599,
"Yesterday": 0.015,
"Today": 0.006,
"Power": 3,
"ApparentPower": 4,
"ReactivePower": 3,
"Factor": 0.67,
"Voltage": 101,
"Current": 0.037
}
}
}
上記の出力されたデータで、4つのメトリクスが読める:
- Power (電力)
- ApparentPower
- ReactivePower
- 「電圧」と「電流」の乗算
最初の3つはスマートプラグから読める。4番目は電圧と電流から計算されます。どれが正しいのか?その答えを見つけるために、私はワークロードを実行して、上記の4つのメトリクスとRAPLと電池のメトリクスを比較しました。Thinkpad L480システムで測ったデータを図形にして:
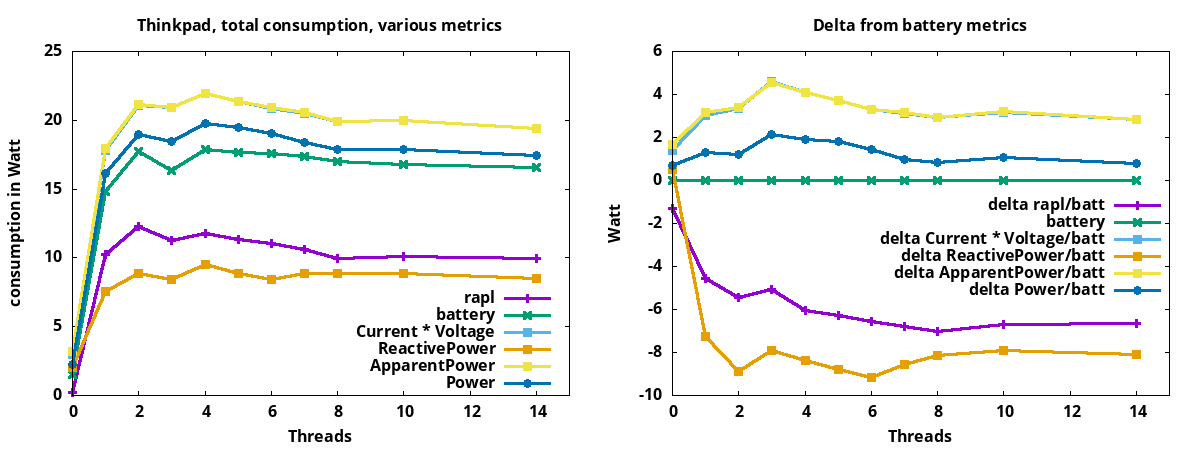
左のグラフでは、システムが使っている消費電力を示しています。それぞれのメトリクスは違うデータを流出するのは見えます。左のグラフでは、スレッドが「0」の場合、システムはアイドル状態ですが、電力を使っています。3スレッドの場合、システムの消費電力は2スレッドの場合よりもわずかに少なくなっています。グラフには示していないが、CPUのクロック速度を並行して見ると、負荷が1つまたは2つのコアの場合、Intel Turbo BoostでCPUのクロックは3.4Ghzであることがわかる。3スレッド以上の場合、CPUのクロックは3.2Ghzまたは3Ghzとなり、消費電力も若干少なくなります。代替、電池のメトリクスは一番安定だ。
右のグラフは電池を「0」にして、他のメトリクスとの違えを示しています。ここでは、Tasmotaスマートプラグからの「Power」メトリクスが、電池メトリクスに最も類似したメトリクスであることが分かる。
最もエネルギー効率の高いシステムは?
様々なアーキテクチャでジョブを実行してみましょう!
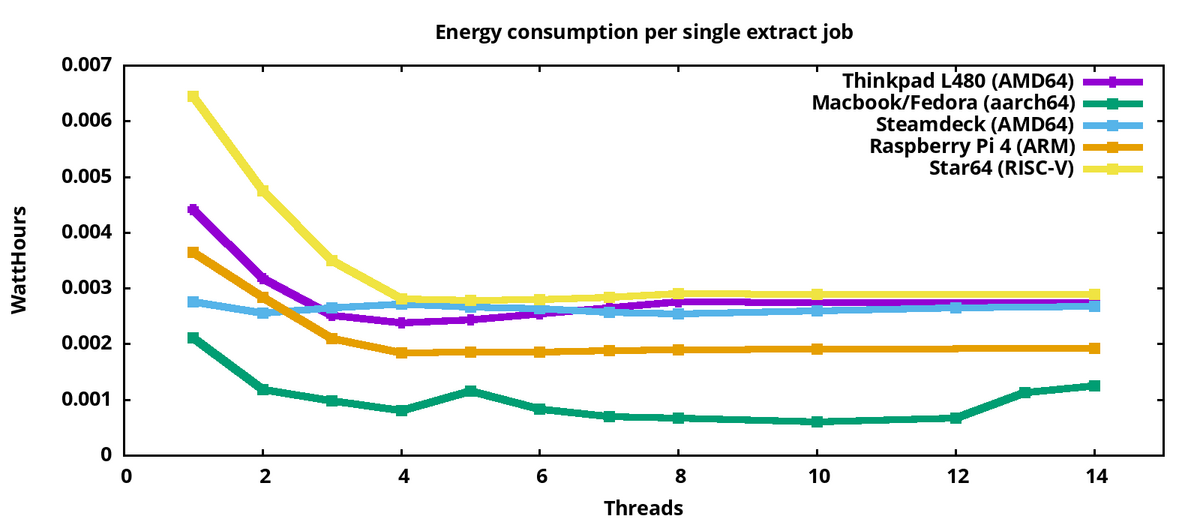
このグラフは、各システムが1回の解凍ジョブで使っているエネルギー消費を示している。システムの詳細:
- Thinkpad L480、アーキテクチャx86_64、2018年から販売するモデル。第8世代インテルi5-8250U CPU(14nm)、ハイパースレッディングなしの4コア。このシステムでは、消費電力を測定するための3つのメトリクスすべてが使用可能である。
- Macbook pro Asahi Fedora remix、10コアのAppleSilicon M2 CPU(5nm)、aarch64、2023年のモデル。コア数が多いため、最大10スレッドを別々のコアで実行できる。
- Steam Deck、これは4コア/8スレッドのAMD製CPU(7nm)、2022年にリリースした。
- Raspberry Pi 4、4コア(16nm)のaarch64システム、2019年発売
- Star 64、4コアのRISC-Vシステム、2023年発売
すべてのシステムには複数のコアがある。すべてのシステムにおいて、使用するコアが増えると、ジョブあたりの消費量は減少する。負荷が3コア以上になると、Raspi4は調査したインテル・システムよりもジョブあたりの効率が高くなる。LinuxカーネルのApple Siliconのサポートが比較的新しいのに、今回の解凍ジョブでは、Macbookのエネルギー効率は最高でした。カーネルのStar64/RISC-Vのサポートもかなりに新しい。
総消費電力
SUTの総消費電力の比較:
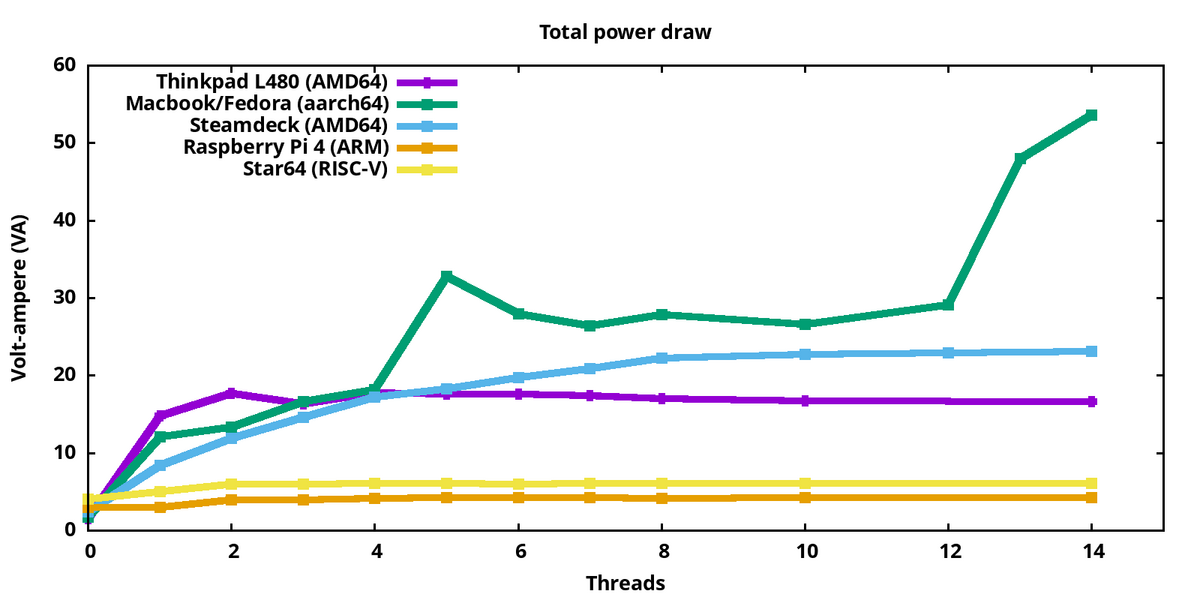
左側は、実行のジョブが0の状態で、システムがアイドルの状態である。Macbookはアイドリング状態ではそれほど消費しておらず、負荷が入ると54Wになる。
次のグラフは、各システムが実行した1秒あたりの解凍ジョブの総数:
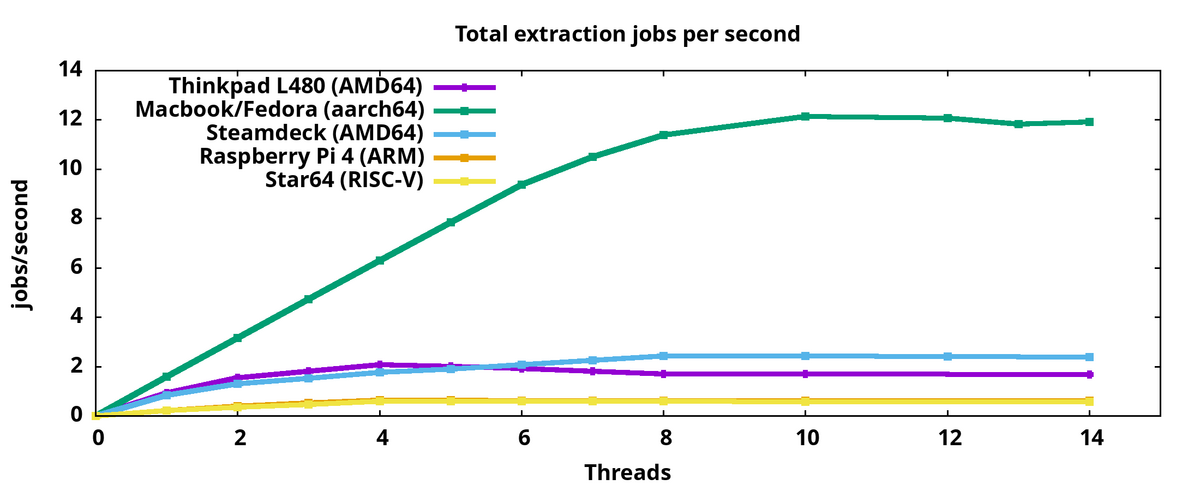
ほとんどのシステムは4コアなので、スレッド数を4まで増やすと解凍ジョブ数が増える。Macbookは10コアなので、10並列スレッドまで解凍ジョブ数が増えていることが分かります。Raspi4とStar64の1秒あたりの解凍ジョブ数はほぼ同じなので、両者の図形はほぼ重なっている。
まとめ
ある計算ジョブに対するさまざまなシステムのエネルギー効率を比較した。他の作業負荷を使うと、結果も異なる可能性が高い。ここで使用した方法により、いくつかの他の調査もできる。例えば:
- 顧客のアプリケーション/ワークロードにとって最もエネルギー効率の高いシステムは?
- 「powertop」を使うと、システムのエネルギー効率にどのような影響を与えますか?
- Spectre/Meltdownのような回避策がエネルギー効率に与える影響は?
- ハイパースレッディングは、ワークロードの性能とエネルギー効率にどのような影響を与えているか?
テストスクリプトを編集したら、CPUコアのクロック速度を追加記録することもできる。このようなプロジェクトを立ち上げ、より多くのスクリプトと計算ジョブを収集し、さまざまなシステムから測定結果を収集することも検討する。
PCPやpmda-denkiはRHELの一部であり、RHEL製品のサポート範囲内である。今回の測定データやスクリプトはここのリポジトリのdenki-jobrunnerディレクトリにあります。そのスクリプトはレッドハットサポートの範囲に入っています。グラフの元となった生データもレポにあります。
この記事をレビューし、協力してくれたレッドハットのTAMやスペシャリストの仲間に感謝している。 巨人の肩の上に立っています。