クラウドインフラ全般を担当しているソリューションアーキテクトの伊藤です。
Red Hat OpenShift Platform(OCP)の今日時点での最新版であるOCP4.6.9を使ってGPUを扱ったワークロードを実行する環境を整えたいと思います。
AWS上に真っ新なOpenShiftをデプロイして、GPUが利用可能な状態までインストール作業を行い、最後にTensoflowからGPUを使ってワークロードを実行できるようGPUデバイスを確認します。
- OCP w/ GPUのインストール
- NFD Operatorのインストール
- NodeFeatureDiscovery CRの作成
- GPU Operatorのインストール
- ClusterPolicy CRの作成
- GPUコンテナ起動の確認
- 注意点
- まとめ
OCP w/ GPUのインストール
OCP自体のデプロイ
今回はOCPをAWS上でIPIというインストールタイプを使用してデプロイします。
IPIはインストーラ自身がインフラストラクチャ(AWS)が提供するAPIを操作してOCPをデプロイします。
大きく手順は変わりませんので、以下のRHEB過去記事[0]をご参照ください。
過去記事から、GPUを利用する際の変更点を以下に記載します。
GPUインスタンスを利用してのインストール
GPUインスタンスを使用しますので、以下のようにinstall-config.yamlを変更します。
このdiffではAWSオレゴンリージョンを使用しています。
[takitou@takuya-PC ~]$ diff -uda aws469/install-config.yaml gpucluster-469/install-config.yaml--- aws469/install-config.yaml 2020-12-24 21:38:25.856836200 +0900+++ gpucluster-469/install-config.yaml 2020-12-24 21:37:43.110992200 +0900@@ -4,17 +4,29 @@- architecture: amd64hyperthreading: Enabledname: worker- platform: {}+ platform:+ aws:+ zones:+ - us-west-2a+ - us-west-2b+ - us-west-2c+ type: p2.xlargereplicas: 3controlPlane:architecture: amd64hyperthreading: Enabledname: master- platform: {}+ platform:+ aws:+ zones:+ - us-west-2a+ - us-west-2b+ - us-west-2c+ type: m5.xlargereplicas: 3metadata:creationTimestamp: nullnetworking:clusterNetwork:- cidr: 10.128.0.0/14[takitou@takuya-PC ~]$
基本的にはこのinstall-config.yamlを使ってクラスタをデプロイしてしまえば良いのですが、
GPUインスタンスが提供されていないや一時的なリソースが枯渇しているなどの利用から
特定のAZで取得したいリソースが取得できないことがあります。
回避方法は以下の通りです、
マニフェストを生成して、特定AZでデプロイするインスタンスタイプを変更する
install-config.yamlからマニフェストを作成する
(install-config.yamlは消去されます)
[takitou@takuya-PC gpucluster-469]$ openshift-install create manifestsINFO Credentials loaded from the "default" profile in file "/home/takitou/.aws/credentials"INFO Consuming Install Config from target directoryINFO Manifests created in: manifests and openshift[takitou@takuya-PC gpucluster-469]$
p2.xlargeインスタンスタイプを変更する
[takitou@takuya-PC gpucluster-469]$ grep -r p2.xlarge *manifests/cluster-config.yaml: type: p2.xlargeopenshift/99_openshift-cluster-api_worker-machineset-0.yaml: instanceType: p2.xlargeopenshift/99_openshift-cluster-api_worker-machineset-1.yaml: instanceType: p2.xlargeopenshift/99_openshift-cluster-api_worker-machineset-2.yaml: instanceType: p2.xlarge[takitou@takuya-PC gpucluster-469]$ diff -uda ../99_openshift-cluster-api_worker-machineset-2.yaml.bk openshift/99_openshift-cluster-api_worker-machineset-2.yaml--- ../99_openshift-cluster-api_worker-machineset-2.yaml.bk 2020-12-24 21:41:20.842380300 +0900+++ openshift/99_openshift-cluster-api_worker-machineset-2.yaml 2020-12-24 21:41:30.322290100 +0900@@ -41,7 +41,7 @@deviceIndex: 0iamInstanceProfile:id: gpucluster-469-jf7fk-worker-profile- instanceType: p2.xlarge+ instanceType: m5.2xlargekind: AWSMachineProviderConfigmetadata:creationTimestamp: null[takitou@takuya-PC gpucluster-469]$
クラスタをデプロイする
[takitou@takuya-PC gpucluster-469]$ openshift-install create cluster --dir=. --log-level=debug
エンタイトルメントの設定
通常のサーバでも特殊なリソースを利用する場合はカーネルの開発パッケージを取得してドライバをコンパイルするケースはよくあると思います。
コンテナ環境においても例にもれずこの作業が必要になります。
しかしながらOCPを使ったコンテナ環境においては自動でドライバのコンパイルや配置を行ってくれます。
この章である”エンタイトルメントの設定”というのは、レッドハットのパッケージリポジトリからカーネルの開発パッケージを取得するために必要となる証明書をOCPクラスタに投入するという作業になります。
以下のblog[1]を参照しています。
”Entitled Builds on non-RHEL hosts”という章でエンタイトルメントファイルを取得し、
”Cluster-Wide Entitled Builds on OpenShift”という章でクラスタにMCOを介してエンタイトルメントファイルを行えば、クラスタに存在するPodからレッドハットのパッケージリポジトリにアクセスすることが可能になります。
エンタイトルメントファイルを取得するまで
blog[1]を読むことでおおよその手順は分かるかと思いますが、どのようにエンタイトルメントファイルを取得すればよいか、悩まれることが多いかと思います。実際私はそうでした。
こちらではエンタイトルメントファイルを取得するまでを紹介します。
1.レッドハットカスタマーポータルのRed Hatサブスクリプション管理[2]を開く
2.RHEL8EUSリポジトリにアクセス可能なサブスクリプションを探す

リポジトリ名 rhel-8-for-x86_64-baseos-eus-* にアクセス可能なサブスクリプションを探します。
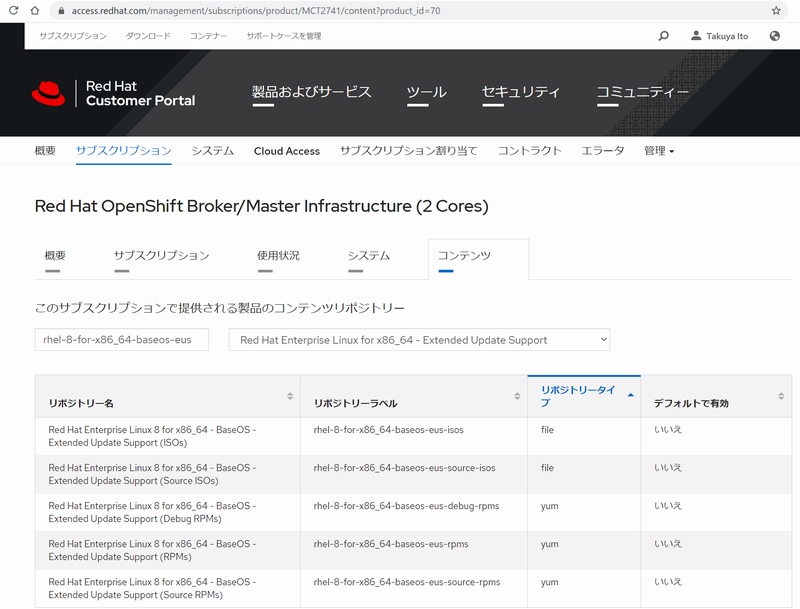
この例では2システム見つかりました。ホスト名が記載されているはずなのでクリックします。
ホスト名をクリックしたら、続いてサブスクリプションタブをクリックします。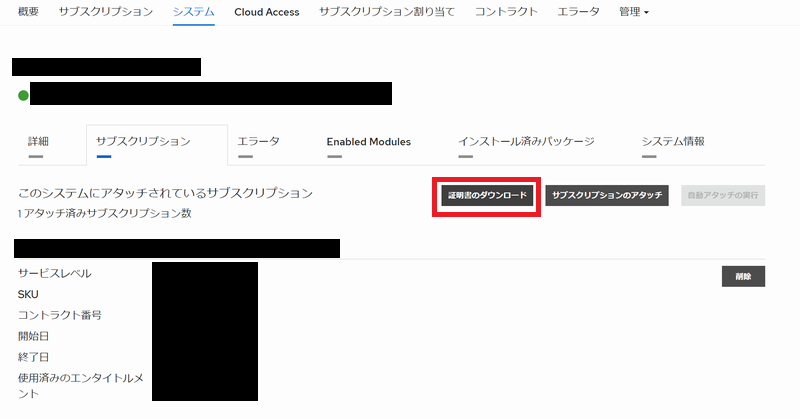
ここに現れる証明書のダウンロードというのをクリックしてzipファイルをダウンロードします。
注意点としてはここで利用する証明書には有効期限があるということです。
ダウンロードした時点でのサブスクリプションが有効な期間でのみ機能します。
ダウンロードしたファイルは2度ほどzipファイルを解凍して、出てきたpemファイルをさきほどのblog[1]手順に従ってbase64エンコードしてMachineConfigマニフェストファイルを完成させます。その後MachineConfigをcreateしてください。
$ sed "s/BASE64_ENCODED_PEM_FILE/$(base64 -w 0 {ID}.pem)/g" 0003-cluster-wide-machineconfigs.yaml.template > 0003-cluster-wide-machineconfigs.yaml
$ oc create -f 0003-cluster-wide-machineconfigs.yaml
無事に追加されると新たなノードのコンフィグが描画され、ノードは新たなコンフィグを適用するために自動的に順繰りに再起動していきます。
ローリングアップデートの様子はOCPのWebUIから確認することができます。

クラスタにエンタイトルメントファイルが導入されていることを確認する
MachineConfigを経由してエンタイトルメントを追加すると、コンテナからレッドハットのパッケージリポジトリにアクセスすることが確認できます。
blogの通りpodを試しに作成してlogを確認します。
$ oc create -f 0004-cluster-wide-entitled-pod.yaml$ oc logs cluster-entitled-build-pod | grep kernel-devel | tail -n 1kernel-devel-4.18.0-147.0.3.el8_1.x86_64 : Development package for ...

NFD Operatorのインストール
NFDをインストールします。OCPのWebUIから導入することができます。
OCPのWebUIのAdministrator viewからOperators => OperatorHubへ行き検索窓にNFDを入力すると今回インストールするべきNFD Operatorを見つけることができます。
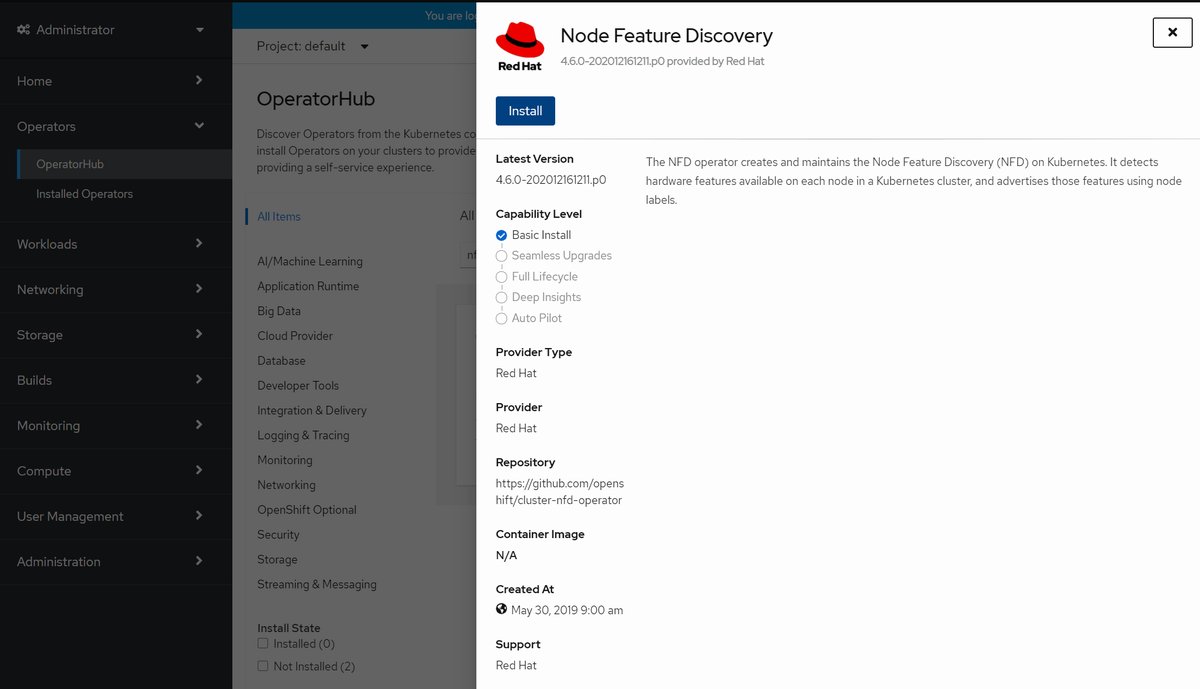
NodeFeatureDiscovery CRの作成
NFD Operatorを導入し、NodeFeatureDiscovery CRが利用可能になったらNFD CRを作成します。
Create NodeFeatureDiscoveryをクリックしたときに出るパラメータはデフォルトのままで問題ありません。

NFD CRを作成するとNodeのメタデータがいくつか追加されているものが確認できます。
この後、pciバスに接続されたベンダーIDを検出したことを示すラベルを元に、GPU Operatorが動作していきます。
[takitou@takuya-PC ~]$ diff -uda ip-10-0-154-235.us-west-2.compute.internal.2338 ip-10-0-154-235.us-west-2.compute.internal.250111--- ip-10-0-154-235.us-west-2.compute.internal.2338 2020-12-24 23:38:57.187241600 +0900+++ ip-10-0-154-235.us-west-2.compute.internal.250111 2020-12-25 01:16:10.546698200 +0900@@ -4,10 +4,13 @@annotations:csi.volume.kubernetes.io/nodeid: '{"ebs.csi.aws.com":"i-"}'machine.openshift.io/machine: openshift-machine-api/gpucluster-469-jf7fk-worker-us-west-2a-rbmh2- machineconfiguration.openshift.io/currentConfig: rendered-worker-5902397f3d48060b278c42c954908e12- machineconfiguration.openshift.io/desiredConfig: rendered-worker-5902397f3d48060b278c42c954908e12+ machineconfiguration.openshift.io/currentConfig: rendered-worker-e8d29294cb3ee4c54eb943cf4e0b0f0c+ machineconfiguration.openshift.io/desiredConfig: rendered-worker-e8d29294cb3ee4c54eb943cf4e0b0f0cmachineconfiguration.openshift.io/reason: ""machineconfiguration.openshift.io/state: Done+ nfd.node.kubernetes.io/extended-resources: ""+ nfd.node.kubernetes.io/feature-labels: cpu-cpuid.ADX,cpu-cpuid.AESNI,cpu-cpuid.AVX,cpu-cpuid.AVX2,cpu-cpuid.FMA3,cpu-cpuid.HLE,cpu-cpuid.RTM,cpu-hardware_multithreading,cpu-pstate.turbo,custom-rdma.available,kernel-selinux.enabled,kernel-version.full,kernel-version.major,kernel-version.minor,kernel-version.revision,pci-1013.present,pci-10de.present,pci-1d0f.present,storage-nonrotationaldisk,system-os_release.ID,system-os_release.VERSION_ID,system-os_release.VERSION_ID.major,system-os_release.VERSION_ID.minor+ nfd.node.kubernetes.io/worker.version: "1.15"volumes.kubernetes.io/controller-managed-attach-detach: "true"creationTimestamp: "2020-12-24T13:01:59Z"labels:@@ -16,6 +19,29 @@beta.kubernetes.io/os: linuxfailure-domain.beta.kubernetes.io/region: us-west-2failure-domain.beta.kubernetes.io/zone: us-west-2a+ feature.node.kubernetes.io/cpu-cpuid.ADX: "true"+ feature.node.kubernetes.io/cpu-cpuid.AESNI: "true"+ feature.node.kubernetes.io/cpu-cpuid.AVX: "true"+ feature.node.kubernetes.io/cpu-cpuid.AVX2: "true"+ feature.node.kubernetes.io/cpu-cpuid.FMA3: "true"+ feature.node.kubernetes.io/cpu-cpuid.HLE: "true"+ feature.node.kubernetes.io/cpu-cpuid.RTM: "true"+ feature.node.kubernetes.io/cpu-hardware_multithreading: "true"+ feature.node.kubernetes.io/cpu-pstate.turbo: "true"+ feature.node.kubernetes.io/custom-rdma.available: "true"+ feature.node.kubernetes.io/kernel-selinux.enabled: "true"+ feature.node.kubernetes.io/kernel-version.full: 4.18.0-193.37.1.el8_2.x86_64+ feature.node.kubernetes.io/kernel-version.major: "4"+ feature.node.kubernetes.io/kernel-version.minor: "18"+ feature.node.kubernetes.io/kernel-version.revision: "0"+ feature.node.kubernetes.io/pci-1013.present: "true"+ feature.node.kubernetes.io/pci-10de.present: "true"+ feature.node.kubernetes.io/pci-1d0f.present: "true"+ feature.node.kubernetes.io/storage-nonrotationaldisk: "true"+ feature.node.kubernetes.io/system-os_release.ID: rhcos+ feature.node.kubernetes.io/system-os_release.VERSION_ID: "4.6"+ feature.node.kubernetes.io/system-os_release.VERSION_ID.major: "4"+ feature.node.kubernetes.io/system-os_release.VERSION_ID.minor: "6"kubernetes.io/arch: amd64kubernetes.io/hostname: ip-10-0-154-235kubernetes.io/os: linux
GPU Operatorのインストール
GPU Operatorをインストールします。OCPのWebUIから導入することができます。
GPU OperatorはNVIDIAが提供するOperatorとなっています。

ClusterPolicy CRの作成
GPU Operatorを導入し、ClusterPolicy CRが利用可能になったらClusterPolicy CRを作成します。


以下のようにyamlでの生成、編集が慣れていれば、yaml viewを使って編集することもできます。

デフォルト値での導入では要件とマッチしないケースなどでは、マニフェストの値を変更することで任意のバージョンを導入することができます。
全てのコンポーネントがコンテナ化されており、バージョンを変更してテストしたいなどのニーズにはコンテナの破棄と作成によって柔軟にかつ確実に対応することができます。
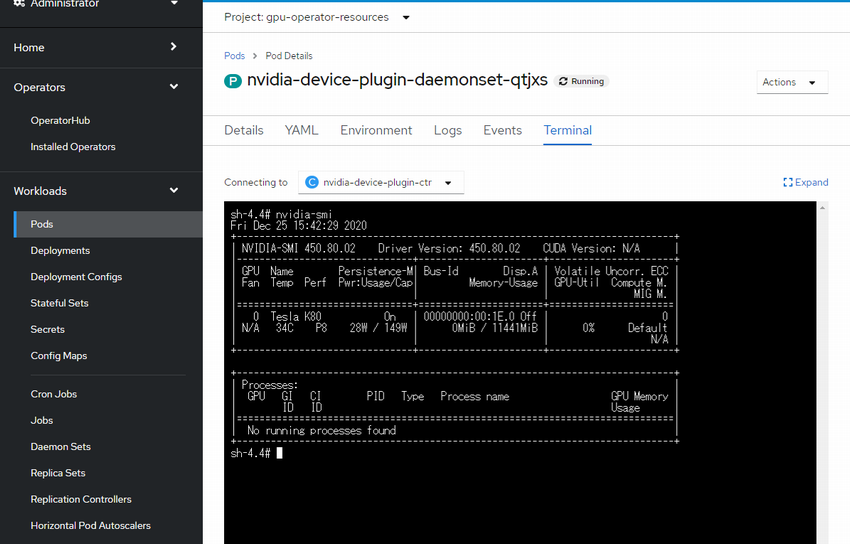
GPUコンテナ起動の確認
TensorFlowを実行するコンテナを以下のように生成します。
resouces => limits => nvidia.com/gpu:1 で取得するリソースを指定しています。
apiVersion: v1
kind: Pod
metadata:
name: tens-pod
spec:
containers:
- name: tens-container
image: tensorflow/tensorflow:latest-gpu-py3
command: ["/bin/sleep"]
args: ["3600"]
resources:
limits:
nvidia.com/gpu: 1
デバイスのリストを取得して確認します。
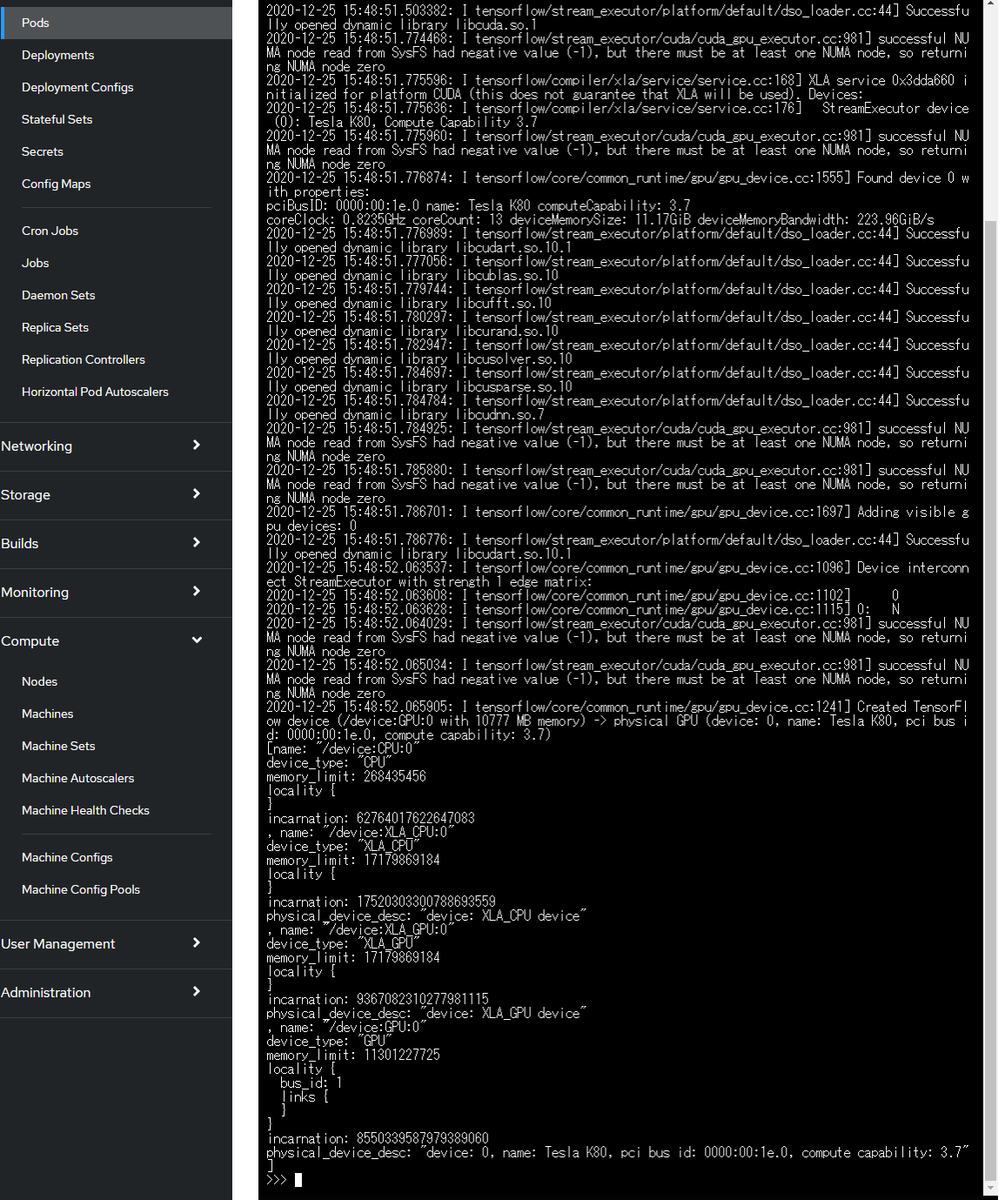
お疲れ様でした!無事GPUリソースを取得してコンテナを実行できていることが確認できました。
慣れてくると自分のPCからインストーラのコマンドを叩いてOCPのインストールに30分(待つだけ)、エンタイトルメントとOperatorの導入10分程度で完了し、昼食を取っている間にGPUコンテナ環境の構築が可能です。
注意点
エンタイトルメントの設定について
このエントリーを書く以前からOperatorの動作検証などを頻繁に行っており、
今回このエントリーを書く最初に使ったGPU Operatorが必要とするエンタイトルメントファイルはかなり前のファイルでした。
このエンタイトルメントファイルの有効期限が切れており、このエントリーを書くときに検証した最初のステップでは見事に失敗しました。。
必要となるエンタイトルメントが含まれているサブスクリプションを選択しているか、有効期限のあるサブスクリプションを選択したか確認してMachineConfigに投入してください。
ClustePolicyの作成
NVIDIAのBlogではGPU OperatorのインストールはHelmを使ったパターンで紹介されています。
今回は簡易に導入することができるのを確認するためにWebUIを使いOperatorHubからインストールをしました。
まとめ
いかがでしたでしょうか、簡単にGPUコンテナ環境をセットアップすることができることが確認できたかと思います。
コンテナとGPUを使ったプラットフォームをご検討している際にも、お気軽にご相談ください。