こんにちは、Red Hatでソリューションアーキテクトをしている石川です。
以前の記事でKubernetes上でサーバーレスのアプリケーション実行を行うKnativeのコンポーネント、Knative Servingについてご紹介させて頂きました。
rheb.hatenablog.com rheb.hatenablog.com
Knativeにはもう一つ主要なコンポーネントとしてKnative Eventingがあります。 Knative Eventingはその名前の通り、イベントソースからのイベントを契機としてKnative Servingでデプロイしたサーバーレスアプリを呼び出すためのもので、イベント情報の保持や、どのイベントに対し何のアプリを実行するのかという紐付け行うためのコンポーネントとなっています。
Knative Eventingを使うことで、例えば毎日決まった時間にサーバーレスアプリを起動したり、Kafkaのトピックが配信されたらそれに応じてアプリを起動するといったことが可能となります。
本記事はKnative入門ということでKnative Eventingの概要や仕組みついて解説していきたいと思います。
Knativeで利用可能なイベントソース
Knative Eventingでは複数のカスタムリソースを使ってイベントソースの設定、イベント情報の保持、その配信を管理します。
まずイベントソースについて、OpenShiftで利用する場合デフォルトでは以下の4つのSourceを使用することが出来ます。
・PingSource
cronでスケジュールしたタイミングで定期的にメッセージを送信する
・ContainerSource
定期的にカスタムのイベントを送信するコンテナイメージをソースとして利用する
・KafkaSource
KafkaのTopicメッセージをソースとして利用する
・ApiServerSource
APIサーバから得られるKubernetesイベントをKnativeイベントとして利用する
また今回は詳細は割愛しますが、Camel Kと連携することで、様々なクラウドサービスを含むより多くのイベントソースを選択することも可能です。 access.redhat.com
これらのSourceに対し、あて先を紐づけていきます。Knative Eventingではあて先のことをsinkと呼び、Sourceのマニフェストの.spec.sinkにて設定が可能です。
apiVersion: sources.knative.dev/v1
kind: PingSource
metadata:
name: test-ping-source
spec:
schedule: "*/2 * * * *"
jsonData: '{"message": "Hello world!"}'
sink:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: sample-app
上記のマニフェストではシンプルにsinkとしてKnative ServingのServiceを設定しており、 スケジュールされた時刻(上の例では2分に一度)メッセージを送信しアプリを起動します。
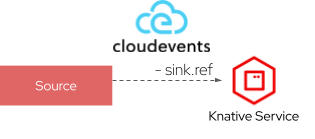
この際イベント情報はCNCFで標準化されているCloudEventsというフォーマットで配信されます。
Sourceに直接Serviceを設定する方法は、直感的にわかりやすい反面、以下のようなデメリットも存在しています。
・一つのSourceを元に複数のアプリを起動したい場合であっても、sinkとしてリスト型の記述が出来ないため、Source自体を複数作成し管理する必要がある。
・イベント情報の配信が失敗したとしてもあて先への再送は行われない。
そのためSourceに対し直接Serviceを設定する方法については、開発環境でサーバーレスアプリの動作を試す場合など、限定的に使用するのが良いでしょう。 以降では、これ以外にどのような方法でイベントとServiceの紐付けが可能かを見ていきたいと思います。
Channel ans Subscription
一つ目のパターンがChannel ans Subscriptionです。
このパターンではSourceからのイベント情報をChannelと呼ばれる一時保管場所に置き、その後あて先となるServiceに対し配信を行います。

Sourceの.spec.sinkにはServiceを設定する代わりにChannelを指定します。
apiVersion: sources.knative.dev/v1
kind: PingSource
metadata:
name: test-ping-source
spec:
schedule: "*/2 * * * *"
jsonData: '{"message": "Hello world!"}'
sink:
ref:
apiVersion: messaging.knative.dev/v1beta1
kind: InMemoryChannel
name: dafault-channel
ChannelからどのServiceにイベントを配信するかを決めるのがSubscriptionというカスタムリソースです。
Subscriptionではマニフェストの.spec.channelで対象のChannelを、.spec.subscriberで配信先となるServiceを記載し、これらの紐付けを管理します。
apiVersion: messaging.knative.dev/v1
kind: Subscription
metadata:
name: default-to-service
spec:
channel:
apiVersion: messaging.knative.dev/v1beta1
kind: InMemoryChannel
name: default-channel
subscriber:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: sample-app
ここで注目したいのがChannelの種類です。 上記ではInMemoryChannelを指定していますが、これ以外にもApache Kafkaをイベント情報の保存場所とするKafkaChannelを選択することが出来ます。(Upstream版のKnativeではこれ以外にもいくつかChannelの種類が提供されています。)
InMemoryChannelの場合、実際にイベント情報を保存するのはPodとなっています。そのため何かの折にPodが再起動したりすると保存されていたイベント情報が消失してしまい、その後の処理が実行できないというリスクが考えられます。 InMemoryChannelの特徴についてはこちらのページが参考になるでしょう。
inmemory-channel.yaml (クリックで展開)
apiVersion: messaging.knative.dev/v1
kind: Channel
metadata:
name: default-channel
これに対しKafkaChannelの場合、Kafkaを構成するPodの一つが再起動したとしてもイベント情報は保持され、また配信先に対しても少なくとも一度(at least once)は必ず情報が配信されるため、より安定的な運用が可能となります。OpenShiftにおいては、クラスタ上でKafkaを構築することができるAMQ Streams Operatorが利用可能なため、これを使うことで簡単にKafkaChannelを利用することが出来ます。
本格的にKnativeを運用するのであればInMemoryChannelではなく、KafkaChannelの利用を検討するのが良いでしょう。
kafka-channel.yaml (クリックで展開)
apiVersion: messaging.knative.dev/v1beta1
kind: KafkaChannel
metadata:
name: kafka-channel
spec:
numPartitions: 10
replicationFactor: 3
Broker ans Trigger
二つ目のパターンがBroker and Triggerです。
こちらのパターンも、基本的な考え方としてはChannel and Subscriptionと同様で、Sourceから得たイベント情報をBrokerに一時的保存し、Brokerとアプリの紐付けとしてTriggerを作成します。

Channel and SubscriptionにおけるChannel相当がBrokerであり、Subscription相当がTriggerだと考えると理解しやすいかもしれません。
ただし、Broker and Triggerのパターンでは、Triggerの中でイベント情報のフィルタリングが可能であるという点がChannel and Subscriptionのパターンとは異なっています。
例えば、以下の図のように二つのSourceを一つのBrokerに繋ぎ、イベント情報のフィルタリングを設定しなければ、それぞれのSourceで発生した全てのイベントを契機にアプリが起動、実行することとなります。

対して、Triggerの中でフィルタリング設定を入れることにより、特定のSourceからのイベントのみに反応してアプリを起動するということが可能となります。

Channel and Subscriptionのパターンでは、Sourceの種類ごとに起動するアプリを変えたい場合、その分だけChannelを複数作成する必要がありました。 Broker and Triggerパターンでは、単一のBrokerで複数のSourceからのイベントを受け取り、その属性ごとに配信先の振り分けが可能となるため、よりシンプルに運用することが可能となります。
Triggerにおけるフィルタリングの記述は.spec.filterにて実施します。
この際、ここに書かれた条件に合致する場合のみイベント情報を配信する、という形となるため注意しましょう。
apiVersion: eventing.knative.dev/v1
kind: Trigger
metadata:
name: kafka-to-app
spec:
broker: kafka-broker
# 以下の条件に合致する場合のみイベント情報をSubscriberに配信する。
filter:
# この例ではSourceがPingSourceの場合のみServiceへの配信が行われる。
attributes:
source: /apis/v1/namespaces/test-serverless/pingsources/ping-source
subscriber:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: sample-app
Broker and Triggerパターンを採用する際の注意として、Kafkaを使ったBrokerについては2022年9月現在Tech Previewのステータスとなっています。 そのため商用環境でKafkaBrokerを使う場合は利用やサポートに関しての条件を事前にご確認頂くとよいでしょう。 access.redhat.com
OpenShiftコンソールの活用
ここまでKnative Eventingのイベント配信パターンについてご紹介してきました。
最後にKnative関連でOpenShiftのコンソールから操作できる便利なポイントにも触れたいと思います。 Channel and Subscriptionの場合も、Broker and Triggerの場合もカスタムリソースを作成することで、あるイベント情報に対して起動するアプリケーションを決めるわけですが、OpenShiftの場合、コンソールからの操作で必要なカスタムリソースを簡単に作ることが出来ます。

トポロジービュー画面から、紐付けをしたいコンポーネント(上図の場合はBrokerとService)間で矢印をドラッグすると、GUIでTriggerやSubscriptionの作成を行うことができます。

Triggerであれば、マニフェストで記載するのと同様にフィルターについての設定も画面から可能です。
またOpenShift Serverlessをインストールすると、コンソールの監視ダッシュボードから、Serverless関連のメトリクスを確認することができます。
こうした機能が設定不要ですぐに使えるという点もOpenShiftでKnativeが使いやすくなっているポイントと言えるでしょう。
まとめ
今回はKnative Eventingにおける基本的な考え方や、イベント配信のパターンについてご紹介しました。 OpenShiftではコンソールからServerlessを扱いやすくする様々な機能を提供したり、Operatorを使ってKafka等がインストール可能であるため、Knative Eventingに必要な環境を簡単に準備することが出来ます。 本ブログを読んでもしご興味持たれたら是非Knativeを使ったサーバーレスアプリケーションを試してみて下さい!