Red Hat コンサルタントの金子です。「アプリケーションモダナイゼーション」に関連する連載の第7回です。
- はじめに:高速なデリバリーの「その先」にある運用者の責任
- VM時代とReplatform後の決定的な違い
- システムの内部状態を理解する「可観測性(Observability)」の徹底活用
- 運用リスクを劇的に低減する DevSecOps の仕組み
- まとめ:Replatformは「安定した運用」というビジネス価値を生む
はじめに:高速なデリバリーの「その先」にある運用者の責任
前回はReplatformがCI/CD、脆弱性診断、分散トレーシングによって「高速かつ安全な開発サイクル」を実現し、開発者の体験を向上させることを解説しました。しかし、いくら開発者が早くコードをリリースできても、それを安定して動かせなければビジネス価値は生まれません。運用者は、システムの安定稼働、障害の迅速な復旧、そしてセキュリティの維持という重要な責任を負っています。 特にReplatformによりコンテナのベストプラクティスに則った構成、1 プロセス 1 コンテナにすることにより、複数プロセスが同居していたサーバーは分散システム化が進みます。これにより「障害発生時の原因特定が困難になる」という新たな課題が発生します。また、レガシー環境ではOSパッチ管理や個別対策に依存していたセキュリティ対策も、コンテナ環境でどう担保するかが焦点となります。 本記事では、コンテナプラットフォーム(Red Hat OpenShift)がいかにして、従来の「運用負債」(属人化や非効率な手作業、形骸化した監視)を解消し、統合された仕組みによってシステムの信頼性(Reliability)と回復性(Resiliency)を高めるのかを、具体的なツール(ログ、監視、セキュリティ)を通じて深堀りします。
VM時代とReplatform後の決定的な違い
従来のVM(仮想マシン)時代における運用現場は、多くの「負債」を抱えていました 。
例えば、監視一つとっても、アプリケーション担当チームとインフラ担当チームで使うツールがバラバラでした。このように担当領域やツールが分断(=サイロ化)されていると、デプロイ作業全体を一気通貫で自動化することが難しくなります。その結果、結局は「サーバー一台ごと」に手作業で監視や運用の設定をしなければならない非効率さが温存されてしまいました。
そして、こうした手作業こそが、「設定漏れ」や「変更忘れ」といったヒューマンエラーの温床となります。さらに、障害対応のノウハウも、ツールと同様にチーム内に閉じこもって共有されなかったため、いざ問題が起きても原因特定や復旧が後手に回りがちでした。
Replatform、すなわちOpenShiftがもたらす変化は劇的です 。従来はアプリケーション開発者が VM 上にアプリケーションをデプロイしており、そのVM のOSのメンテナンスもアプリケーション開発者が担うケースが有りました。OpenShift ではOSのメンテナンスに関してはアプリケーション開発者の責務ではなく、インフラチームの責務となります。これはOSとアプリが分離され、アプリケーション開発者のプラットフォームの運用負荷が軽減されます 。 そして最も重要な点は、デプロイ、スケーリング、監視、ログ収集のすべてが、Kubernetesの標準リソースによって一元化・自動化されることです 。 これにより、運用者の目線は「サーバー単位の個別管理」から、「Pod/Namespace(プロジェクト)単位の可視化・自動化」へとシフトし、IT運用コストの低減が実現します 。
システムの内部状態を理解する「可観測性(Observability)」の徹底活用
高速な開発サイクルにおいては、万が一問題が発生した場合に「誰が、いつ、どこで、何を」追跡するかが鍵となります。Replatform後の分散環境において、この課題を解決するのが統合された可観測性(Observability)の仕組みです。
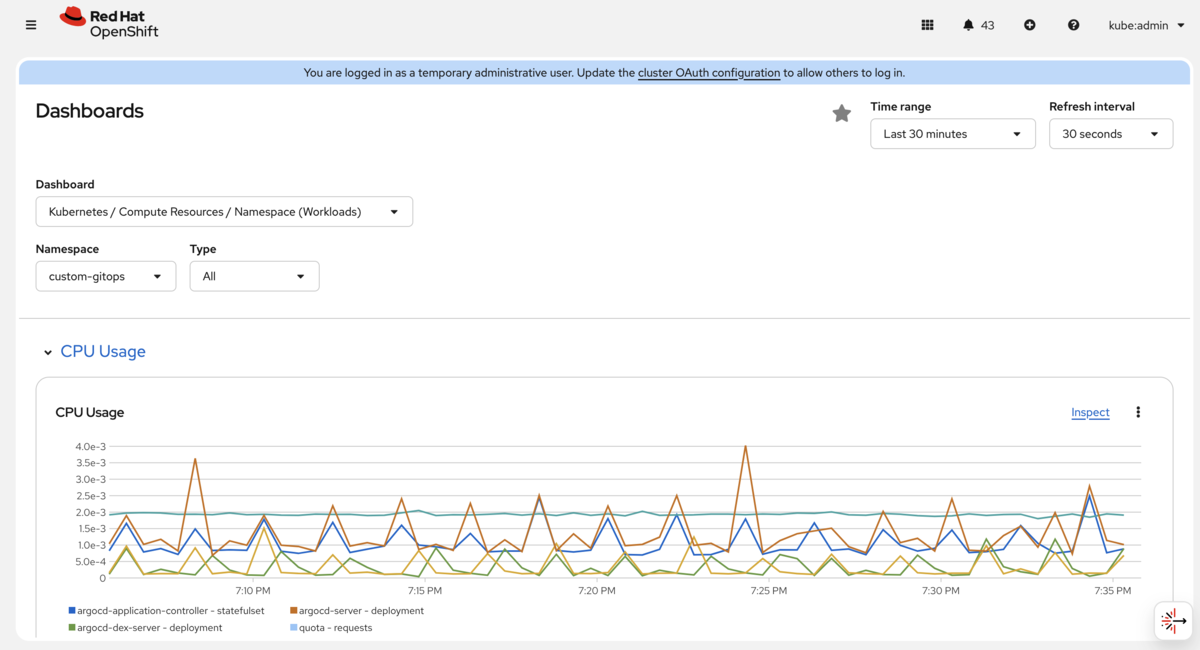
統合されたモニタリング(OpenShift Monitoring/Prometheus)
- メトリクスの一元収集: OpenShiftは、プラットフォームの機能としてPrometheusベースのOpenShift Monitoringを提供し、CPU使用率やメモリ使用量などの各種メトリクスを統合ダッシュボードで一元的に監視できます。
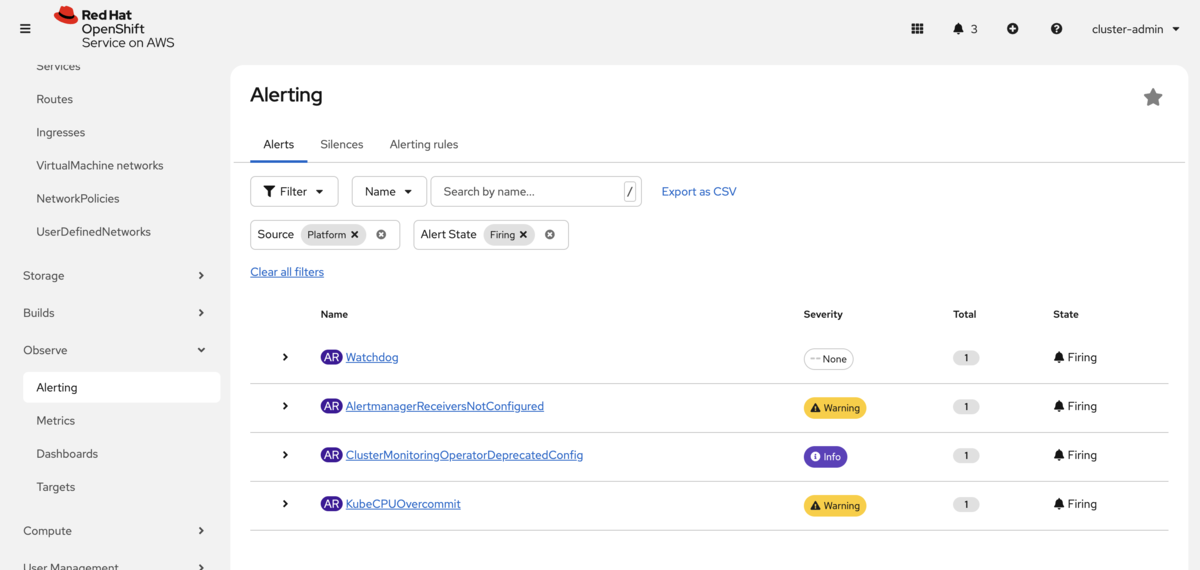
- 障害対応の迅速化: 障害発生時も、アラートをもとに迅速に原因を特定しやすくなります。
ログの一元管理(OpenShift Logging/Loki Stack)
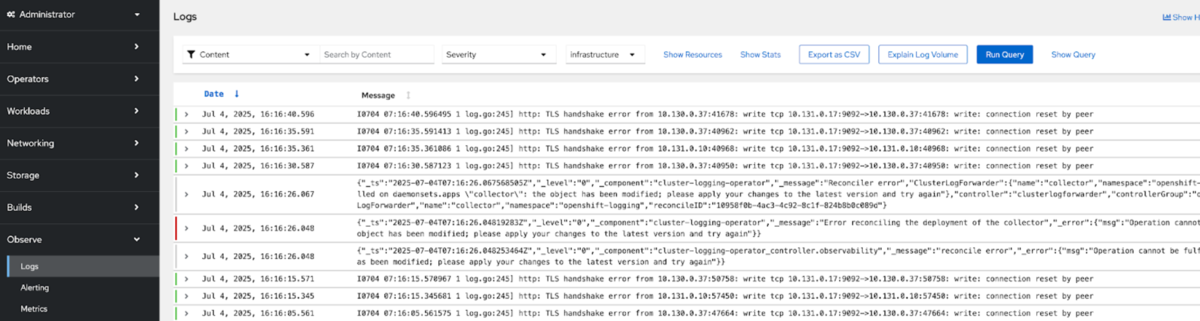
- ログの一元管理: 従来のサーバーごとに散在していたログを、OpenShift Logging(Lokiスタックベース)によってシステム全体で一元的に集約し、検索可能にします。
- 開発と運用の連携:開発者がコンテナの標準的な作法(ログをstdout/stderrに出力する)に従うだけで、OpenShift/Kubernetesの統一されたログ収集の仕組みに自動的に連携されます。これにより、運用側は最適化された一元的なログ管理方式を自動的に踏襲でき、開発と運用の分断が解消されます。
分散システム診断の切り札(OpenShift Distributed Tracing)
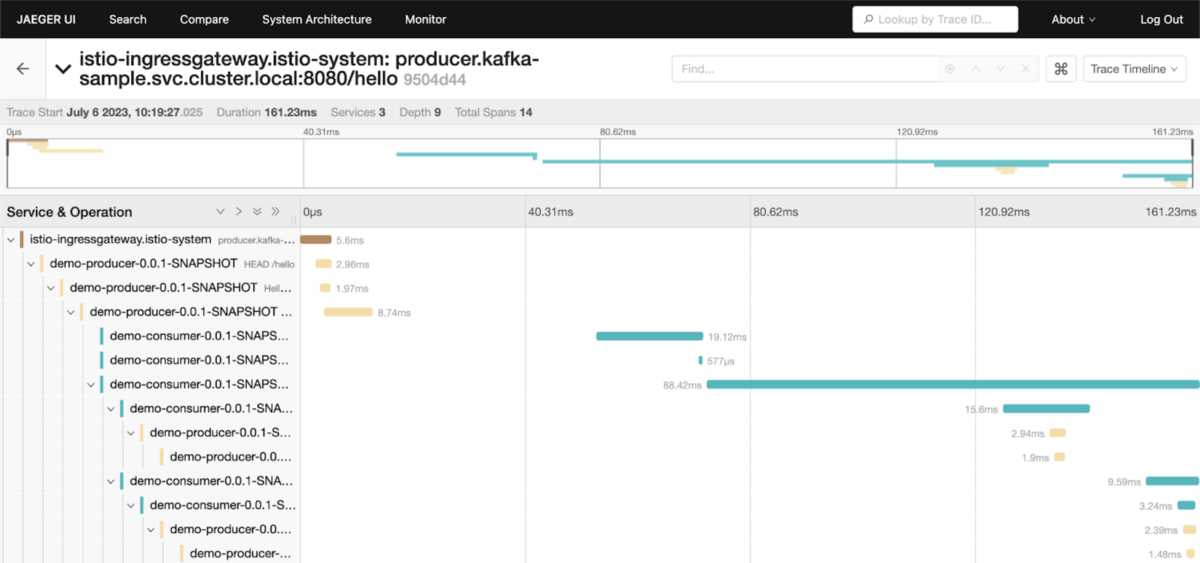
- 課題: 分散システムでは、リクエストが複数のサービスをまたがるため、ボトルネックの特定が困難です。
- 解決策: OpenShift Distributed Tracing(Grafana Tempo)は、サービスをまたぐ一連のリクエストにユニークなIDを付与し、その経路を可視化します。
- 具体的な効果: これにより、「決済処理の遅延が、実は在庫確認サービスの一時的な応答遅延だった」など、データに基づいて迅速に根本原因を特定し、障害復旧時間の短縮(例: 1日→数時間へ短縮)に貢献します。
運用リスクを劇的に低減する DevSecOps の仕組み
Replatformによって基盤がコンテナ化されることは、セキュリティ対策が個別対策から「プラットフォームによる一括管理」へとシフトすることを意味し、運用側の負担を大きく軽減します。
プラットフォームによるセキュリティの底上げ
- セキュアな基盤: OpenShiftはRHEL CoreOSやRed Hat Universal Base Image (UBI)を土台とし、厳格なセキュリティポリシーをデフォルトで適用することで、安全なコンテナ運用を容易に実現します。
- よりセキュアなデフォルト: OpenShiftは、コンテナの実行をデフォルトで非rootユーザーとし、最小権限の原則に基づいて稼働させるため、開発者が特別なセキュリティ設定をしなくても、基盤側が自動的にセキュリティの「守り」を強化します。
継続的な脆弱性管理と防御
従来の開発プロセスでは、セキュリティ診断はリリースの最終段階で行われることが多く、この段階で重大な脆弱性が発見されると、リリースが延期され、開発チームは大きな手戻りを強いられていました。これは、アプリケーションの継続的な進化を阻む技術的負債の一つです。
OpenShiftで実現されるDevSecOpsは、セキュリティ対策を開発プロセスの早い段階(シフトレフト)に組み込むことで、この課題を解決します。OpenShiftは、土台となるOSやコンテナのベースイメージがセキュアに保たれている上で、アプリケーションのサプライチェーン全体に多層的なセキュリティを組み込みます。
イメージスキャン:継続的なリスク監視の実現
- イメージスキャン: 開発フェーズでビルドされたコンテナイメージは、Red Hat Quayによって継続的にスキャンされ、既知の脆弱性(CVE)がないかチェックされます。
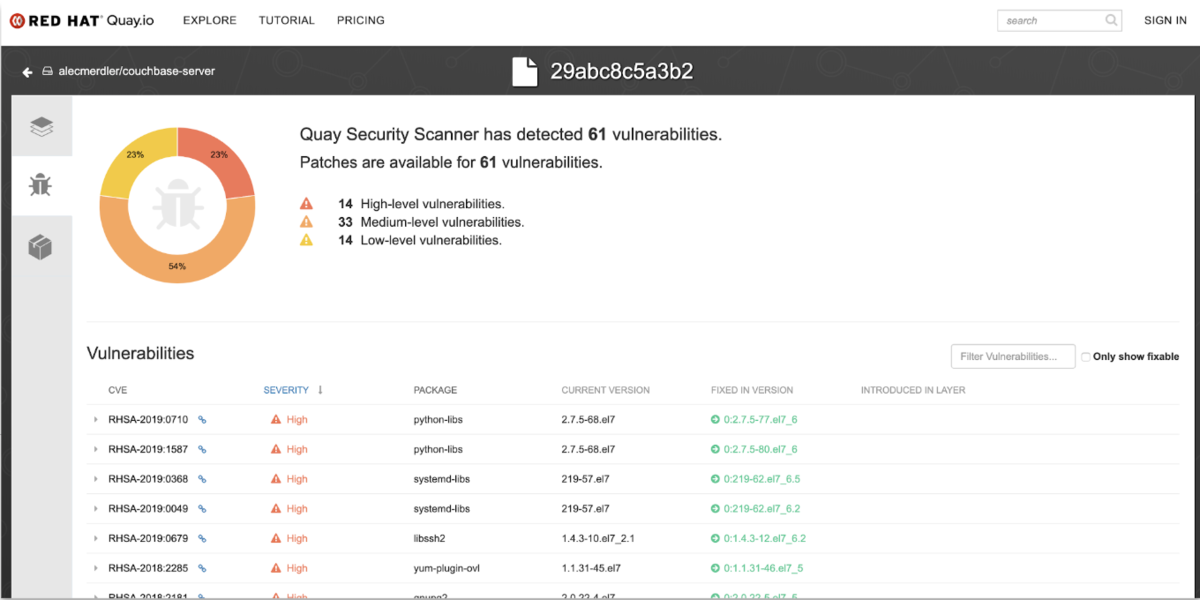
継続的なリスクの可視化: このスキャンは、一度きりのチェックではなく、イメージがレジストリに保存されている間も継続的に実行されます。これにより、デプロイ後に新しい脆弱性が発見された場合でも、運用側が迅速にリスクを把握し、対処することが可能となります。レガシー環境で発生しがちな「サポート切れのソフトウェアを使い続けることによる既知の脆弱性の放置」というセキュリティ上の負債 を、プラットフォーム側が継続的に監視・通知することで防ぎます。
デプロイ時の制御:本番環境への安全なゲートウェイ
- デプロイ時の制御: Red Hat Advanced Cluster Security for Kubernetes (ACS) を活用することで、「脆弱性レベル"Critical"のイメージはデプロイさせない」といったポリシーを適用し、安全でないアプリケーションが本番環境に到達するのを防ぎます。
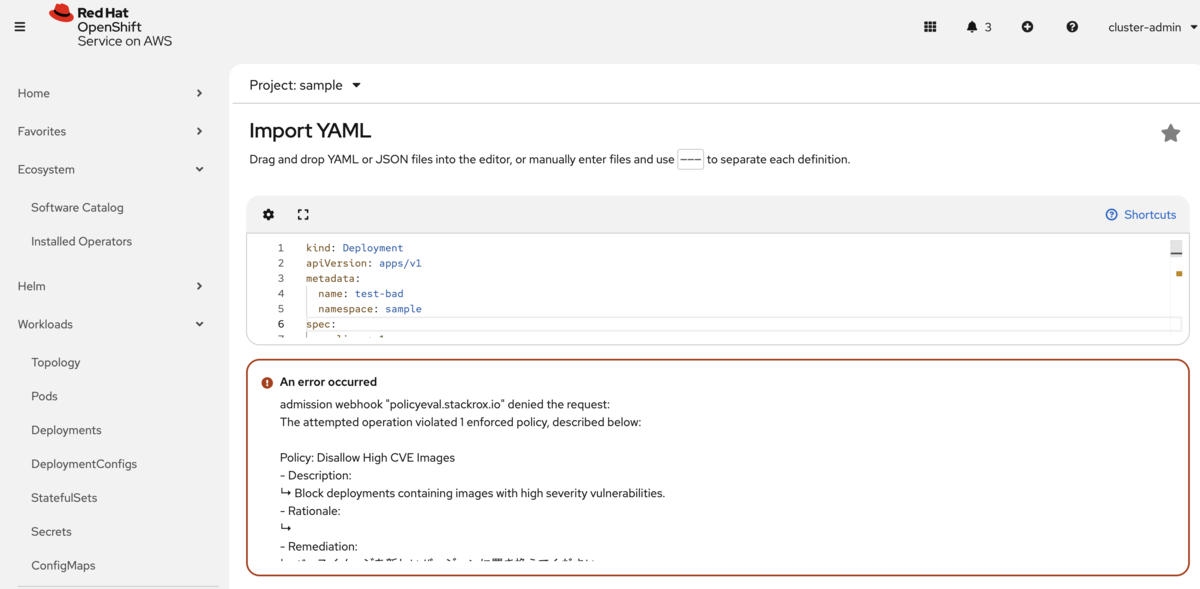
自動化されたリスク阻止: ACSは、CI/CDパイプラインと連携してデプロイの最終的なゲートウェイとしての役割を果たします。これにより、開発段階で万が一見落とされた安全でないアプリケーションが、誤って本番環境に到達するのを未然に防ぎます。これは、Kubernetesクラスター全体のセキュリティを監視・制御する中核的な役割を担い、デプロイにおける手動チェックや属人化のリスク(運用負債)を排除します
実行時の防御:ビジネスのレジリエンス強化
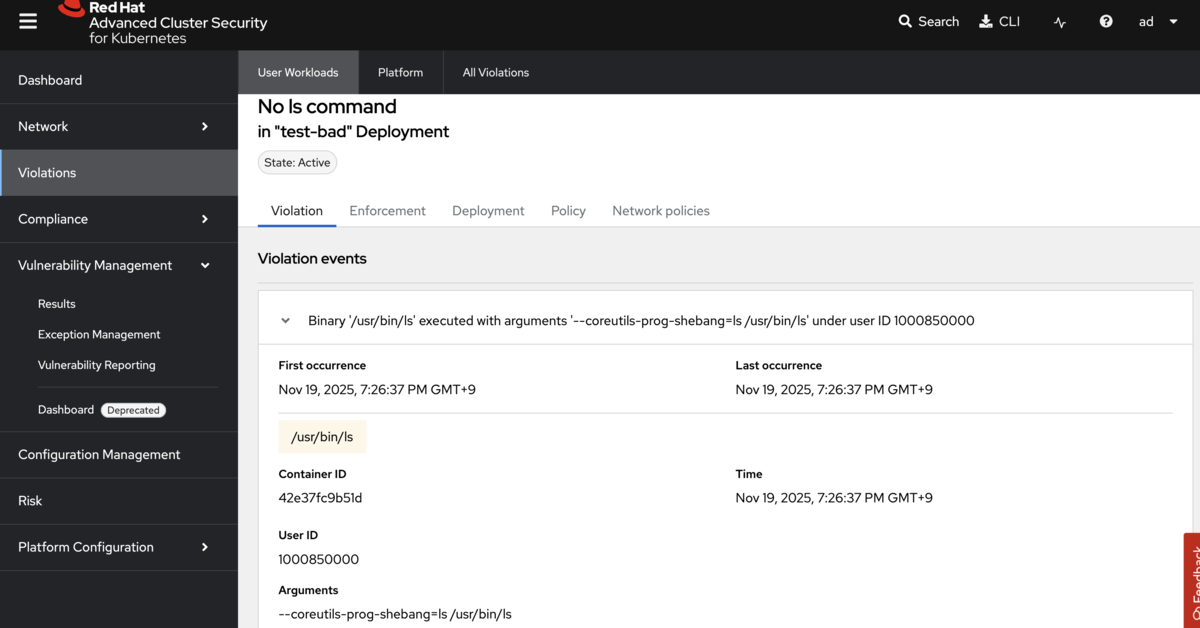
- 実行時の防御: ACSは、実行中のコンテナの異常な振る舞いを検知し、実行時(Runtime)の脅威にも迅速に対応します。
ゼロデイ脅威への対応: ACSは、設定されたセキュリティポリシーと異なる異常な振る舞いを検知した際には、即座にアラートを発し、実行時(Runtime)の脅威にも迅速に対応することが可能です。これは、静的なスキャンやポリシーチェックでは防げない、ゼロデイ攻撃や予期せぬ内部侵入に対する最後の砦となります。このような多層防御の仕組みにより、障害やセキュリティ事故に強い、可用性の高いシステム、すなわちビジネスのレジリエンスが強化されます。
まとめ:Replatformは「安定した運用」というビジネス価値を生む
- Replatformは、単なるインフラのお引っ越しではなく、CI/CDによる高速化(開発)と、統合された可観測性・多層セキュリティ(運用)という両輪を揃えることで、ビジネスの変化に素早く、そして安全に対応できる「開発・運用文化」そのものを変革する取り組みです。
- 統合されたロギング、監視、分散トレーシングによってシステムの健全性が高まり、障害発生時の迅速な対応が可能となることで、ビジネスのレジリエンスが強化されます。
- この変革の鍵を握るのは、CI/CD、セキュリティ、可観測性といった要素を統合して提供するプラットフォームであるOpenShiftの存在です。
- 安定した運用基盤を手に入れることで、運用部門はインフラの保守や障害対応といった「守りの工数」を削減し、ビジネス価値創造といった「攻めのIT」に集中できるようになります。
次回からはリファクタリングです。 数回に分けてマイクロサービスアーキテクチャや分散システムが進んだ世界だとどうなるかをお伝えする予定です。