レッドハットでコンサルティングしているフェンです。 今回は、Red Hatの同僚であるBruno Meseguerの記事「360° Observability of Camel Integrations in Red Hat OpenShift」を翻訳して共有します。すみませんが、私の翻訳スキルの関係で、数回に分けて皆さんに届けたいと思います。
-想像してください-
あなたのチームが砂漠にいます...
あなたが強風を感じています...(実は砂嵐があなたに近づいてきます)...
チームはあなたの状況報告を待っています...
そして、あなたは状況確認に焦ています...

あなたは最初に、高いところに行けば、遠く見えますので、そうしました。しかし、現実は、塵や砂が強風により激しく吹き上げられ、空高くに舞い上がる砂塵により、見通しが著しく低下してしまいます。
そして、あなたは、360°鳥瞰できる気球を持っていることを思い出しました。

それを使って高度数千キロから砂嵐の進路を観察して、チームにオアシスへ辿るルートを報告できました。

この記事では、「360°鳥瞰できる気球」 のような 可観測性機能 をどのように採用するか、さまざまなオープンソース技術を組み合わせる方法、およびそれらを調和して利便性を高める方法を示したいです。
この記事の例を説明するために作成されたソースコードは、GitHub上で公開していますので、時間があれば、動かして見てください。
目次
「4. 導入」以降の章は次回以降に掲載させてください
1. はじめに
洗濯機のコース選びボタンを押しても反応しないときや、音楽プレーヤーがなんらかの理由で動かなくなったとき、PCがフリーズしたとき、多くの場合、皆さんはオン/オフボタンを押すという万能な速攻策をよく使いますね。
だから、一部のデータセンターで動いているサーバが、未だにこの方法で、cronジョブを組んで定期的に再起動させています。ただし、予期しない誤動作を少なくしてスムーズに実行できるように、プラットフォームを改善するために、欠陥を見つけて解決することをお勧めします。
1つまたはごく少数のサーバ/システムしか関与していない場合、問題を見つけて修正するのは簡単ですが、多数のサーバ/システムが複雑に絡んでいる場合はそう簡単ではありません。多数のシステムが互いにどのようにつながっているかは、分子レベルで炭素元素がいかに美しく、洗練された構造で形成されていることを思い出させます。

相互接続されたすべてのサーバ/システムのうち、構造内のどこで問題が発生しているかを正確に指摘することは非常に困難になります。この難しさは特に、自明ではない通信インタラクションの使用する分散システムに当てはまります。例えば、あるシステムが特定のエンドポイントへの通知イベントを発行し、複数の非同期で待機したプロセスが反応して新しいイベントを生成して下流のシステムに伝播していくような構成。
監視はサンプリングと統計データ(ヘルスデータやその他の評価指標)の収集に役立ちますが、障害分析データの収集にはあまり役立ちません。特定の問題を解決するための証拠を追跡するには、他の方法も必要です。
例えば、犯罪捜査の分野では、ルミノール試験を使って血痕を見つけ出します。また、天文学の分野では、光学望遠鏡は遠く離れた銀河(星雲の下)を見せてくれるが、そこにあるすべてのことを教えてくれないでしょう。だから電波、X線、他のタイプの望遠鏡で撮った画像と組み合わせて、色々な角度/視点から銀河全体を研究 する必要があります。
「かに星雲」の全体像:

私たちのIT分野においても、確かに多くの商用ソフトウェアベンダーは、非常に優れた”望遠鏡”を備えた、非常に魅力的な製品を提供しています。それらを使って、サーバ群/システム群のさまざまな部分に潜り込むができます。
この記事は、皆さんが気軽に利用できる、オープンソース技術を駆使し、インテグレーション(Integration) 、サービス(Service) 、メッセージング(Messaging) のアプリケーション領域に焦点を当て、可観測性(Observability) を紹介します。
2. 可観測性(Observability)とは
顧客の技術支援するときでも、トラブル発生したあとにエンジニアが適切な診断を行うことが困難であることを度々目にしてきました。その理由はまず、運用チームから報告した障害事象の説明が不十分であること。そして、重要な情報が欠落した状況下で、障害分析するエンジニアは無力を感じます。このため、障害解決には、運用チームと洞察力に富んだ知識を持っているエンジニアとの密接な協力が必要です。確証を掴めるためのツールとテクニックがあれば、障害の根本原因が究明され、問題が修正されて根絶されます。そうでなければ、たいていの場合、回避策が適用され、技術的な負債が残り、システムの信頼性が低くなります。
システムに、この 確証を掴めるためのツールとテクニック が備えていれば、システム内部の状態が取得できる訳ですので、この機能は可観測性(Observability)機能と呼びます。即ち、可観測性 とは、システムが本番環境でどのように動作しているかを取得できるの特性 であります。
可観測性機能は、ほとんど、プラグアンドプレイの形で導入できます。プラグアンドプレイ (Plug and Play, PnP) は、パーソナルコンピュータ(パソコン)に周辺機器や拡張カード等を接続した際にハードウェアとファームウェア、ドライバ、オペレーティングシステム、およびアプリケーション間が自動的に協調し、機器の組み込みと設定を自動的に行う仕組みのことである。
しかしながら、可観測性機能は、すべての障害原因を一発で突き止めるような、Out-of-box(取り出してすぐ使える)な道具ではありません。この記事では、あちこちで補足を取り入れながら、可観測性を最大にするためのいくつかのアプローチを議論します。
まず、次の図はシステムの可観測性を実現するために有効な組み合わせを示しています。

以降では、これに使用されるテクノロジについて概説し、それぞれの観点について詳しく説明します。
最初に要約すると、可観測性機能の3つの要素とは、
- ヘルスチェックを実行するための 監視(Monitoring)
- ログ調査するための統合した ログ集約(Log Aggregation)
- サービス間のデータ流れを追跡するための トレース(Tracing)
2.1. 関与する「技術」概要
この記事で取り上げた概念と原則は、ベアメタル、仮想化、またはコンテナーで実行したシステムに対しても適用できます。この記事の目的は、可観測性情報の生成、分析、および可視化するための戦略を説明することです。
ただし、この記事は、戦略の一般論を避けるため、インテグレーションとコンテナーを中心にさせてください。なぜなら、インテグレーションとはシステムを容易に相互連携するための基盤、コンテナーが俊敏性と自動化を提供する基盤であり、この2つは社内システムでよく使用している技術基盤です。皆さんがこの記事を読んだあと、ここに書かれた「技術」から切り離して、「戦略」を自分たちのシステムに適用できるようになることを期待します。
また、この記事では可観測性に関連する以下の「技術」を扱っています。後でそれぞれの技術詳細を説明します。
 Apache Camel: インテグレーション用フレームワーク
Apache Camel: インテグレーション用フレームワーク Kubernetes: コンテナの実行環境
Kubernetes: コンテナの実行環境 Prometheus: 監視用メトリクスの収集ツール
Prometheus: 監視用メトリクスの収集ツール OpenTracing: トレース用の技術中立なトレーシング仕様
OpenTracing: トレース用の技術中立なトレーシング仕様 Jaeger: OpenTracingに準拠した1つの実装
Jaeger: OpenTracingに準拠した1つの実装

 EFK: ログ収集ツール ElasticSearch + Fluentd + Kibana (EFK)
EFK: ログ収集ツール ElasticSearch + Fluentd + Kibana (EFK)
後程の"導入編"では、サンプルコードやスニペットなどを使って、これらの「技術」の実践的な導入方法を示します。
便利上、この記事では予め2つのレッドハット製品を前提にしました。(すみませんが、仕事の関係上で)
- Red Hat Fuse: Apache Camelを拡張した、オープンソースのシステム統合のソリューション。システム統合の開発と運用は、Camelフレームワークよりも簡単になります。
- Red Hat OpenShift: Kubernetes を拡張した、オープンソースのコンテナ実行環境。コンテナーのデプロイと設定は、Vanilla Kubernetes 環境よりもはるかに容易になります。
それでは可観測性のさまざまな領域をカバーし、それぞれの役割を果たしているかを確認しに行きましょう。
2.2. 監視(Monitoring)
監視について、別の記事で詳しく取り上げたので、ここでは省略させてください。
しかし、次のログ集約の話に入る前に、監視分野で大活躍しているPrometheusだけを再度紹介したい。Prometheus は Kubernetesに上手く統合されたため、あらゆるソースからメトリックを収集するために最適な選択肢でしょう。
さらにOpenShift 上、PrometheusがOut-of-boxで提供されています。
CamelインテグレーションをFuseにデプロイすれば、Fuseが自動的にJVMのメトリクスとCamelのメトリクスをPrometheusに公開してくれます。

下の図では、Grafanaダッシュボードの画面で、Camelインテグレーションから取得した情報を表示しています。

JVMのメトリクスとCamelのメトリクスをPrometheusに公開する方法は、この記事をご参照ください。
2.3. ログ集約(Log Aggregation)
ログ集約を有効にすると、すべての出力ログの収集が可能になり、統合コンソールから自由に参照できるようになります。そうでなければ、プラットフォーム内に散在する数百のログファイルの中から必要なログを見つけるのは困難でしょう。OpenShift上なら定番のEFK組み合わせ(ElasticSearch、FluentdとKibana)を使用できます。これらはすべて自由に利用できるオープンソースプロジェクトです。EFKについて、たくさんの記事がありますので、ここでは概説だけにします。

上図のように、ログ収集のアイデアは、軽量なエージェント(Fluentd)を使って実行中のすべてのコンテナからログを収集/解析/変換し、それらをElasticSearchに送信します。ElasticSearchはログを格納し、解析したフィールドをインデックスすることで、後で簡単に検索可能の状態にします。ユーザはKibanaというユーザインタフェースを介して、すべてのコンテナのログを照会/検索が可能になります。
このアプローチはまた、アプリケーションの簡素化をもたらします。アプリケーションの運用設計時、ログローテーションやディスク使用量を減らすためのログ圧縮が不要となります。アプリケーションはログをコンソールに送信するだけでよく、Fluentdはそれらを収集してElasticSearchで処理しやいJSON形式へ変換します。
ダウンストリームログ形式はJSONとなるため、アプリケーション自体がJSONエンコーダーを内包すればさらに合理的です(必須ではありません)。JSONエンコーダーにより、ElasticSearchのインデックス作成およびキー/値アクセス戦略に従うことができます。
ログの例を見てみましょう。仮に、システムに入ってくる要求ヘッダのclientIDをロギングすると仮定すると、コード行は次のようになります。
log("got request from client")
JSON形式のログは次のようになります。
{ "message":"got request from client" , "clientID":"YnJ1bm8wMQ==" }
JSONエンコーダーを使用すると、重要な情報を事前定義済みJSONフィールドにマッピングができます。ElasticSearchは、インデックスフィールドとしてJSONのフィールド名を使用して、ユーザーがKibanaのWebコンソールを使用して『filter='clientID'』のクエリで検索できるようになります。
注意事項として、多数のコンテナが稼働しているので、大量のログが収集されます。ElasticSearchは、管理者がストレージ使用量を確実に制御できるように、インデックス管理ポリシーも提供されています。これを忘れずに検討しましょう。
EFKはログデータへのアクセス方法に優れたアプローチを提供してくれていますが、大量のログを集めた後、必要な正確な情報を分類するためのフィルタ設定(即ちログ分析)は依然難しいです。ログ分析は主にアプリケーションに依存し、システムごとに異なるからです。
2.4. トレース(Tracing)
アプリケーションがトレーサビリティ情報を生成できるようにすることで、システム間でデータ受け渡し時のメタデータ、例えば、タイムスタンプやシステム名など、が分析の際に役に立つ情報となります。もっと重要なのは、これらの情報によって、データ処理フローがどのシステムまで横断したかが分かるようになります。下図のように、個々の処理おいて共通の”trace-id”もメタデータに含まれているからです。
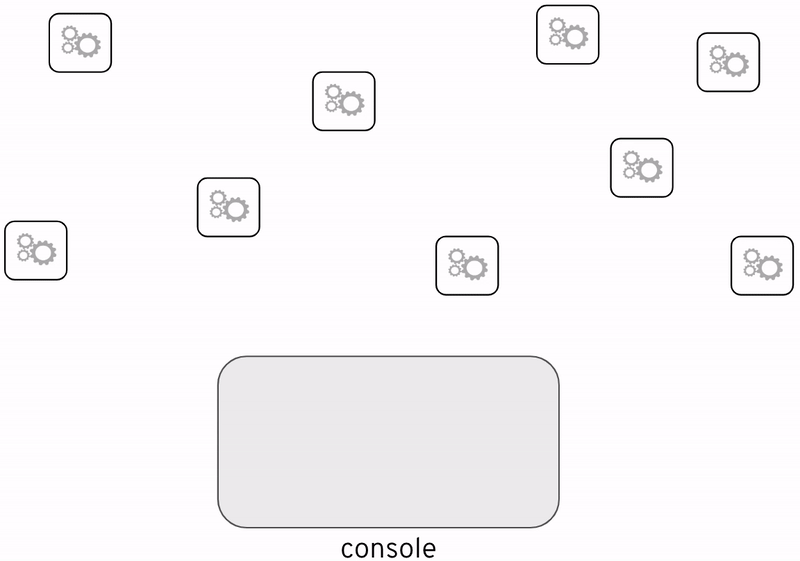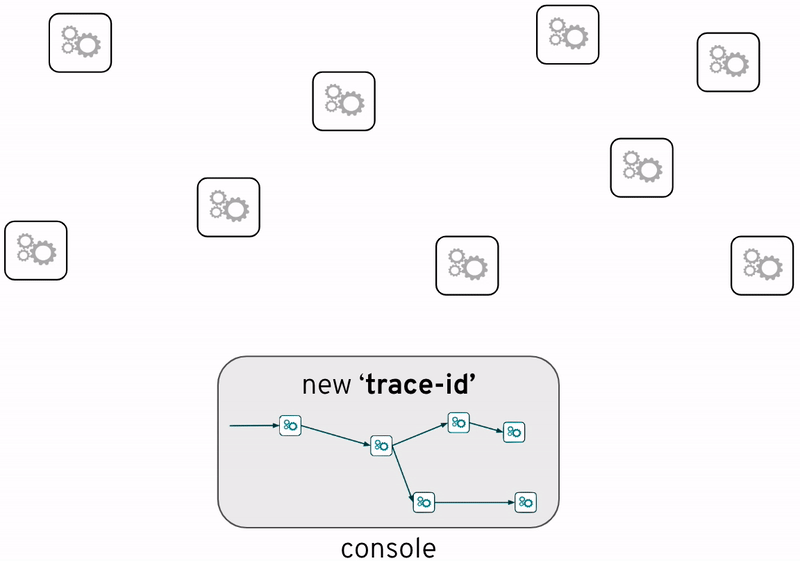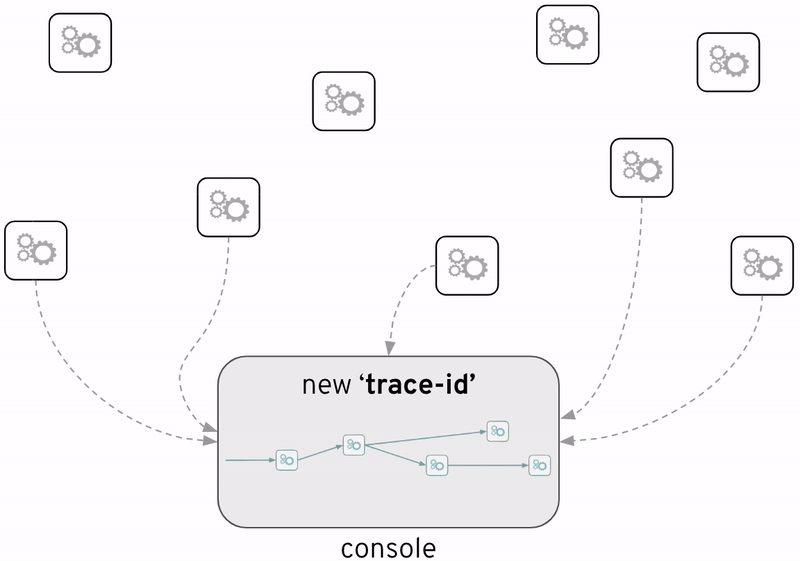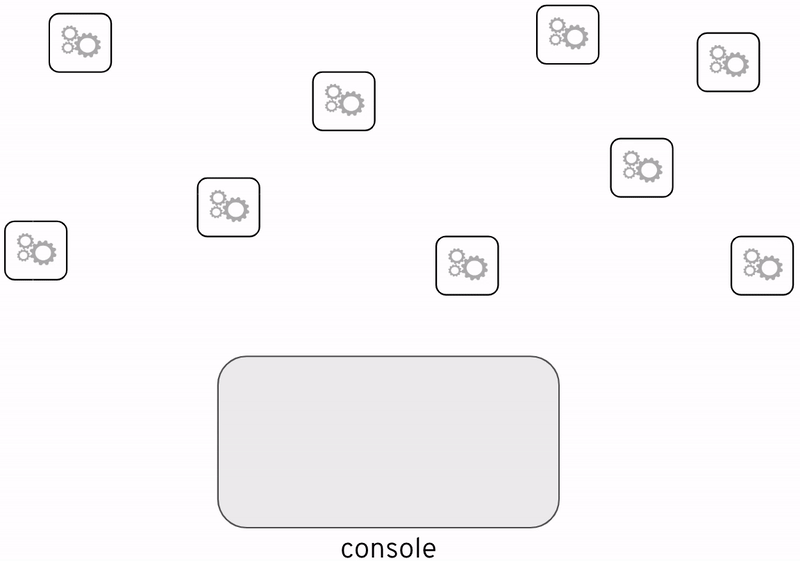
しかし、トレーサビリティ情報が可視化されてないと、誰も盲目感があります。アプリケーションのソースコードには、入力データに対して後続処理の経路を明確していますが、実際の実行時では、分岐が起きたら、個別のデータの処理経路を追跡する手段が失います。
また、トレーサビリティの最大の課題は、プログラミング言語とテクノロジに依存ぜず、共通に利用可能なトレーシング情報を生成することです。この課題は、自由に実行エンジン(プログラミング言語とテクノロジ)の選べるコンテナ環境上でさらに深刻になります。
可視化 と 言語非依存 の課題に対する答えは、OpenTracingプロジェクトにあります。OpenTracingプロジェクトは、テクノロジ、開発言語に依存しない、トレース情報を生成するための共通仕様とフレームワークを策定しています。
インテグレーションのアーキテクチャ上、トレース情報はHTTPに限らず、他の通信プロトコルでも行き渡る必要があります。メッセージングはこの良い例です。あるインテグレーションがHTTPエントリポイントとして公開する必要があるが、トレースに関心あるのは、疎結合されたアプリケーション同士の非同期メッセージ送受信の部分であるかもしれません。トレースの目的は、個別のデータ処理に関連するすべてのシステムの全体像を把握することです。この目的を達成するには、トレース情報をメッセージングの通信プロトコルでも通過できるでなければなりません。
2.5. サービスメッシュに関して
サービスメッシュという用語は最近非常に人気があります。もちろん、一連のサービスは、厳密に言えば、独立したエンティティとして展開されて、関連サービスの集合体に他なりません。
しかし、ここでの説明は、サービスの集合体についてのではなく、サービス集合を管理しやすく、開発者や運用者の負担を軽減するために、サービス集合の下のレイヤに存在する”wired”サービスメッシュを対象にします。これは、サービスの数が増えるにつれて、トレースがより重要になります。
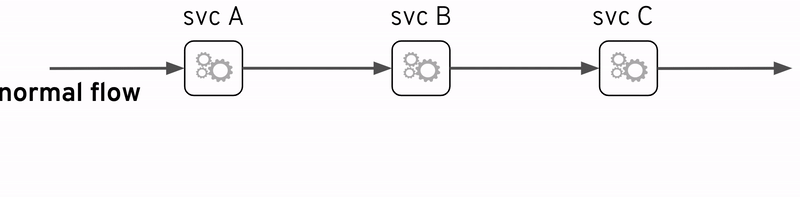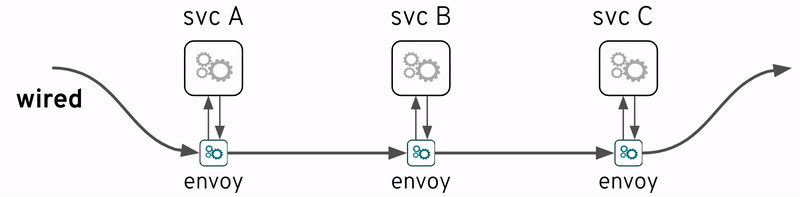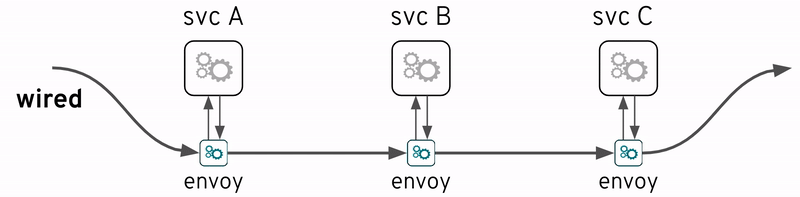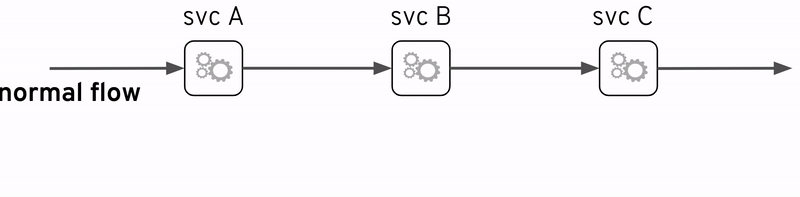
サービスメッシュの重要な機能の1つは可観測性であり、したがってこの説明と非常に関連性があります。おそらく最も有名なサービスメッシュ実装例はIstioプロジェクトである、Istioの中にも前述のオープンソース技術(OpenTracingとJaeger)が含まれています。
しかし、2つの主な理由から、ここではIstioを深堀りしません。 - 1つ目の理由は、この記事の目的は、一般に可観測性機能を最大限に活用する方法にフォーカスしたいことです。 - 2つ目の理由は、現在のIstioの場合、主にHTTP通信に焦点を当てており、マルチプロトコル通信が容易に適応できません。
IstioプロジェクトはHTTPプロトコル以外の領域にも推し進めようとしています。その一例が、Red Hatの同僚であるAlain Conwayの仕事です。彼はAMQPエンドポイントとの統合に取り組んでいます。これにより、多くのユースケースが適応できるようになります。詳細については、envoy-amqpを参照してください。
3. ケーススタディ(導入前)
可観測性がもたらすメリットを説明するために、実際の経験に基づいたケーススタディを紹介しましょう。
今回のケースは、未知の障害が収益損失を引き起こし、それによってビジネスに影響を及ぼしているような重大な状況の1つ例です。
パートナー(サービスの利用者)からクレームが上がってきました。クレームの内容は、システムに送信した「支払い」リクエストに対し、一部だけ、正常に「支払い処理」されていませんでした。ところで、「支払い処理」の行うシステム上では、遅延もエラーも発生したことなく、エンドツーエンドでも正常な状態です。
このようなシナリオでは、すべてのダッシュボードは正常に見え、エラーコードが返されず、エラーログも生成されません。この動作は、複数チームや複数製品の管理者に属するさまざまなサービスが混在する本番環境だけで見られるため、解決するのが難しい問題です。運用担当者がクレームを受けたとき、最初に、「支払い処理」のバックエンドシステムの運用チームに連絡しましたが、やはりそこではエラーもアラートも見つけられませんでした。
あなたはおそらくこう思います -お客様がシステム運用者でさえ分からない異常を報告している。こんなことであり得るか?- 。
それに答えるため、背景をもっと説明ましょう。
何年も前に、メインのバックエンドの「支払い処理」サービスはすでに存在していました。すでに多くのパートナー(サービス利用者)が利用していました。そして、新しい機能追加の業務要件がありました。設計時は、既存の「支払い処理」サービスを変更せず、コンポジットサービスで新機能対応で既存サービスの前段に増設しました。この設計により、同社は既存パートナーや顧客がコード変更せず、サービスを継続利用できるようにもなりました。
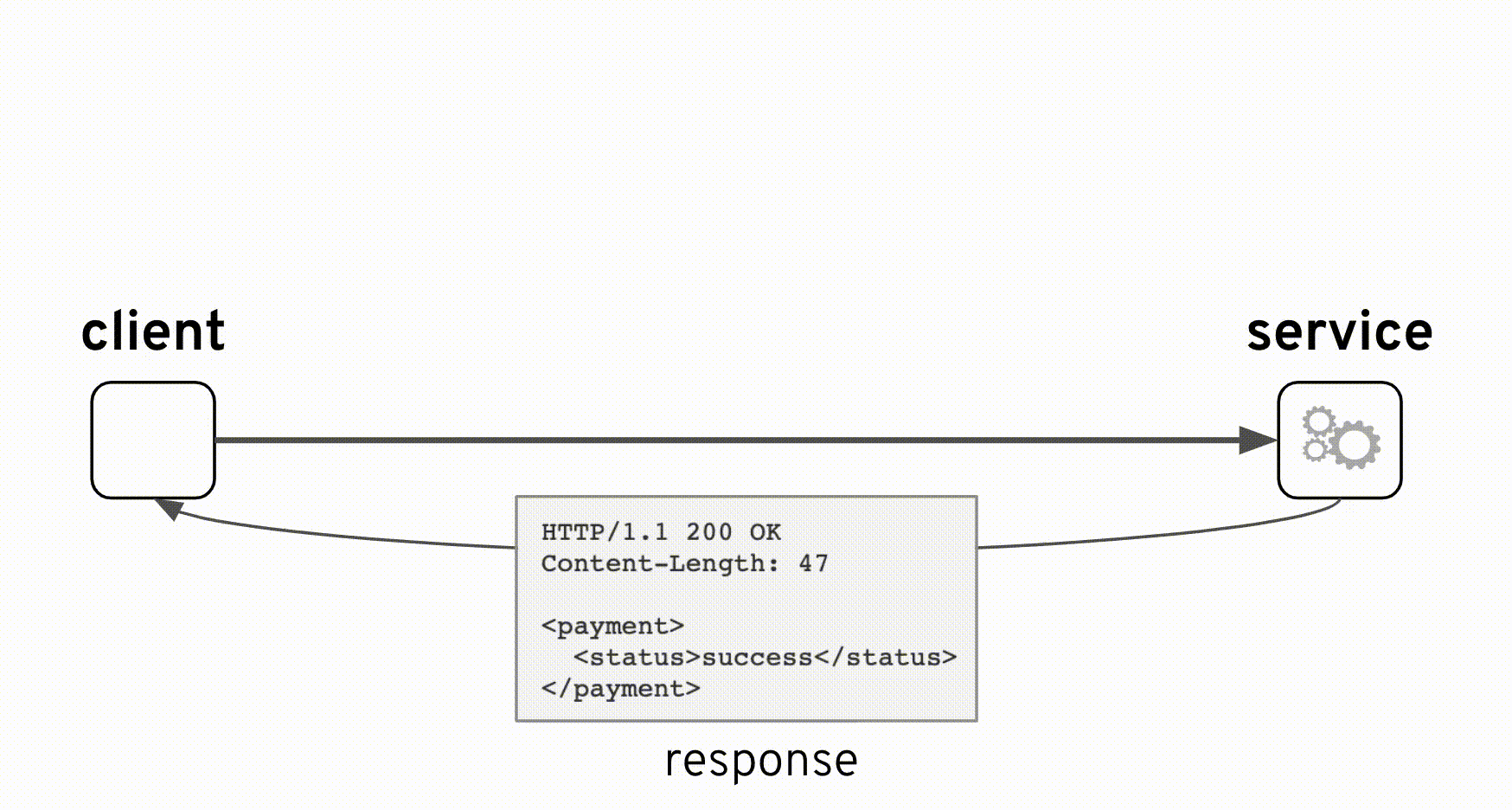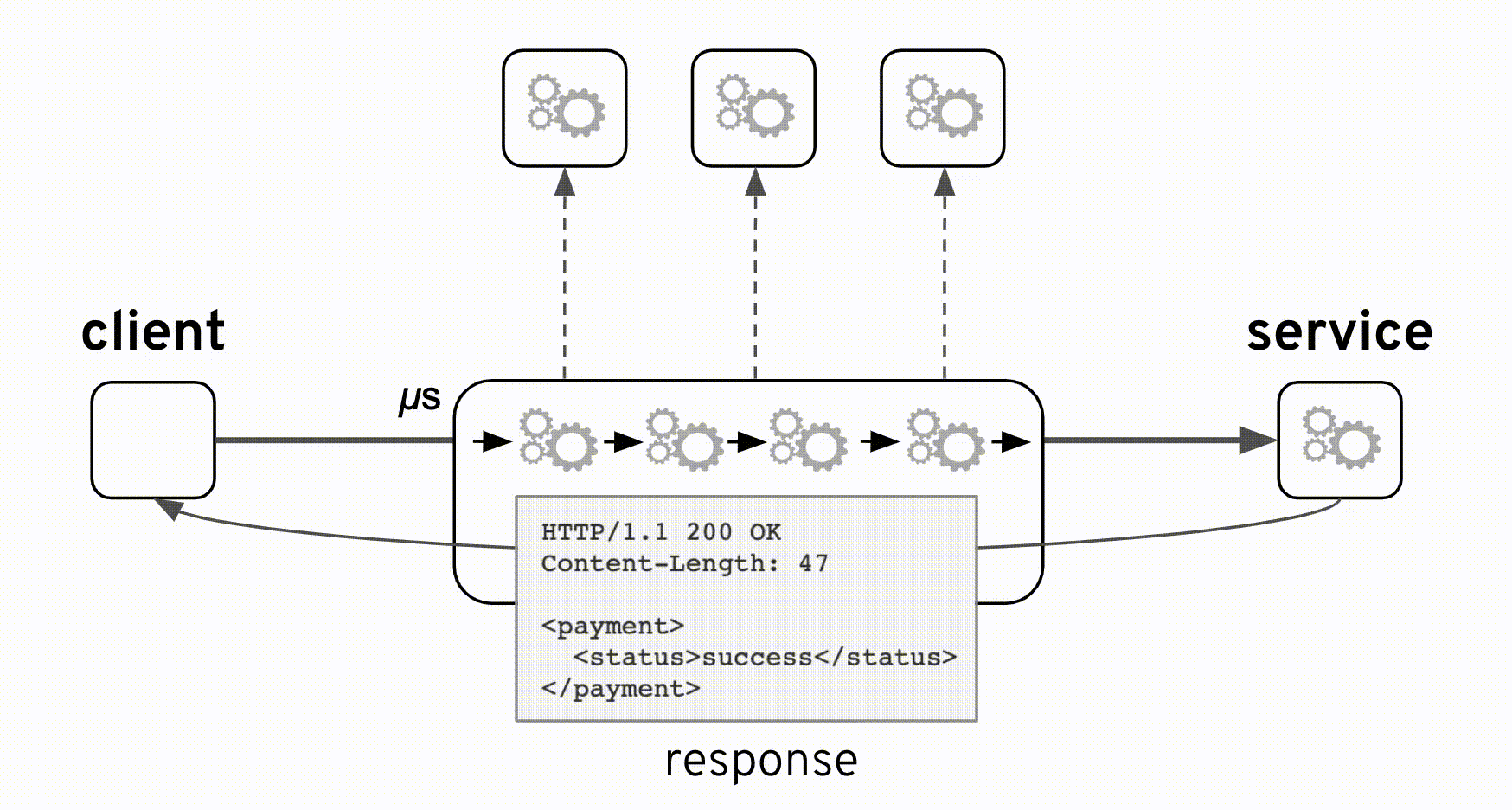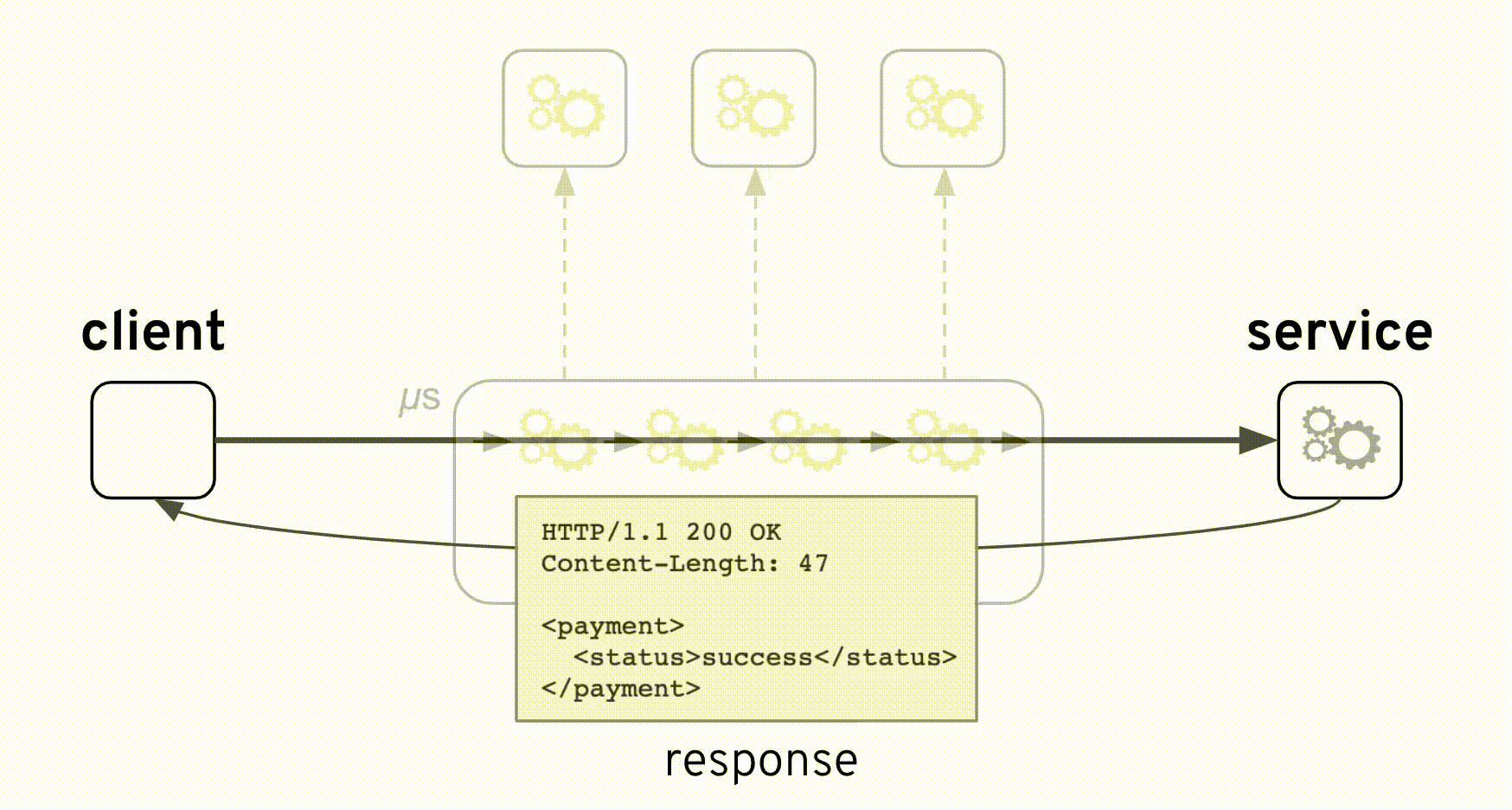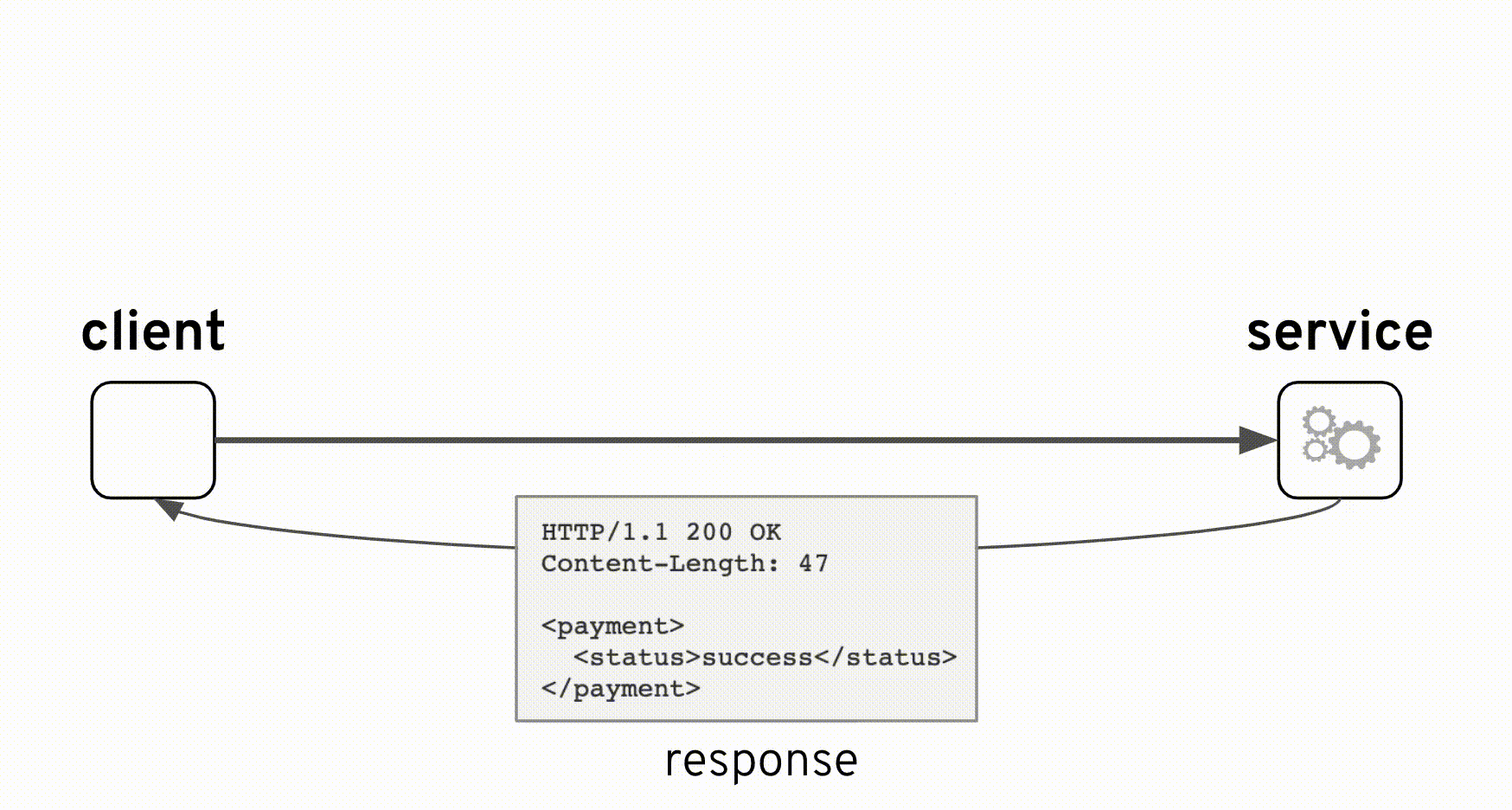
当時の設計は正しいです。上図のアニメーションから、コンポジットサービスを追加しても元のインタフェースが影響されないことを理解できます。コンポジットサービスでは、バックエンドが常にHTTPコード200(HTTP成功)で応答するパススルーとして実装されました。しかし、本当の '処理結果'の識別は、応答ペイロード内の <payment>/<statuts> フィールドであり、 'success'または 'failure'の値で判別する必要があります。バックエンドは両方の値が正常なシナリオと見なしています。つまり、'failure'は異常ではなく、「残高不足」が原因かもしれません。
システムエラーは一般的に何かが予想通りにうまくいかなかったことを示しますが、「支払い」の成功または失敗はどちらも予想されるユースケースです。他の例で、システムがディスクへの書き込みしようとしたとき、領域不足のためにこの操作が失敗した場合、例外が発生し、これはシステム上のエラーとして扱われます。
この考え方を念頭に、例のシナリオに戻ると、サービス利用者は「支払い処理」成功を期待していましたが、その代わりにコンポジットサービスから返ってきた応答は次のとおりでした。
HTTP/1.1 200 OK Content-Length: 47 <payment> <status>failure</status> </payment>
取得したレスポンスはペイロードを含む正常なHTTP通信データです。これで、「支払い処理」されてないと報告されても、システム上にアラームや赤信号も発しなかったことは理解できます。
システムの運用担当者にとって、入り口で受けたHTTP通信が健全のように見え、バックエンドシステムも正常に働いているように見えます。さらに、残念ながら、セキュリティ上の理由から、システム上に通過したデータ(IDフィールドなど)は暗号化されており、不正データを特定することも不可能であるため、サービス利用者とシステム運用側はこれ以上の連携ができませんでした。
このような状況でチームが詳細に調査できるようには、優れた可観測性戦略が必要です。このため、いくつかの技術的な説明を続けていきます。そのあと、解決の道筋を見つけるためにこの問題シナリオを再度取り上げます。
<続きは次回以降に掲載させてください>