皆さんこんにちは、ソリューションスペシャリストの井上です。今回はAI/MLの世界で重要度が増してきているMLOpsについて解説してみたいと思います。
なぜ今AIが必要か?
いままでは世界の変化が緩やかで、過去データを分析すればおおよその未来予測はできました。
ところが今は変化が早く過去のデータがあまり役に立たない状況も出てきています。最近の例では新型コロナがありますね。「データには鮮度がある」という言葉を痛感することも多いのですがもちろんそれだけではありません。例えばZaraなどのFast Fashionに代表されるFast Inventoryモデルは従来のように1年前のデータから流行や在庫数を予測するのではなく、もっと短期間で売れる服を作って売り切るモデルで、最近このようなビジネスモデルが増えてきています。
そのために必要なリアルタイムデータを短時間で分析したり、リソースがなく利用していなかった過去の膨大なデータの分析などは、今までのように人がやっていては到底間に合いません。そこでそれをマシン(AI/Machine Learning(以降ML))に実行してもらう必要性があるということです。

それならAI/MLをやってみよう! となるわけですが、なんとなく始めるのはお勧めしません。
87%のAI/MLプロジェクトが実用化されていない!?
その理由はこの数字が物語っています。87%というのは2019年7月にサンフランシスコで開催されたTransform 2019というイベントで提示された、AI/MLプロジェクトの失敗率です。 ここ数年で多くの企業がAI/MLの部署を作ったり、プロジェクトを立ち上げたりしています。デジタルトランスフォーメーションの実現にはデータの活用が不可欠で、それを飛躍的にAI/MLが推し進めることを期待されているのですが、実際には多くのAI/MLプロジェクトが道半ばで挫折しています。
なぜ多くのAI/MLプロジェクトは失敗するのか? その理由は4つ、人材不足、インフラとアプリの陳腐化、コラボレーションの欠如、そしてデータのサイロ化です。
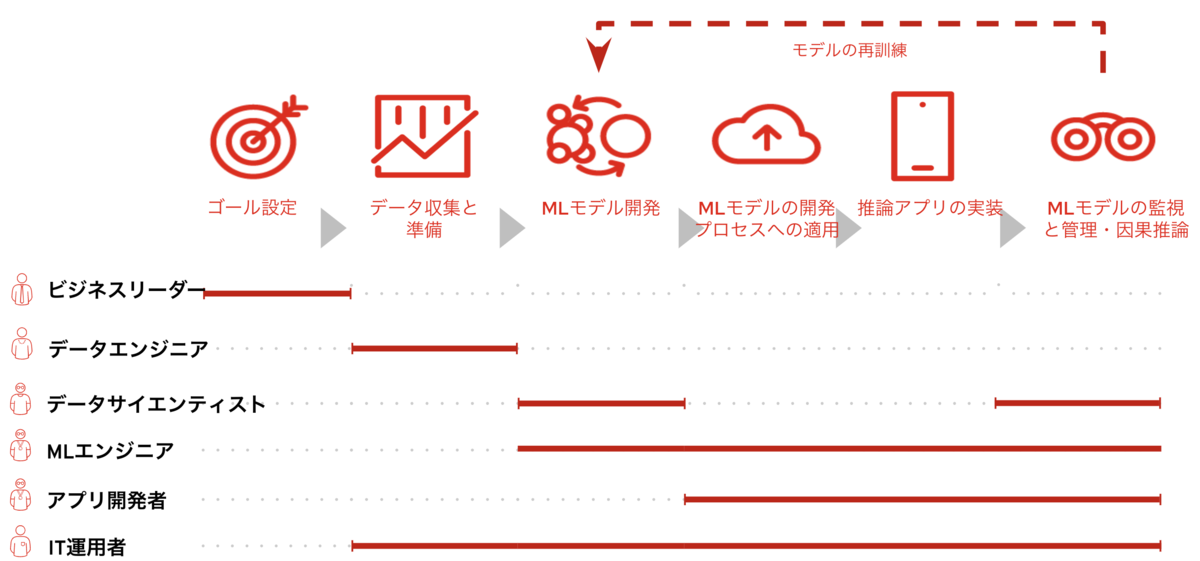
1.人材不足
まずは人材の問題から考えてみましょう。AI/MLプロジェクトを継続的に使えるモノにするには以下のようなプロセス、人材が必要だと言われています。「いやいや、成功するかもわからないのに最初から大きな投資はできないよ」という意見はもっともだと思います。でも実際に成功しているケースでもスモールスタートで始めているところも結構あるのです。では何が違うのでしょうか?その差は最初からAI/MLのライフサイクルとペルソナを意識して取り掛かっているかどうかだと思います。例えばAI/ML成功の秘訣は優れたMLモデルの開発ではなく、MLモデルの継続的評価(Causal Inference : 因果推論)とそれに基づく再訓練の仕組みをきちんと設計することだったリします。また人材についてもデータサイエンティストを採用してその人に全部任せっきりだったりすると、生産性が低下して肝心のAI/ ML開発が進まず成果が出なかったりします。一部のオールマイティ型のデータサイエンティストであればこのライフサイクルを自分自身で対応できるかもしれませんが、そのようなスーパーデータサイエンティストは希少でしょうし、実際に運用を始めたときにはスケールできません。結果として本業のMLモデル開発に割く時間が短かくなり生産性が落ちてしまうことになりかねません。そのためそれぞれのペルソナが自分の業務に集中できる環境の構築と、スケールできるプロセス設計が重要になります。
2.インフラとアプリの陳腐化
2つ目はインフラとアプリの陳腐化です。 よく見かける光景として以下のようなものがあります。
- それぞれのデータサイエンティストが自分で環境を構築・運用、インフラ部門も期待通りの環境の提供が困難
- リソース共有ができていないためGPUのリソースも無駄が多い
- すべてがマニュアルプロセスで非効率、オペミスによる手戻りも多い
- MLモデルのアプリ実装も時間がかかる
- セキュリティは常に心配
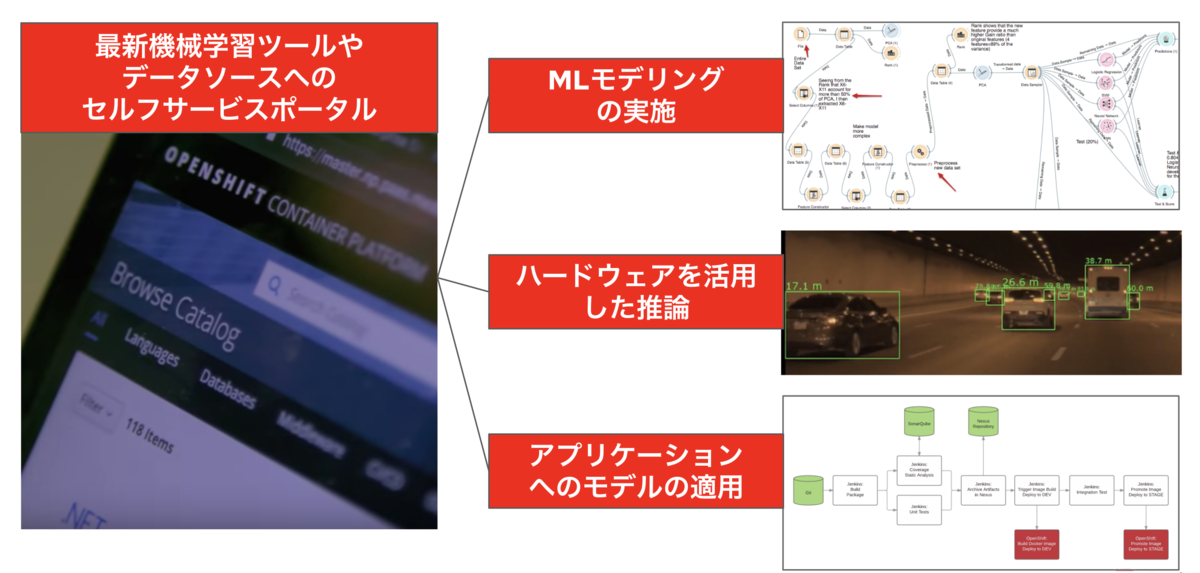
上記のいくつかは心当たりがある方も多いのではないでしょうか?このような課題を解決するのはセルフサービス化です。例えば以下のような環境があるとどうなるでしょうか?MLモデルの開発・テスト・リリース、学習に必要なGPU等のハードウェアアクセラレータリソースの自動的な割当、MLモデルのアプリ側への実装・テスト・リリース、そしてMLモデルが現実世界で及ぼす結果の継続的モニタリング。これらすべてが1つのポータルで実現でき、プロジェクトに新たに参加したデータサイエンティストにも同じ環境が即座に用意できるとしたら生産的ですよね。もちろんプロジェクト個人に合わせたデータ、アプリも個人で選択することが可能ですし、それらのアップデートも自動でやってくれるのです。このような環境を最初から準備することは後々プロジェクトを本格稼働する際にとても重要になってきます。
3.コラボレーションの欠如
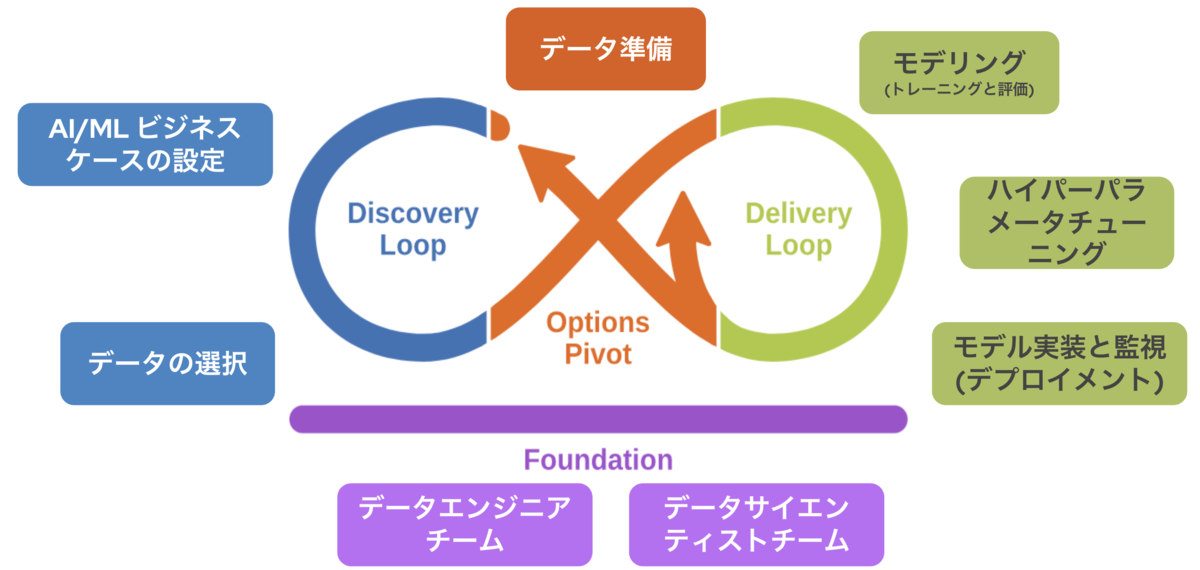
3つ目はコラボレーションの欠如です。最初のAI/MLライフサイクルの図で示しましたように、AI/MLライフサイクルには複数のペルソナが介在します。そしてそれぞれが自分の役割を果たすために複数のペルソナとのコラボレーションが不可欠となります。例えばデータサイエンティストは必要なデータを入手するためにデータエンジニアと打ち合わせをしたり、データのセキュリティやパフォーマンスを確保するためにインフラチームとも打ち合わせをする必要も出てくるでしょう。さらにはMLモデルの組み込みやリリースについてアプリ開発との打ち合わせも必要になります。往々にしてあるのはそれぞれが話す言葉が他のペルソナにはちんぷんかんぷんだったり、一見簡単に思われる要求が実は様々な制約があり簡単には実現できなかったりするということです。そこでMLワークフローに必要なタスクとそこで使われる言語を標準化し、それぞれのやり取りを自動的に行えるようにするプロセスを実現します。このプロセスはMLOpsと呼ばれます。MLOpsについては次の章で説明します。
4.データのサイロ化
4つ目はデータのサイロ化です。データがサイロ化する原因は何でしょうか?必要なデータがどこにあるかわからない、データフローが分断されてアクセスできない、データが大きすぎて移動ができない、原因は多々あると思いますが、S&P Globalが2023年に451社のエンタープライズ企業に行った調査(非公開)によると、90%の顧客がAI開発に必要なデータはあると回答しているにも関わらず、62%がデータアクセスが重要な課題だと答えていることが明らかになっています。その内訳としては、「データは貯めるだけ貯めたが何に使ってよいかわからない」、または「データを活用しようにもデータ変換ができない」、「タイミングよくデータが収集できない」といったことが考えられると思います。それらを解決するには以下の3つの取り組みが必要だと考えています。
- データを変換する仕組みをタイムリーに実装する
- バッチデータのストリーミング化
- アジャイル的なアプローチ
まずは「1. データを変換する仕組みをタイムリーに実装する」ことを考えてみましょう。ここでよく使われるのはApache Camelというオープンソースのコンポーネントベースのルーティングエンジンがあり、各種プロトコルから各種プロトコルへの変換、データ変換を行います。さてここで「タイムリーに実装する」というところがミソなのですが、このCamelのコンポーネントをコンテナ化して、マイクロサービス化をしておくことで、既存のデータ変換の部分は変更を加えることなく、新しいデータ変換機能を追加できます。またKubernetesでコンテナ群を管理することにより、新しく追加したデータ変換コンポーネントのデータ量に追従したオートスケールができたりもします。実際にこのアーキテクチャはすでに基幹システムでも導入されている事例なのです。 次に「2. バッチデータのストリーミング化」ですが、ここではApache Kafkaがよく使われます。例えば機械学習モデルを最適化するために複数のデータを関連付けるとしましょう。いくつかはほぼリアルタイムにサンプリングが可能ですが、残りはバッチ処理、または更新タイミングが非常に遅かったりします。その場合ある特定のタイミングで関連性があるかを見極めることができないため、質の高い予測モデルを開発できないことも考えられるでしょう。Kafkaは非常に優れもので、データキャッシュとストリーミングの両方の特性を兼ね備えています。よく例えられるのは映画のフィルムです。連続したデータをタイムリーに取得できるだけでなく、過去に遡ってデータをキャプチャーもできるのです。では多くの開発者が同じデータにアクセスしたとしたら?データソースが追加されたりサンプリング周期の変更で一気にデータ量が数十倍になったら?そんな状況にも対応できるように設計されているのがKafkaの特徴です。更に前述したようにこれをコンテナ化してKubernetesで管理すると、自律的にスケールや修復もしてくれるようになります。 最後に「3. アジャイル的なアプローチ」ですが、個人的にはこれがいちばん重要なのではないかと考えています。そもそもデータサイエンスは探索と深化を繰り返す作業でもあります。データを全部揃えてから分析するのではなく、揃ったデータから分析をスタートして、足りないデータがあればどんどん上記のCamelやKafkaのようなコンポーネントを追加して行けば良いのです。そのときに重要なのは常に結果を確認できるすべがあり、そのフィードバックを開発のループに戻せるようにしておくこと、継続的にこのループをできるだけ早く回すチーム体制も必要でしょう。
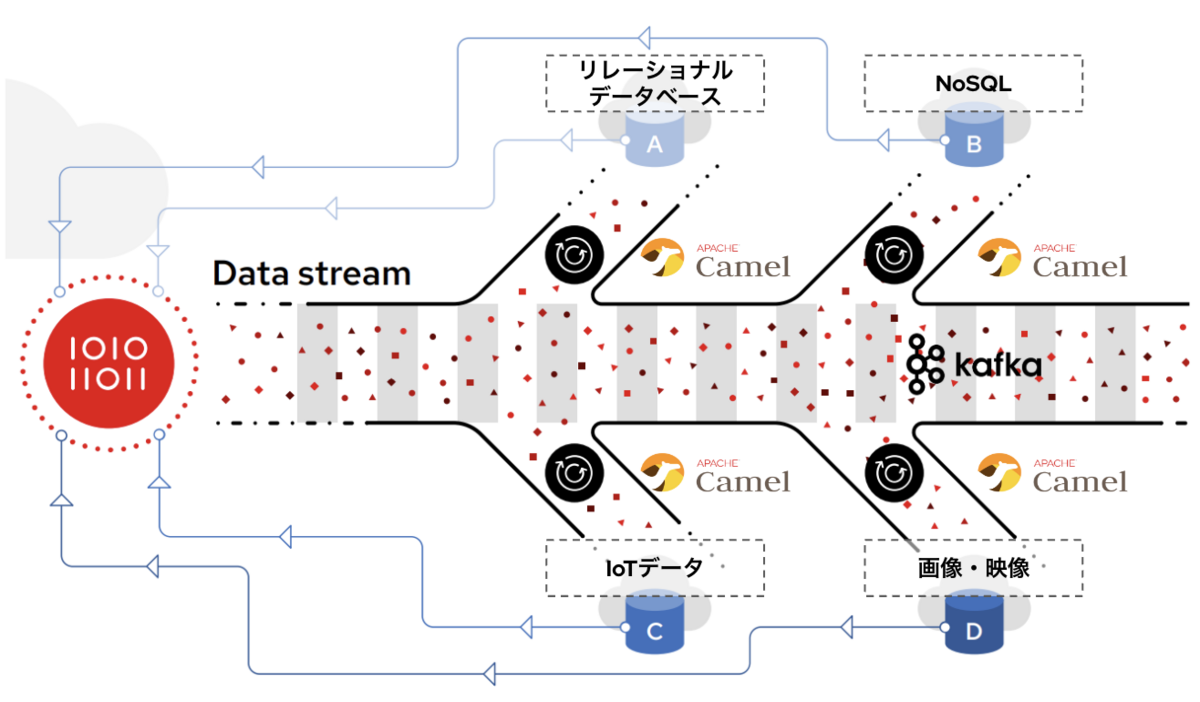
さてこれらを組み合わせるとなにができるのか? 一つの例を紹介したいと思います。それはリアルタイムデータフローです。前述しましたようにMLモデルは鮮度が重要です。一週間に一度のバッチ処理で得られたインサイトからビジネス計画をねっていても後手後手に回ってしまいます。それはビジネス機会の損失、さらにはコストとリスクの増大にも繋がります。すでに現代ではリアルタイム処理が一般化しておりそれはAI/MLの世界でも例外ではないのです。ではリアルタイム処理を実現する技術としては何が必要なのでしょうか?ここでは以下の3つのコンポーネントを紹介したいと思います。
- バケット通知ができるオブジェクトストレージ Ceph
- ストリーミングデータ処理をする Kafka
- イベント駆動のサーバーレス KNative
この3つを組み合わせてできるリアルタイム処理はイベント駆動型と呼ばれていて、以下のような流れで動作します。この例は肺のレントゲン写真からの敗血症の患者の早期判断をするシステムですが、新型コロナの早期発見・対応にも応用できることは言うまでもありません。(データ変換のCamelは例えば「個人情報の削除」等の機能で使用されていますが、この図では記載を省いています)
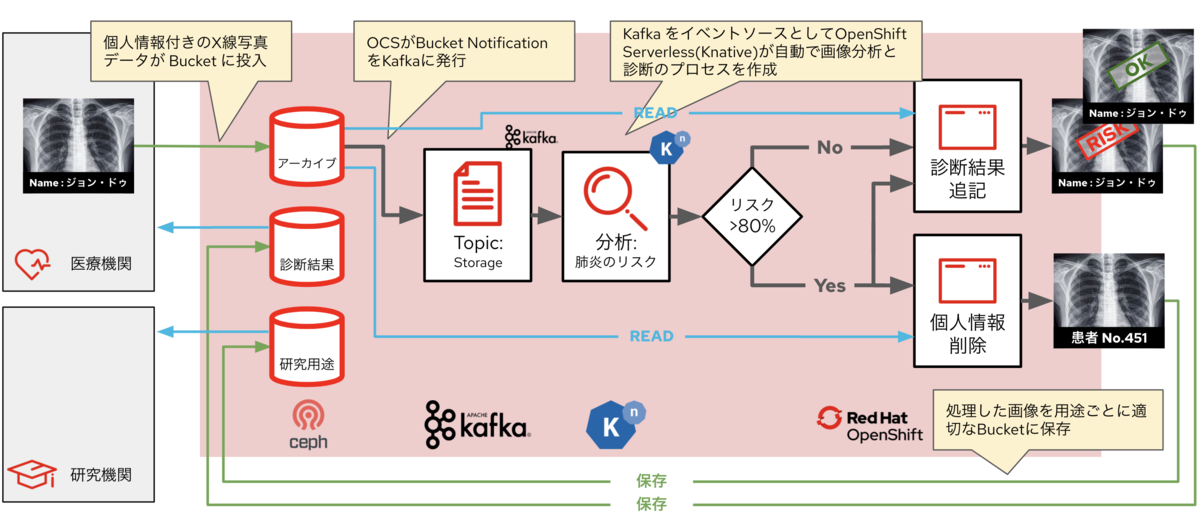
MLOps - AI/ML活用をリアルワールドで実現する
さて、前の章でMLOpsについて触れましたが多くのみなさんが「これどこかで見たことがある!?」と思われたのではないでしょうか?それもそのはずMLOpsはDevOpsのML版だからです。MLOpsという言葉が使われたのは2018年のGoogleのイベントが最初と言われていますので、Googleから引用しますと、「MLOps は、ML システム開発(Dev)と ML システム運用(Ops)の統合を目的とする ML エンジニアリングの文化と手法です。」ということになります。そしてMLOps を実践すると、統合、テスト、リリース、デプロイ、インフラストラクチャ管理など、ML システム構築のすべてのステップで自動化とモニタリングを推進できます。
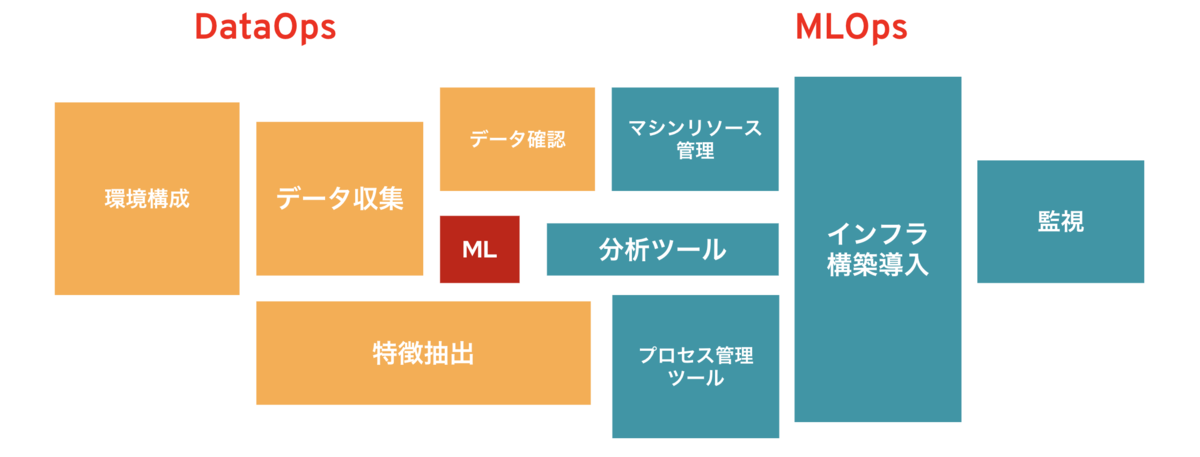
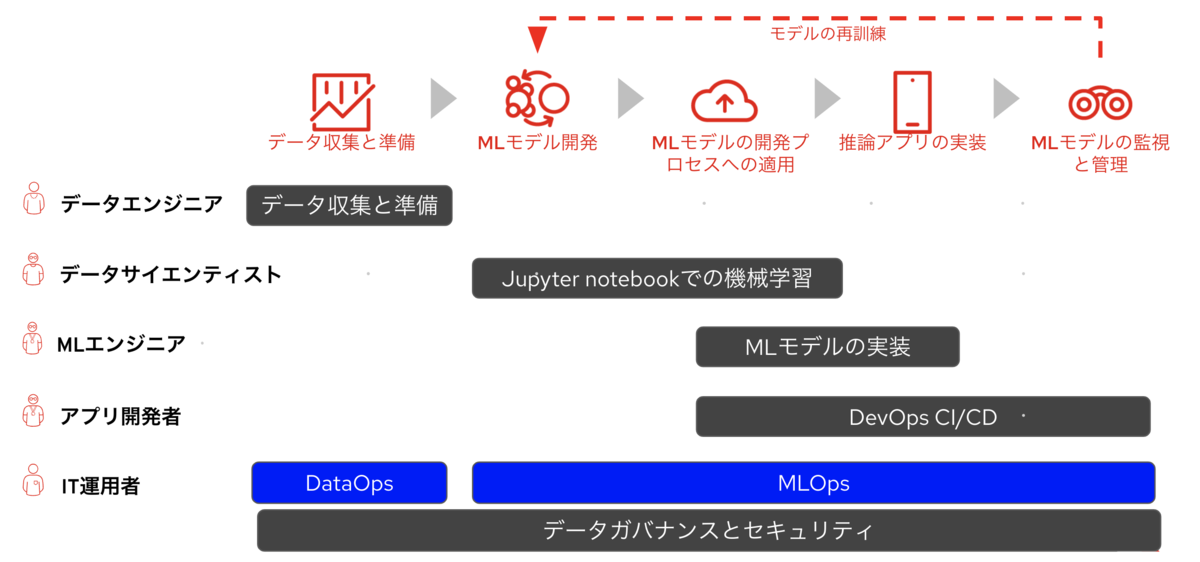
すでに解説してきましたようにML開発自体はMLモデルを実際に活用するための小さな一つのピースに過ぎません。そのモデルをできるだけ早く開発、リリースし継続的にフィードバックして再学習するループを高速に回すためにはMLOps、DataOpsがとても重要になってきます。 そしてこれらを取り入れることでAI/MLのワークフローは以下の図のようにとてもスッキリします。 最も重要なのはここでは最初に提起した4つの課題が解決できていることです。
人材不足:セルフサービス化によりそれぞれのペルソナが自分の仕事に専念し生産性を最大化できる
インフラとアプリの陳腐化: 常に最新の開発・テスト環境が提供されている
コラボレーションの欠如:ペルソナ間の無駄な打ち合わせとコミュニケーションミスの低減
データのサイロ化:データ管理の一元化とリアルタイム対応によるデータの流動性向上
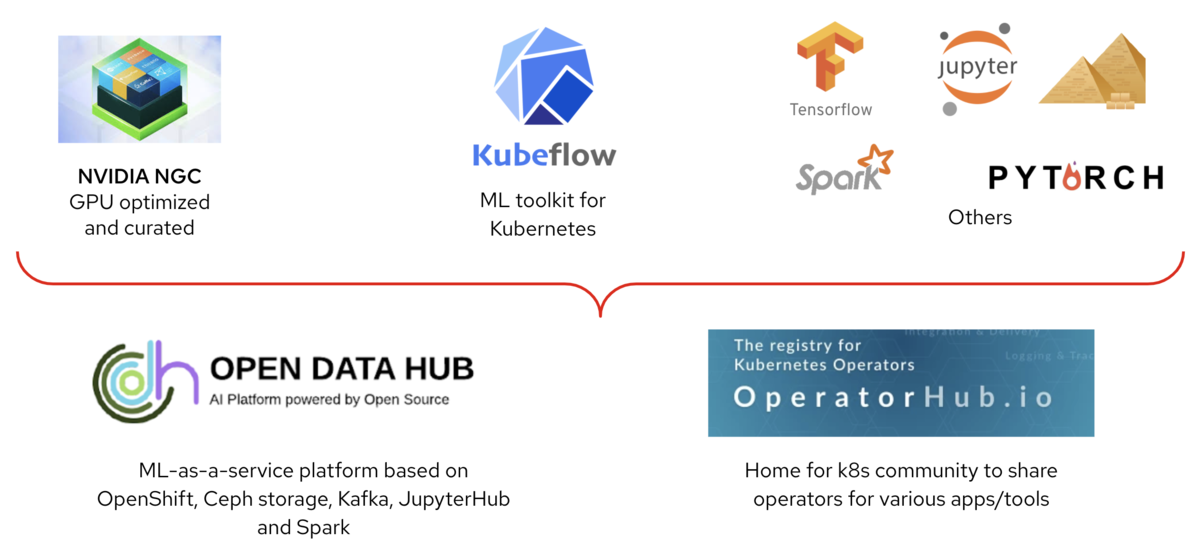
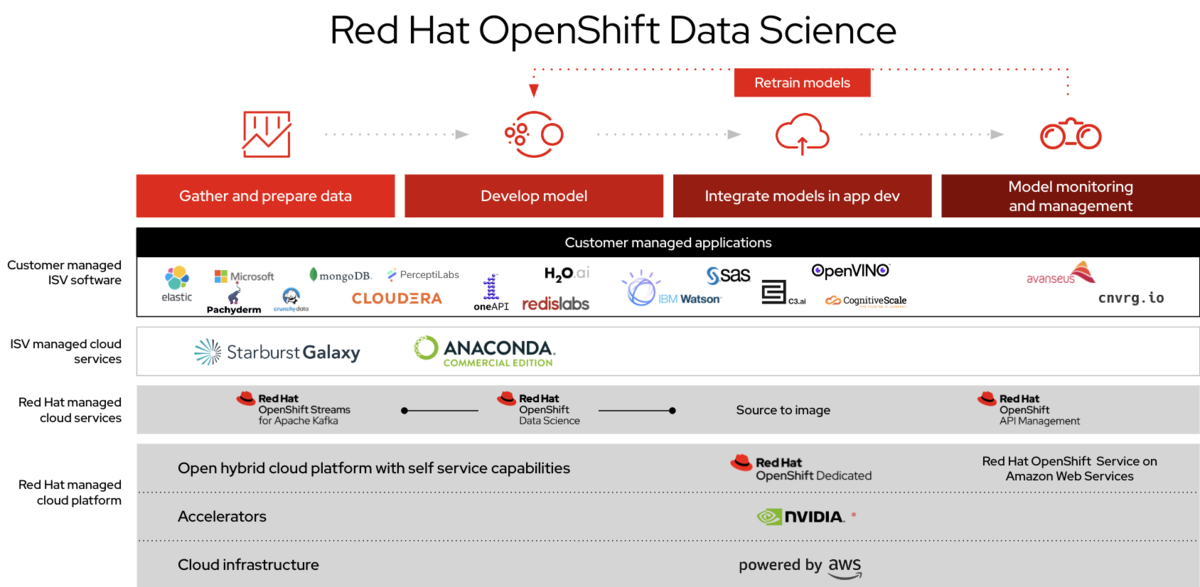
とはいえAI/MLの世界で利用されているコンポーネントはほとんどがOSSです。それを一つ一つ選択、管理していくのは時間のかかる作業ですしスケールすればするほど生産性も落ちていきます。そのため主なOSSを一つのプラットフォームにまとめたソリューションが必要とされてきました。いわゆるML as a Serviceです。レッドハットがリードして開発しているオープンソースフレームワークOpen Data Hub(以降ODH)は以下のようなAI/ML開発に必要なコンポーネントをコンテナ型のサービスで提供するオープンプラットフォームで、オープンソースのAI/MLツールの開発・運用を自動化・セルフサービス化を実現します。
さらにこの環境をオンデマンドで提供できるクラウド型もあります。Red Hat OpenShift Data ScienceはAWS上で簡単に利用が可能になっています。
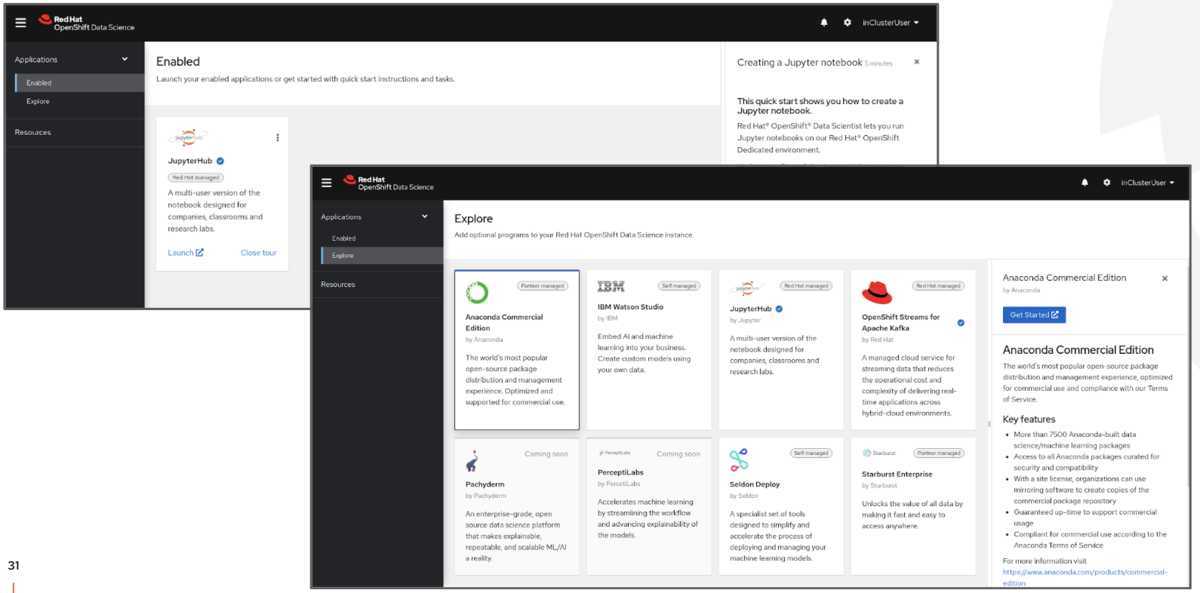
また、まずは体験してみたいという方にはSandboxも提供していますのでぜひお試しください。
ユーザー事例
最後にいくつかユーザー事例を紹介したいと思います。適切なAI/MLの実装をすることにより、あらゆる分野で大きな効果が実現できています。このBlogでは詳細の説明は割愛しますがご興味があればRed Hat担当者までご連絡ください。
・ロイヤルバンクオブカナダ銀行(不正検知) (英語)
- 1300万レコードを20分で分析
- 数日で新しいMLモデルを更新
- 従来の10倍のトレーニングが可能に
・ExxonMobile(MLセルフサービス)
- 1つの共通プラットフォームを130チームで共有
- 年間プロジェクト数が10倍に
- データサイエンティストはMLモデル開発に集中
https://www.redhat.com/ja/success-stories/exxonmobil
・BMW(自動運転システム開発)
- 230PBのデータ分析基盤を3ヶ月で構築
- 9万コアのGPUクラスターの設定を自動化
- レガシーアプリもOpenShift上で活用
https://www.redhat.com/ja/success-stories/bmwgroup
・HCA(敗血症の早期検出)
- 1日あたり3万人の患者をモニター
- 治療にとりかかる時間を5時間短縮
- ヒット率が3.3%から92.2%に向上
https://www.redhat.com/ja/success-stories/hca-healthcare
関連記事