こんにちは、ソリューションアーキテクトの蒸野(ムシノ)です。
今回は「AMQ Streams」のベースとなっている「Apache Kafka」の超概要を説明をしたいと思います。
Apache Kafka とは
2010年にLinkedInで開発され、2011年にLinkedInから公開されたオープンソースの分散メッセージングシステムです。 Apache Kafkaはストリームデータのために設計された分散システムであり、大量のログやイベントデータなどの大量のデータをハイスループット/低レイテンシで収集・配信することが目的で、スケールアウト、対障害性、分散データストリーム処理やイベントドリブンアプリケーションを可能にします。
Apache Kafka の公式ドキュメントでは次のように示されています。
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Apache Kafkaは、オープンソースの分散型イベントストリーミングプラットフォームであり、高性能データパイプライン、ストリーミング分析やデータ統合、ミッションクリティカルなアプリケーションのために、多くの企業で利用されているというところでしょうか。
上記の概要や文面からだけではどんな用途で使うのかいまいち分かりにくいですね。弊社では概ね次のようなユースケースで説明しています。
メッセージング
既存のメッセージングブローカではできなかったハイスループット、パーティショニングによる分散管理とレプリケーション、フォールトトレランスによる強力な耐久性を実現。
メトリクス収集
分散したアプリケーションの統計情報集約や複数のデバイスからオペレーションデータの統計情報を継続的に集約を実現する。
ストリーム処理
ストリームの処理や継続的なリアルタイムアプリケーションを実現する。
Webサイト行動追跡
リアルタイムでユーザアクティビティトラッキングを行うデータパイプラインとして実現する。
ログ集約
ログデータを集約する。ハイスループットで高い耐久性とレプリケーションによる対障害性を提供するためログの欠損を抑止。
データインテグレーション(データパイプライン)
イベントやストリームデータをキャプチャし、別のデータシステムに送付するデータパープラインとしてのシステム統合に実現する。
分かりやすい具体例としてこちらでは下記のようなものも紹介されています。
- 証券取引所、銀行、保険などの金融取引をリアリアルタイムで処理するケース。
- 自動車、トラック、船隊、出荷を、物流や自動車業界などで、ニアリアルタイムで追跡および監視。
- 工場や風力発電などの IoT デバイスや他の機器から、センサーデータを継続的にキャプチャ。
- 小売り、ホテル、旅行業界、モバイルアプリケーションなど、顧客とのやり取りや注文を収集し、即座に対応する。
- 企業の様々な部門で作成されたデータを接続、利用するようなケース。
- データプラットフォーム、イベント駆動アーキテクチャ、マイクロサービスの基盤として利用。
Apache Kafka の特徴
特徴として公式ドキュメントには下記のように記載されています。
HIGH THROUGHPUT
Deliver messages at network limited throughput using a cluster of machines with latencies as low as 2ms.SCALABLE
Scale production clusters up to a thousand brokers, trillions of messages per day, petabytes of data, hundreds of thousands of partitions. Elastically expand and contract storage and processing.PERMANENT STORAGE
Store streams of data safely in a distributed, durable, fault-tolerant cluster.HIGH AVAILABILITY
Stretch clusters efficiently over availability zones or connect separate clusters across geographic regions.
上記の要約、および補足するならば下記のようなことが言えるかと思います。
- Kafka自身分散システムであり、高スループット/低レイテンシである
- 大量のメッセージを扱うことができ、高速処理、高拡張性、高可用性にデザインされている
- メッセージはファイルとして保存され、かつクラスタ内でデータパーティショニングとしてレプリカが作成されるためデータの損失を防げる
- シングルクラスタで大規模なメッセージを扱うことができダウンタイムなしでスケールすることができ、大規模なコンシューマにも対応できる
Apache Kafka が生まれてくる以前の課題
ではなぜこのような特徴を持つKafkaが生まれてきたのでしょうか?Linkedinのレポートに詳細がありますが、おおよそ以下のような課題に対応したかったと記述されています。
- リアルタイムログのような多くのボリュームのイベントデータを取り扱うためにハイスループットを実現したい
- オフラインシステムからの定期的で莫大なデータロードを可能とする大容量バックログを取り扱いたい
- 伝統的なメッセージングのユースケースも取り扱いつつ、大量のデータも取り扱うことができるように低レイテンシである必要がある
- 当然のようにフォールトトレランスに対応しメッセージのロストを無くしたい
詳細は過去の記事に整理されていますので、こちらをご覧ください。 kenta-kosugi.medium.com
Apache Kafka の全体像
Kafka を説明する記事は多くありますので、ここではそれほど詳しく説明がしませんが全体像としては下記のようになっています。
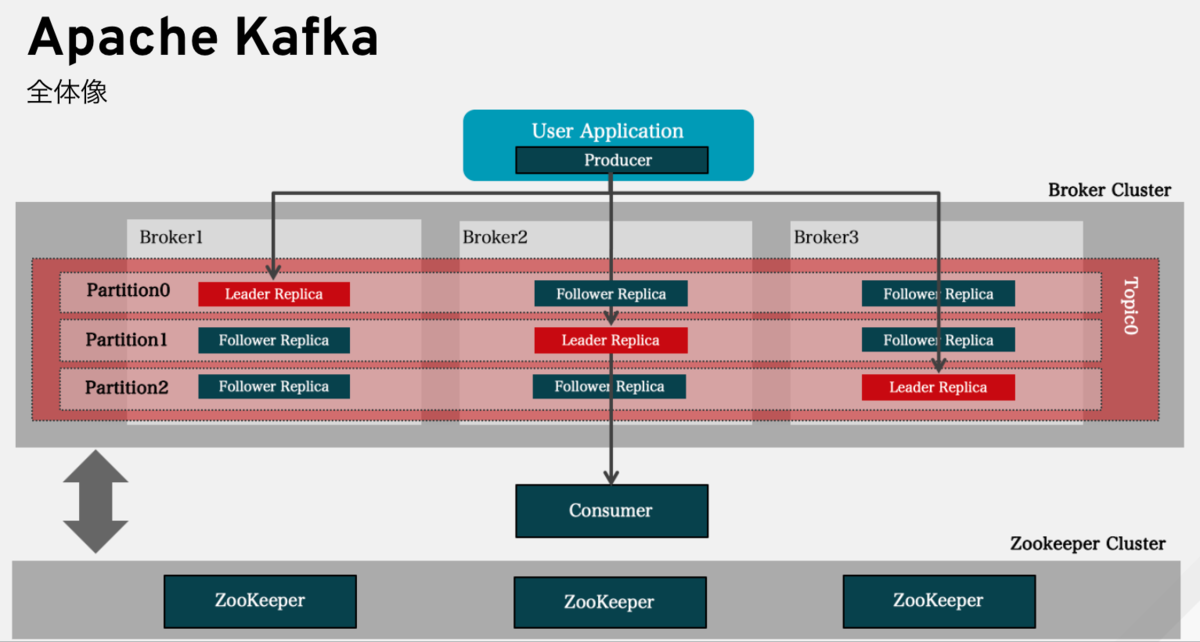
Kafka は、大まかに分けると「Broker」と呼ばれるトピックを使用してメッセージを配信するための中心的コンポーネントと、「Producer」「Consumer」と呼ばれるメッセージの送受信を行うJavaベースのクライアントのコンポーネントに分かれます。また、Brokerを管理するためのJava/Scalaベースのツールとしての「管理ツール」、「Kafka Connect」と呼ばれるKafkaと他のシステム間でデータをやり取りするためのフレームワーク、データセンターをまたがって構成されたKafkaクラスタ間でトピックのデータレプリケーションするためのツールである「Mirror Maker」とKafkaクラスタのノードおよびトピック/パーティションのステータスを管理するために使用されるKafkaクラスタ管理の「Apache Zookeeper」で構成されます。
メッセージはTopicという入れ物を通じて送受信され、Topicは複数のパーティションに分散され、Brokerに分散配置されています。Brokerはストレージレイヤー含むKafkaサーバとして機能します。 複数に分散しているパーティションですが、メッセージはリーダレプリカという1つのパーティションに書き込まれます。このパーティショニングはメッセージのキーに基づいて実施され、パーティション内の順序性は維持されます。Kafkaに接続しようとする場合、「Producer API 」「Consumer API」 もしくは「Kafka Connect」を利用して接続、他システムやデータベース等と統合します。ミッションクリティカルなユースケースを実現できるように、Kafka クラスタはBrokerのいずれかに障害が発生した場合、他のBrokerのレプリカがリーダレプリカに昇格し、作業を引き継ぎ、データを失うことなく継続的な運用を保証します。
Apache Kafkaのメリット
もう何度か特徴的なものは説明しているため、おおよその理解ができているとは思いますが、今一度改めてメリットを整理すると下記の様なことが言えるかと思います。
高スループット/低レイテンシである
Kafkaが生まれてきた背景にあるように大量のログや大量のイベントストリームに対応できることが求められた背景を考えれば、高スループット/低レイテンシであることは必然の要件でした。Kafka自身はpub/subではありますが、メッセージングモデルと若干異なる構成を取ることや設計段階からBrokerを複数台構成することを前提としていることから、スケールアウトをしやすいものになっています。このスケールアウトのしやすさはKafkaの高速性に寄与しています。
高速にデータ送達保証が可能
メッセージングを扱う以上、メッセージをロストしたくないというのは自然な要件であり、ミッションクリティカルで利用する以上必要最低限の要件とも言えます。 Kafkaでは、送達保証レベルを複数用意し「1回は送達を試みる」「少なくとは1回は送達する」「1回だけ送達する」これを選別するオプションを提供することでデータ送達保証の現実的な落とし所を推し量ることが可能です。
任意のタイミングでメッセージを利用できる
Linkedinではリアルタイムで活用するニーズの一方、一定時間でバッチ処理的に扱いたいニーズもありました。Kafkaではデータをメモリ上だけでなくディスクへ書き込むことで永続的な保存を可能にしています。それにより比較的大量のデータを保持することが可能となっています。またこれらのデータに対して、メッセージを呼び出した側はどこまで呼んだかを記憶することで任意のタイミングでメッセージを呼び出すことができます。
Kafkaを中心としたエコシステムへの拡大
KafkaのコンポーネントであるProducerとConsumerは分散構成が可能です。このkafkaとPublisherとConsumerと間を取り持つ接続用APIが重要になってきますが、このレイヤに対して「Kafka Connect」が提供されています。APIをユーザー側で開発するのは非常に手間がかかるので、豊富なAPIが提供されていることはKafkaをより活用しやすくしています。
これまでの Apache Kafka 関連記事まとめ
Apache Kafka に関する性能情報
LinkedIn が公表している時点(2019年)での情報でありますが下記のようなデータボリュームを扱うことができていると発表しています。
- Kafka のメッセージ処理量は 7兆件 / 日
- 4000以上のBrokerで構成し、100以上のKafkaクラスタ
- 10万件以上のトピックスと700万件以上のパーティションを運用
また、国内では2020年に LINE 社が比較的大きなボリュームで利用されていると発表しており、下記のようなボリュームを公表しています。
- 166を超えるシステムで利用(2018年には50システムで利用し、単一クラスタとしては世界最大のスケールと発表しています)
- 2500億件/日(2018年時点)
- 1500万件/秒
- 1.4ペタバイト/日
- サービスレベルは99.999(最も遅いレイテンシでも50ミリ秒)
AMQ Streams (Apache Kafka) に寄せられる代表的なQA
最後にAMQ Streams (Apache Kafka) でよく聞かれる質問について回答して締めくくろうかと思います。
パーティション/レプリケーションを複数持つメリットは?
パーティションを複数持つことにより冗長化ができ、高可用性が実現できることがメリットです。また、レプリケーションはパーティション単位で行われるため、レプリケーション対象のデータ量を小さくするという効果もあります。ケースバイケースですが、典型的にはトピック作成時にブローカー数の10倍程度のパーティション数を設定しておくことを推奨しています。これは将来スケールアウト等によるブローカー数の変更が発生しても偏りが起きにくくするためのプラクティスです。
ブローカに障害が発生した場合復旧手順の概要を教えてください
Kafkaブローカーは3台以上の物理サーバ上で内部に保存するデータをコピー(レプリカ)して冗長化を行います。万が一障害が発生した場合でも、残りのサーバで縮退して動作の継続が可能です。そのため、手動での切り離し作業は不要です。復旧手順もシンプルで、障害が発生したブローカーを再度起動するないしはブローカーを追加するのみです。また、OpenShift上でRed Hat IntegrationないしRed Hat Application Foundationsに含まれるAMQ Streams(エンタープライズ版Kafka)をご利用いただく場合には、ブローカー障害の検知・復旧や、ブローカー数の変更はOperatorによって自動化されます。
ブローカの構成数を稼働中に増やしたり減らす事は可能か?
可能です。ただし削除されたノードのパーティションのリバランスは自動的に行われないため、kafka-reassign-partitions.shスクリプトを使用して手動で行う必要があります。 https://kafka.apache.org/documentation/#basic_ops_cluster_expansion
メッセージの削除やコンパクションにおけるオーバーヘッドは存在するか?
メッセージの削除に伴うオーバーヘッドはありません。古いメッセージブロックを記録したファイルを削除するのみであるためです。 KafkaをKey Value Storeとして利用する場合には、コンパクション実行時にオーバーヘッドがありますが、このような用法はKafkaのメインユースケースではないため、実用上問題になることはあまりません。
Kafkaブローカーのオートスケーリングに対応しているか?
Kafkaアーキテクチャは自動スケーリングには適していません。Kafkaのクラスタをスケーリングするには、膨大な量のデータを別のBrokerに移行する必要があります。接続されているコンシューマーとプロデューサーのパフォーマンスに影響を与えない方法でこれを行うには、限られた速度でデータを移動させる必要があり、クラスタをスケールアップするのに数日かかってしまうケースが多くあり現実的ではありません。Kafkaのスケーリングには、長期的なメトリクスに基づく必要があり、これは運用者の複合的な判断に委ねることを推奨しています。
最後に
いかがでしたでしょうか? 今回は「AMQ Streams」のベースとなっている「Apache Kafka」の超概要として、特徴やメリット、生まれてきた背景、または、よく質問されるケースなどを取り上げさせていただきました。
参照リンク
- https://access.redhat.com/documentation/ja-jp/red_hat_amq/2021.q4/html/introducing_red_hat_amq_7/index
- https://kenta-kosugi.medium.com/apache-kafka-%E3%81%8C%E7%94%9F%E3%81%BE%E3%82%8C%E3%81%9F%E7%90%86%E7%94%B1-2a6f022b2935
- https://rheb.hatenablog.com/entry/2021/09/17/Red_Hat%E3%81%AEManaged_Kafka%E3%81%ABQuarkus%E3%82%A2%E3%83%97%E3%83%AA%E3%82%B1%E3%83%BC%E3%82%B7%E3%83%A7%E3%83%B3%E3%81%A7%E6%8E%A5%E7%B6%9A%E3%81%97%E3%81%A6%E3%81%BF%E3%82%88%E3%81%86%EF%BC%81
- https://rheb.hatenablog.com/entry/2020/07/06/Apache_Kafka_on_K8s%28Strimzi%29_%E3%82%92%E3%82%B3%E3%83%B3%E3%83%88%E3%83%AD%E3%83%BC%E3%83%AB%E3%81%99%E3%82%8B_Cruise_Control
- https://kenta-kosugi.medium.com/kafka-mirrormaker-2-%E3%81%A8-kafka-connect-92930a769e84
- https://logmi.jp/tech/articles/325945
- https://drive.google.com/viewerng/viewer?url=http://sites.computer.org/debull/A12june/pipeline.pdf
- https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
- https://techblog.yahoo.co.jp/entry/20191216789293/
- https://www.amazon.co.jp/dp/4798152374
- https://www.amazon.co.jp/Kafka-Neha-Narkhede/dp/4873118492
- http://mogile.web.fc2.com/kafka/intro.html