レッドハットのソリューションアーキテクトの森です。
Red Hat build of Debezium 2.5.4 が先日リリースされました。
Debezium を使うと、データベース内のデータやスキーマの変更をチェンジイベントとして取得し、AMQ Streams(Apache Kafka)のトピックに格納し、他のターゲットシステムにニアリアルタイムで変更内容を連携する事ができます。
今回の2.5.4リリースでは、今までテクニカルプレビューだった、JDBC Sink Connector がGAになりました。 この JDBC Sink Connector は、Debeziumを通じてキャプチャしたチェンジイベントを、JDBC ドライバーを使用してリレーショナルデータベースに書き込むことができます。

今回は、OpenShift上にMySQLのデータベースを構築し、Debeziumでチェンジイベントをキャプチャしているという想定で、 このチェンジイベントを、JDBC Sink Connector を使ってPostgreSQLに反映し、データベースの同期を行う仕組みを作っていきたいと思います。
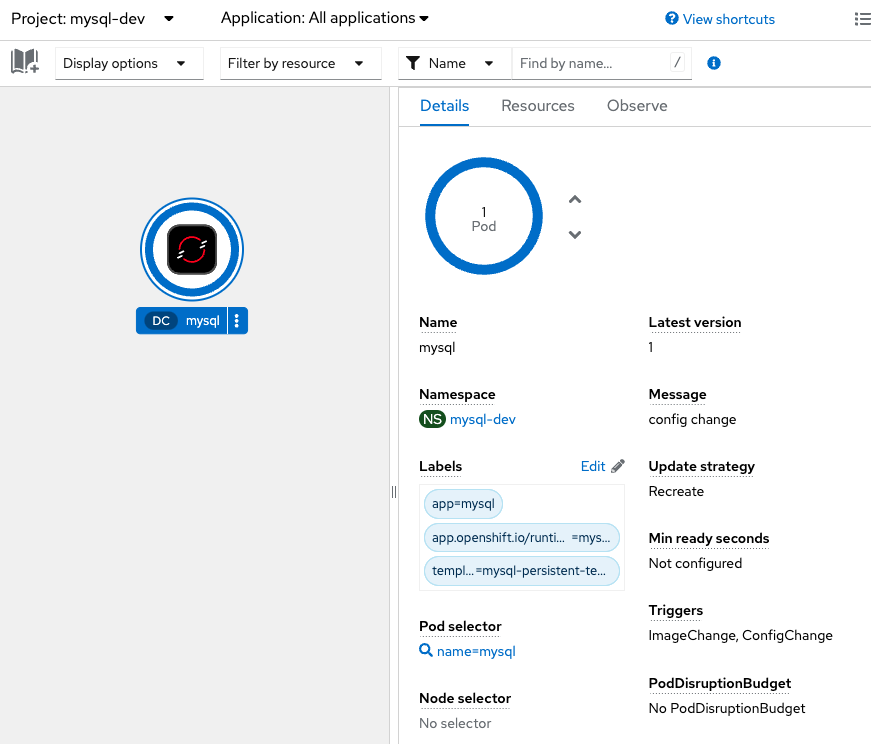
OpenShift上にMySQLをデプロイし、Debezium Source Connectorを設定しました。
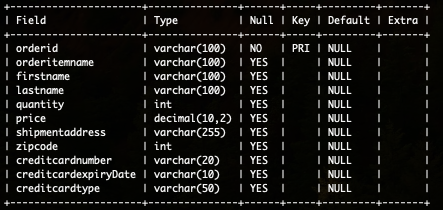
MySQLには以下のようなサンプルのデータベースを作成し、5件のレコードをInsertしています。

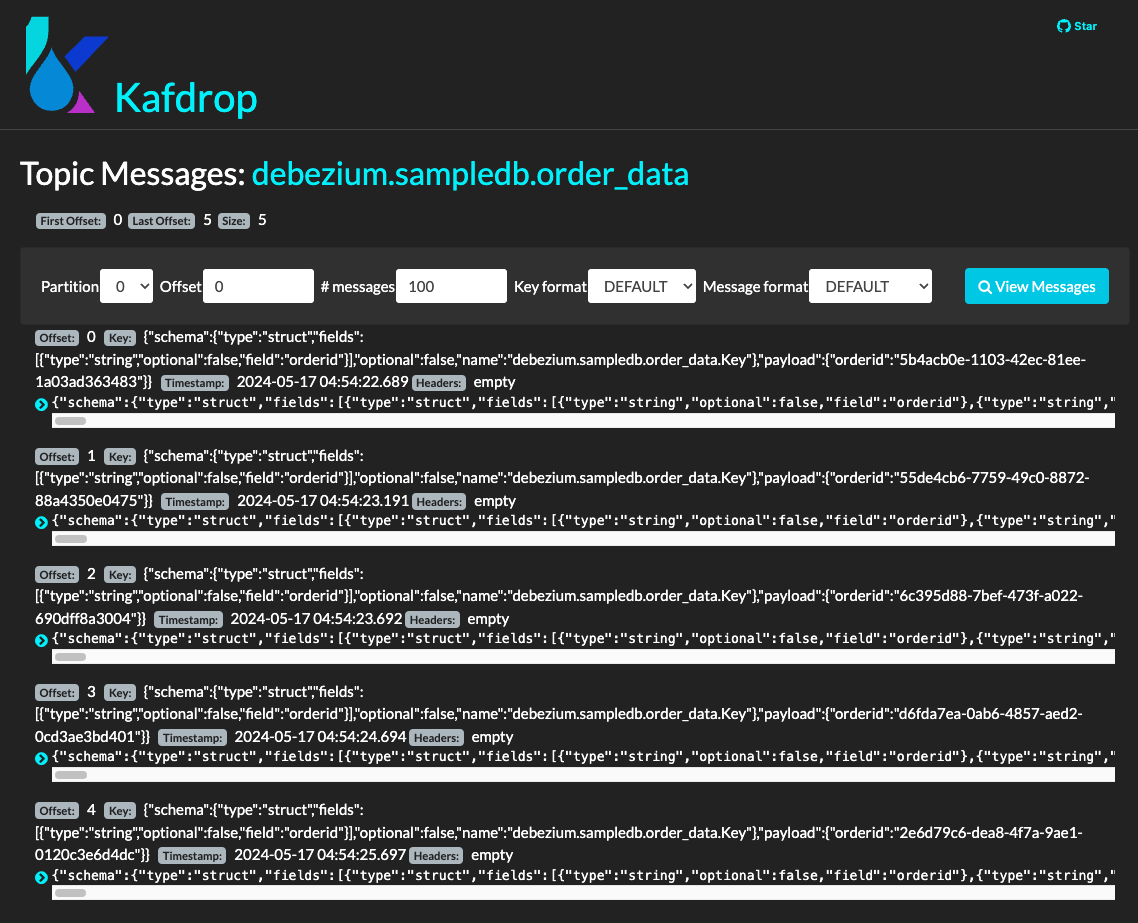
Debeziumがこれをキャプチャし、debezium.sampledb.order_data というトピックに、チェンジイベントが5件格納されています。
{
"schema": {
"type": "struct",
"fields": [
〜 中略 〜 (イベントメッセージのスキーマ情報)
],
"optional": false,
"name": "debezium.sampledb.order_data.Envelope",
"version": 1
},
"payload": {
"before": null,
"after": {
"orderid": "2e6d79c6-dea8-4f7a-9ae1-0120c3e6d4dc",
"orderitemname": "Orange Mango",
"firstname": "Aubrey",
"lastname": "Schamberger",
"quantity": 177,
"price": "AVU=",
"shipmentaddress": "P.O. Box 724, 731 Pharetra Avenue",
"zipcode": 11570,
"creditcardnumber": "3812-7582-9602-6055",
"creditcardexpiryDate": "2023/06",
"creditcardtype": "solo"
},
"source": {
"version": "2.5.4.Final-redhat-00001",
"connector": "mysql",
"name": "debezium",
"ts_ms": 1715921665000,
"snapshot": "false",
"db": "sampledb",
"sequence": null,
"table": "order_data",
"server_id": 1,
"gtid": null,
"file": "binlog.000002",
"pos": 3236,
"row": 0,
"thread": 58,
"query": null
},
"op": "c",
"ts_ms": 1715921665681,
"transaction": null
}
}
"payload"以下の、"before"には更新前のレコードの状態、"after"には更新後のレコードの状態があります。 "op"は操作のタイプを示しており、"c"はCREATE(新規)、"d"はDELETE(削除)、"u"はUPDATE(更新)、"r"はREAD(参照)です。
それでは、同期先のPostgreSQLへ更新を反映するSink Connectorを実装していきます。
PostgreSQLは、OpenShiftのテンプレートを使ってデプロイしました。Sink Connectorに関する設定は特に必要ありません。 (PostgreSQLのデプロイについての詳細は省略します)

まだデプロイしたのみで、テーブルなどは作成していない状態です。

Debezium JDBC Sink Connector のアーカイブを Kafka Connect に追加します。
OpenShift Web Console の AMQ Streams Operator から、Kafka Connect の設定を開き、spec.build.plugins.artifacts にJDBC Sink Connector のリポジトリのURLと名称を追加します。

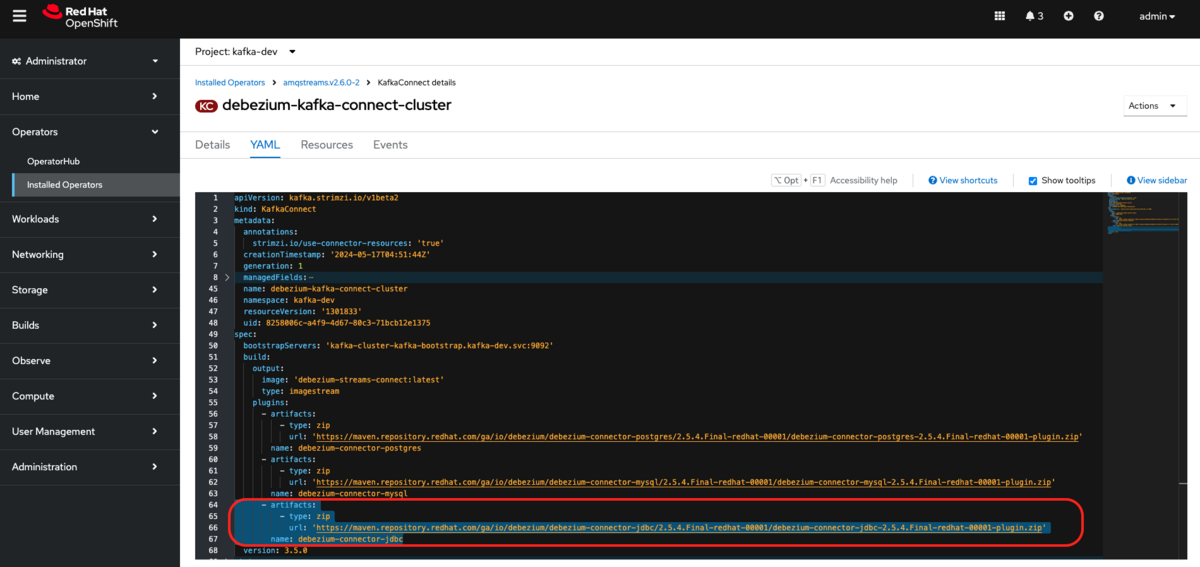
spec:
build:
plugins:
- artifacts:
- type: zip
url: 'https://maven.repository.redhat.com/ga/io/debezium/debezium-connector-jdbc/2.5.4.Final-redhat-00001/debezium-connector-jdbc-2.5.4.Final-redhat-00001-plugin.zip'
name: debezium-connector-jdbc
Sink Connector の 設定を Kafka Connector に追加して、起動します。
OpenShift Web Console の AMQ Streams Operator から、Kafka Connect のタブを選択し、Create Kafka Connector で新しい Kafka Connector を作成します。

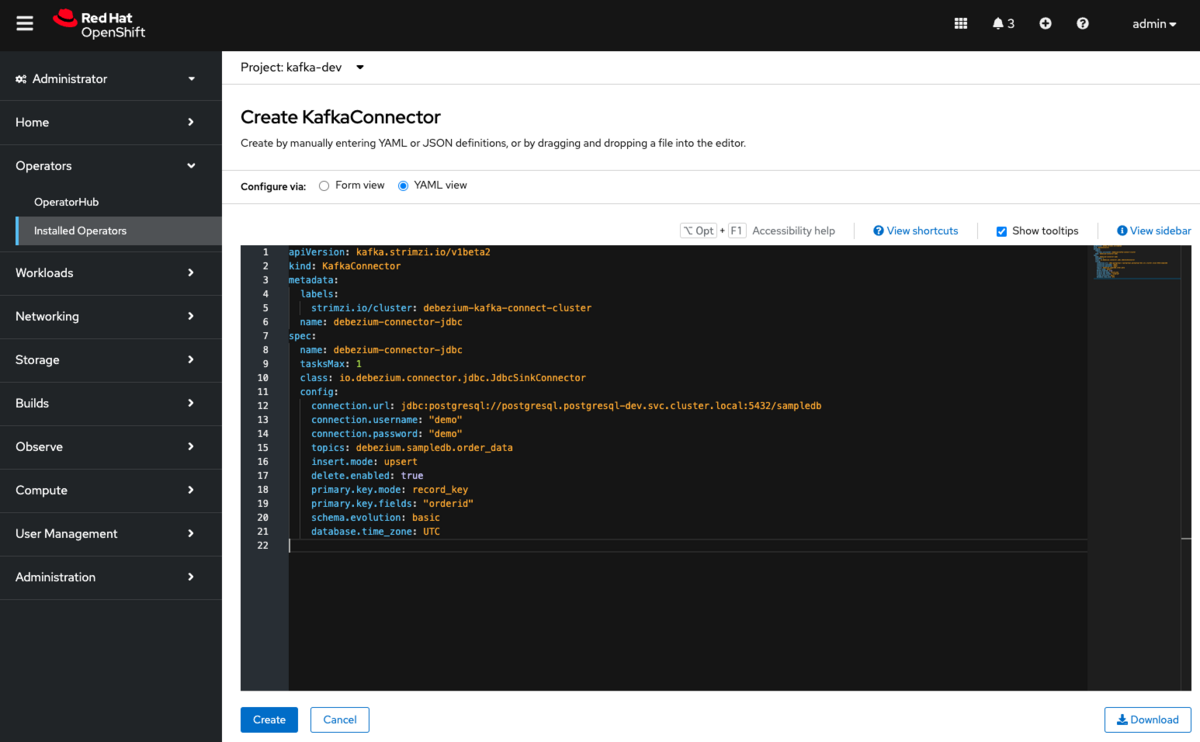
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
labels:
strimzi.io/cluster: debezium-kafka-connect-cluster # JDBCコネクタのURLを追加した KafkaConnect のNameと合わせる
name: debezium-connector-jdbc
spec:
name: debezium-connector-jdbc
tasksMax: 1 # コネクタで使用するタスクの最大数
class: io.debezium.connector.jdbc.JdbcSinkConnector # Debezium JDBC コネクタの場合は、io.debezium.connector.jdbc.jdbcSinkConnector を指定
config:
connection.url: jdbc:postgresql://postgresql.postgresql-dev.svc.cluster.local:5432/sampledb # データベースへの接続に使用するJDBC接続URL
connection.username: "demo" # コネクタがデータベースへの接続に使用するusername
connection.password: "demo" # コネクタがデータベースへの接続に使用するpassword
topics: debezium.sampledb.order_data # 受信するKafkaのトピックのリスト、複数ある場合はカンマ区切りで指定
insert.mode: upsert # データベースへのイベント処理に関する設定。 insert, update, upsertの3種類から選択。
delete.enabled: true # DELETE イベントを処理して、対応する行をデータベースから削除するかどうかを指定。
primary.key.mode: record_key # コネクタがイベントからプライマリキーを取得する方法。DELETE イベントを処理する場合は record_key に設定。
primary.key.fields: "orderid" # プライマリキーのカラム名
schema.evolution: basic # コネクタが対象のテーブルのスキーマの変更への対応の有無を指定。
database.time_zone: UTC # 時間値を挿入する際に使用するタイムゾーンを指定します。
コンフィグパラメータの詳細については、製品ドキュメントを参照ください。
しばらく待って、Condition: Ready になったら設定完了です。

PosgreSQLのテーブルを確認してみます。
先ほどは無かった、debezium_sampledb_order_data というテーブルが作成されています。
中身を見ると、MySQLのサンプルテーブルのカラムと同じ構成になっています。
レコードを確認すると、MySQLのサンプルテーブルと同じものが5件格納されています。

MySQL 側に変更(INSERT, UPDATE, DELETE)を行ってみます。
insert into order_data (orderid, orderitemname, firstname, lastname, quantity, price, shipmentaddress, zipcode, creditcardnumber, creditcardexpirydate, creditcardtype) VALUES ('12139cb8-e5fa-4019-a743-42e6792e3c8a', 'Blueberry', 'Lester', 'Mraz', 10, 5.2, '415-2575 Integer Road', '97462', '1234-5678-9012-3456', '2028/12', 'american_express');
update order_data set creditcardexpirydate='2032/03' where orderid='d6fda7ea-0ab6-4857-aed2-0cd3ae3bd401';
delete from order_data where orderid='55de4cb6-7759-49c0-8872-88a4350e0475';
Query OK, 1 row affected (0.02 sec)
- INSERT("orderid":"12139cb8-e5fa-4019-a743-42e6792e3c8a"のレコードを追加)
[MySQL]

[PostgreSQL]

- UPDATE("orderid":"d6fda7ea-0ab6-4857-aed2-0cd3ae3bd401"のレコードの"creditcardexpirydate"を変更)
[MySQL]

[PostgreSQL]

- DELETE("orderid":"55de4cb6-7759-49c0-8872-88a4350e0475"のレコードを削除)
[MySQL]

[PostgreSQL]

MySQLに対する操作が、PostgreSQLにも反映されていることが確認できました。
いかがでしょうか? Debezium JDBC Sink Connector を使うことで、チェンジイベントからデータベースの同期を図る仕組みの構築がより簡単になりました。
Debeziumによるチェンジデータキャプチャは、データのレプリケーションや、マイクロサービス間のデータ連携、参照モデルの更新など、様々なユースケースで活用する事ができます。 Debeziumに関して興味がある・もう少し詳しい内容が聞きたい、などありましたら、是非弊社までお問合せ頂ければと思います。