こんにちは、ソリューションアーキテクトの蒸野(ムシノ)です。
今回は、Red Hat Developerのブログ Red Hat OpenShift Connectors: Configuring change data capture | Red Hat Developer の翻訳記事をベースに紹介させて頂きたいと思います。 翻訳記事から内容の一部変更、およびオリジナルにない画面表示や補足事項を追加しています。ご承知おき頂けたらと思います。
はじめに
「Red Hat OpenShift Connectors」 は、レッドハットが提供する新しいクラウドサービスです。このサービスは、システム間で迅速かつ信頼性の高い接続を可能にするために、あらかじめ事前設定されたコネクタを提供しています。各コネクタはApache Kafka向けのマネージドサービスである「Red Hat OpenShift Streams for Apache Kafka」と事前に統合され、フルマネージドサービスとして提供されてます。
チェンジデータキャプチャ(CDC)は、データベース内のデータ変更を検出し変更情報をイベントに変換し、他のシステムやアプリケーションがこれらイベントデータを利用して変更に対応できるようにするデザインパターンです。
変更データ取得の典型的な使用例としては、以下のようなものがあります。
- データレプリケーション
- ストリーミングアプリケーション
- イベント駆動型アプリケーション
「Red Hat OpenShift Connectors「 は、人気のあるオープンソースプロジェクトである 「Debezium」 をベースとした、変更データキャプチャ用の複数のソースコネクタを提供します。現時点でサポートするデータベースは下記のとおりです。
- PostgreSQL
- MySQL
- SQLサーバー
- MongoDB
それでは事前説明はこのくらいにして、
本記事では、OpenShift上に配置しているPostgreSQLからデータ変更イベントを取得するためのソースコネクタを設定する方法を紹介していきたいと思います。
前提環境
この記事では、「OpenShift Streams for Apache Kafka」 のインスタンスを作成し、そのインスタンスが利用可能な状態であることを前提にしています。Kafka インスタンスを作成するための手順については、前回記事の「Red Hat OpenShift Connectors のご紹介 - 赤帽エンジニアブログ」を参照ください。
「OpenShift Streams for Apache Kafka」 にアクセスするには、サービスアカウントを作成し、サービスアカウントに対してアクセスルールを設定する必要があります。具体的には、トピックの読み取りと書き込み、および新しいトピックを作成するための権限が必要です。これら手順についても過去記事に詳細手順がありますのでご覧いただければと思います。
OpenShift に PostgreSQL インスタンスをセットアップする
次に、PostgreSQL のセットアップする方法を説明します。
OpenShift にサインアップして PostgreSQL をプロビジョニングします。
任意のプロジェクト上で、トポロジーから右クリックで「プロジェクトに追加」>「データベース」を選択します。
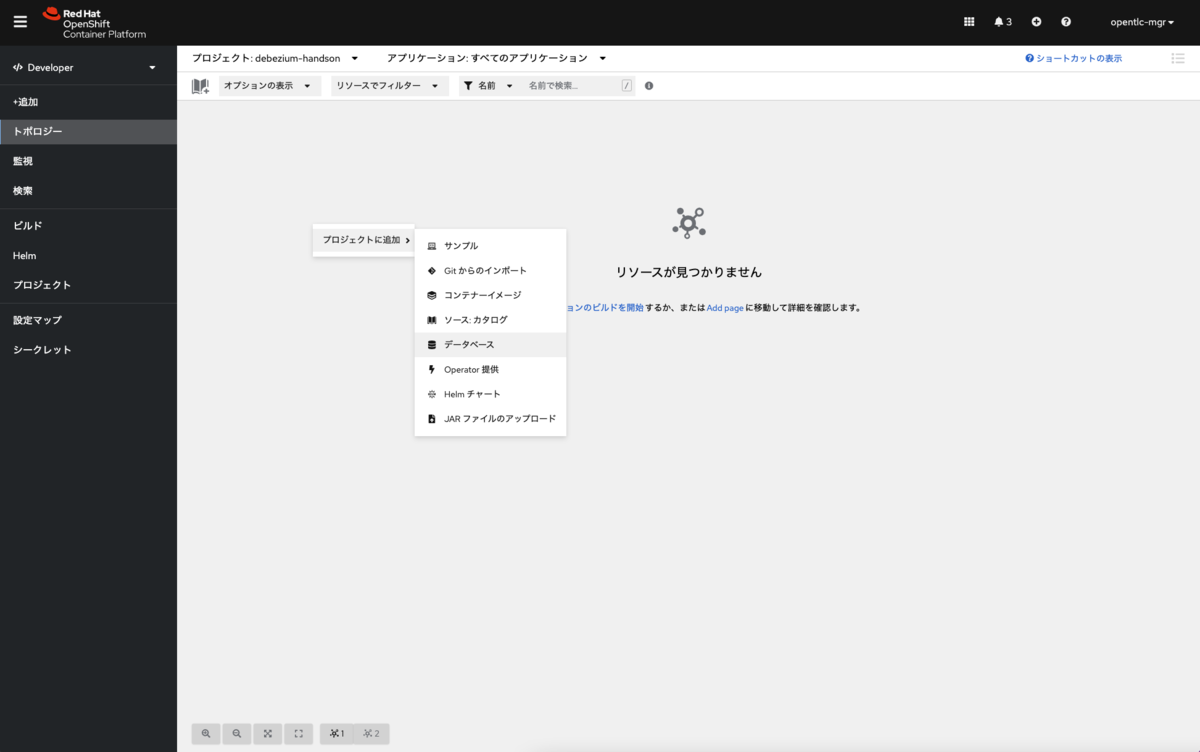
作成可能なデータベースが表示されますので、「PostgreSQL(Ephemeral)」を選択しインスタンスを作成します。
テンプレートのインスタンス化が表示されますのでこれをクリックします。
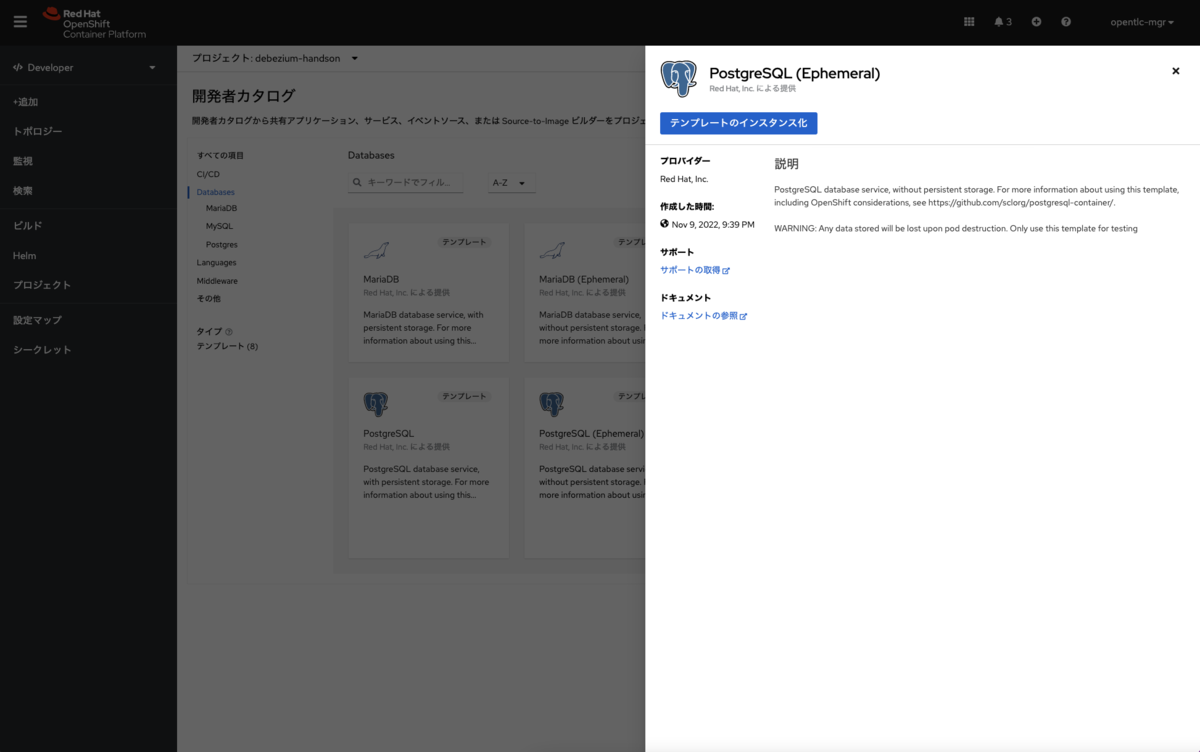
インスタンスの設定画面に遷移すると思いますので、例えば以下のように設定を行います。
- Database Service Name: postgresql
- PostgreSQL Connection Username: postgres
- PostgreSQL Connection Password: postgres
- PostgreSQL Database Name: postgres
その他は標準のままで問題ありません。
準備が整いましたら、作成ボタンをクリックします。

PostgreSQLのインスタンスが準備され、数秒待てばインスタンスが無事作成されます。
次にPostgreSQLにテーブルを作成します。
これはPodにアクセスしてCREATE TABLE文を流し込みます。まず、Podにアクセスするため、PostgreSQL のインスタンスをクリックして、右メニューからPodにアクセスします。

次にPodのターミナルタブを選択すると次のような画面が表示されます。
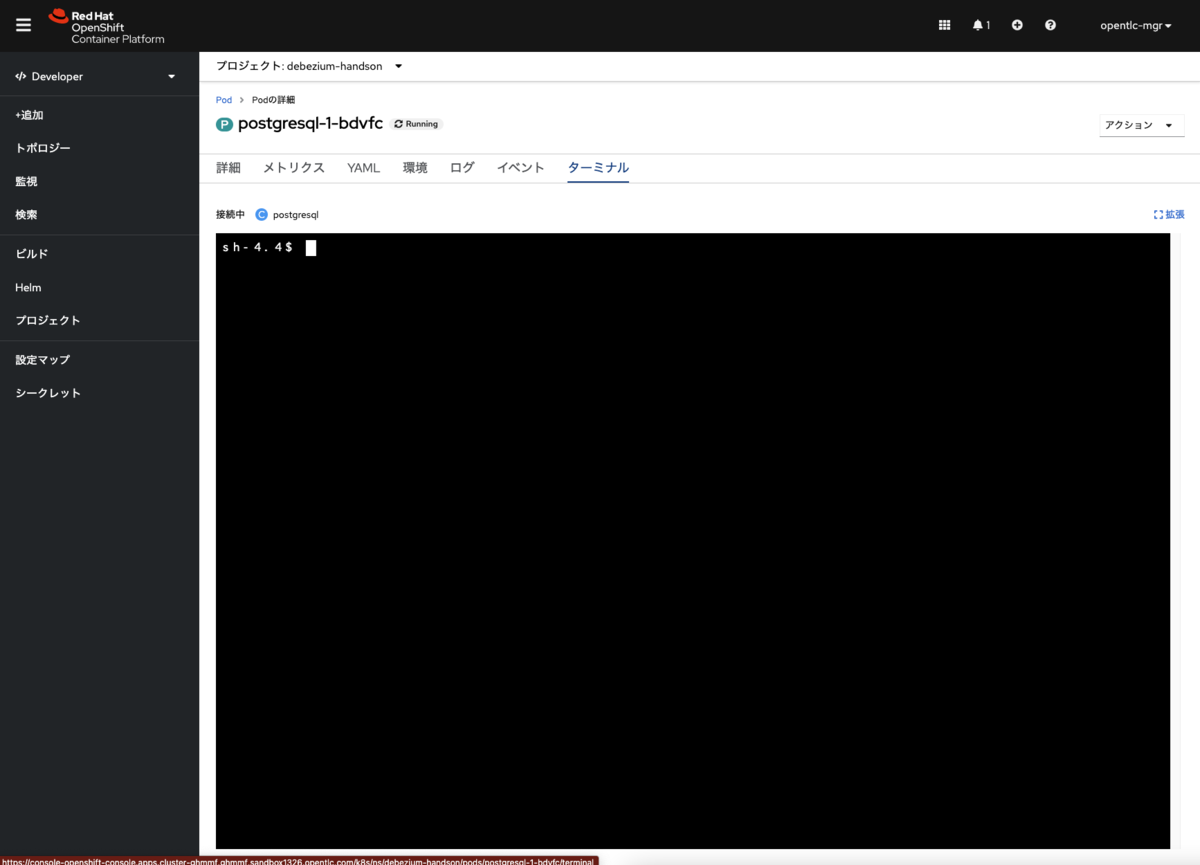
PostgreSQLに接続します
psql -h localhost -p 5432 -U postgres -d postgres
次に、テーブルを作成します。
CREATE TABLE Orders (
OrderId integer not null primary key,
OrderType varchar(1),
OrderItemName varchar(50),
Quantity integer,
Price varchar(50) ,
ShipmentAddress varchar(100) ,
ZipCode varchar(10),
OrderUser varchar(10)
);
更に、「Red Hat OpenShift Connectors」が「postgresql」にアクセスできるようにOCコマンドで「loadbalancer」を追加します
oc expose deploymentconfig postgresql --type=LoadBalancer --name=postgresql-loadbalancer
作成後、サービスの内容を確認します
oc get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE postgresql ClusterIP XXX.XX.XX.XXX <none> 5432/TCP 172m postgresql-ingress LoadBalancer XXX.XX.XX.XXX XXXXXXXXXXXXXXXXXXXXXXXXXX-XXXXXXXXX.ap-southeast-1.elb.amazonaws.com 5432:30973/TCP 2m29s
最後に、サンプルデータの登録を行います。
INSERT INTO "public"."orders" ("orderid", "ordertype", "orderitemname", "quantity", "price", "shipmentaddress", "zipcode", "orderuser") VALUES (1, 'E', 'TEST1', 12, '300', '東京', '1500001', 'USER1');
INSERT INTO "public"."orders" ("orderid", "ordertype", "orderitemname", "quantity", "price", "shipmentaddress", "zipcode", "orderuser") VALUES (2, 'E', 'TEST2', 100, '30', '新潟', '9591955', 'USER1');
INSERT INTO "public"."orders" ("orderid", "ordertype", "orderitemname", "quantity", "price", "shipmentaddress", "zipcode", "orderuser") VALUES (3, 'E', 'TEST3', 33, '1440', '北海道', '0801260', 'USER1');
INSERT INTO "public"."orders" ("orderid", "ordertype", "orderitemname", "quantity", "price", "shipmentaddress", "zipcode", "orderuser") VALUES (4, 'E', 'TEST4', 50, '50', '大阪', '5980014', 'USER2');
INSERT INTO "public"."orders" ("orderid", "ordertype", "orderitemname", "quantity", "price", "shipmentaddress", "zipcode", "orderuser") VALUES (5, 'E', 'TEST5', 90, '100', '福岡', '8140004', 'USER2');
設定上の注意点として、PostgreSQLではトランザクションログ(WAL)のログレベルをロジカルに変更する必要があります。 「postgresql.conf」を変更し、「wal_level = logical」に設定し、再起動を行います。
これでデータベース側の準備は一旦完了です。
変更データ取得のためのインスタンスを作成するの手順
前のステップで、PostgreSQL インスタンスを起動、サンプルデータをロードできたことだと思います。 次に、Order テーブルから変更イベントをキャプチャするため、 「OpenShift Connectors」 ソースコネクタを作成します。Red Hat ハイブリットクラウドコンソールから、次のステップを実施します。
1.「console.redhat.com」 >「Application and Data Services」にアクセスします。

2.「Application and Data Services」 から、「Connectors」 を選択し、「Create Connectors instance」 をクリックします。

3.検索フィールドに debezium と入力すると、いくつかのコネクターが表示されます。表示された「Debezium PostgrreSQL Connector」 をクリックし、Next をクリックします。

4.コネクタの 「Streams for Apache Kafka」 インスタンスを選択します。(※前提環境で作成したKafkaインスタンスです)
次に、Next をクリックします。

5.「Namespace」では「Create preview namespace」をクリックして、コネクタインスタンスを所属させるためのネームスペースを作成します。この評価用のネームスペースは 48時間利用が可能です。ネームスペースが利用可能になったら、それを選択し、[Next]をクリックします。
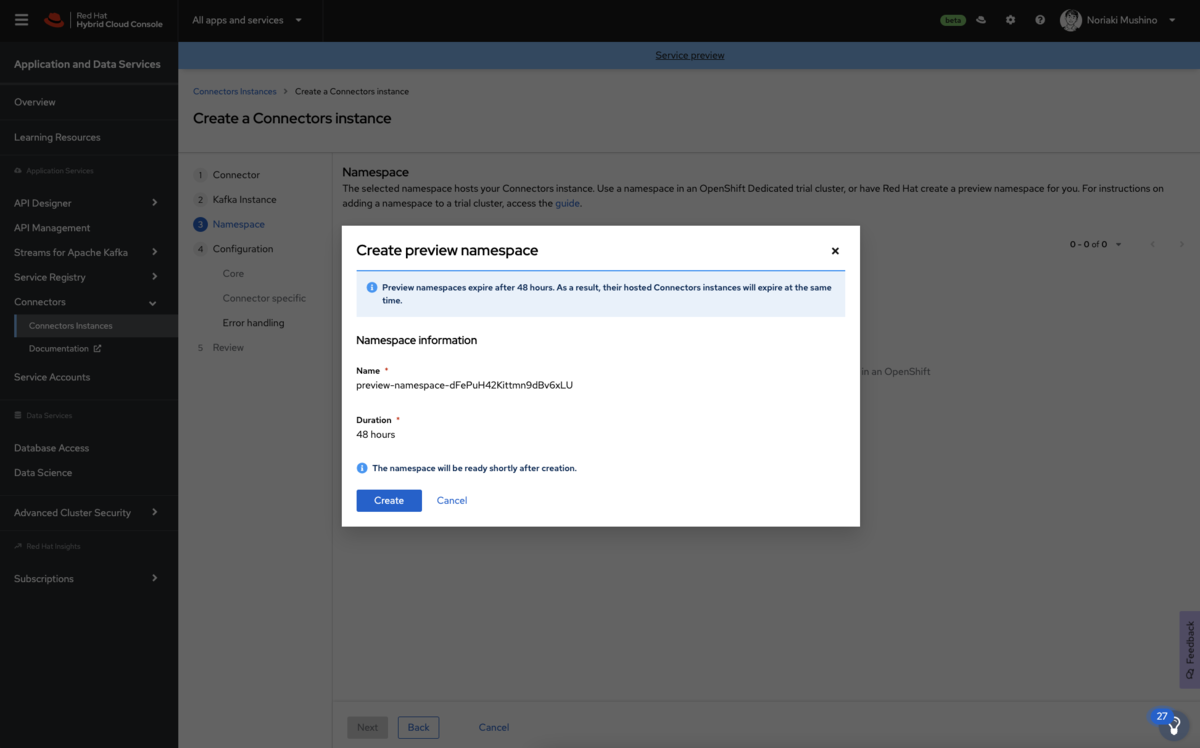
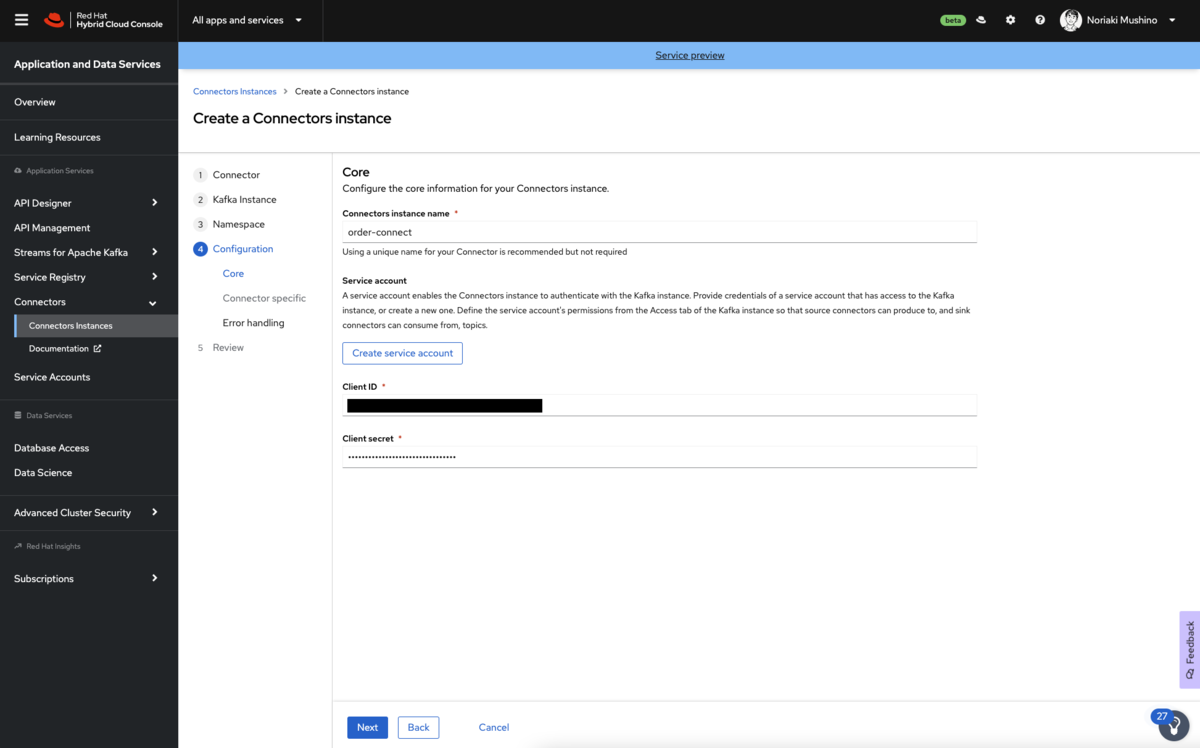
6.以下の値を入力し、コネクタの概要設定を行います。 下記の内容を設定して次をクリックします。
- コネクタの名前
- コネクタ用に作成したサービスアカウントのクライアントID
- コネクタ用に作成したサービスアカウントのシークレット
7.コネクタの接続設定を提供します。
「Debezium Postgres Connector」の場合、以下の情報を入力します。
- Database:作成したデータベースユーザーのユーザー名です。例:postgresql
- Hostname:PostgreSQL インスタンスの公開アドレス。PostgreSQL インスタンスを作成したときの「EXTERNAL-IP 」を確認します
- Port:デフォルトから変更がなければそのままにします
- Password:以前に作成したデータベースユーザーのパスワード 例:postgres
- Namespace:この Postgresql インスタンスを識別するための一意の名前 例:postgres
- User:作成したデータベースユーザーのユーザー名です 例:postgres
- Advanced Properties:特に変更対象がなければそのままにします

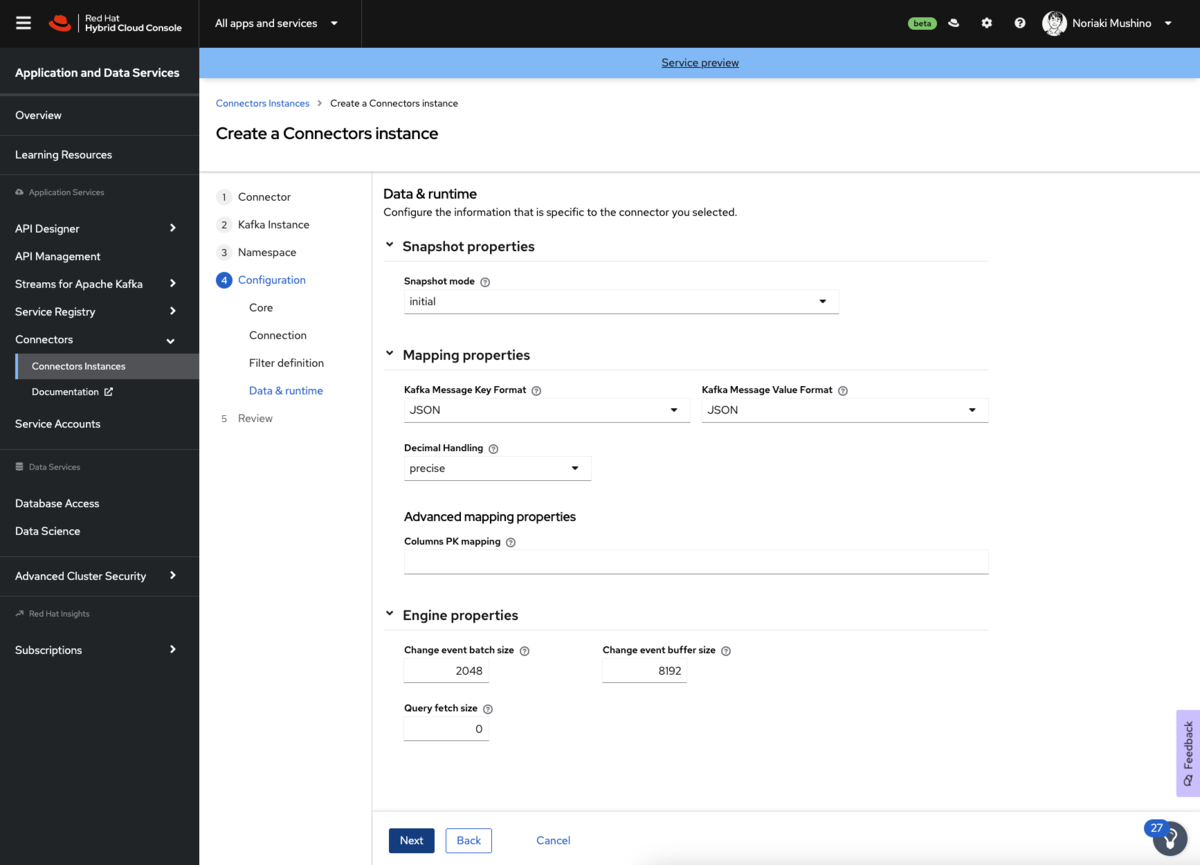
8.フィルタ定義はデフォルトのままで問題ありません。

9.データ&ランタイムの値はデフォルト値で問題ありません。こちらは、特別な理由がない限り、一般的には変更しません。
10.設定プロパティのサマリーを確認します。特に 「Database Hostname」 フィールドに注意してください。問題がなければ「Create Connector」 をクリックしてコネクタを作成します。
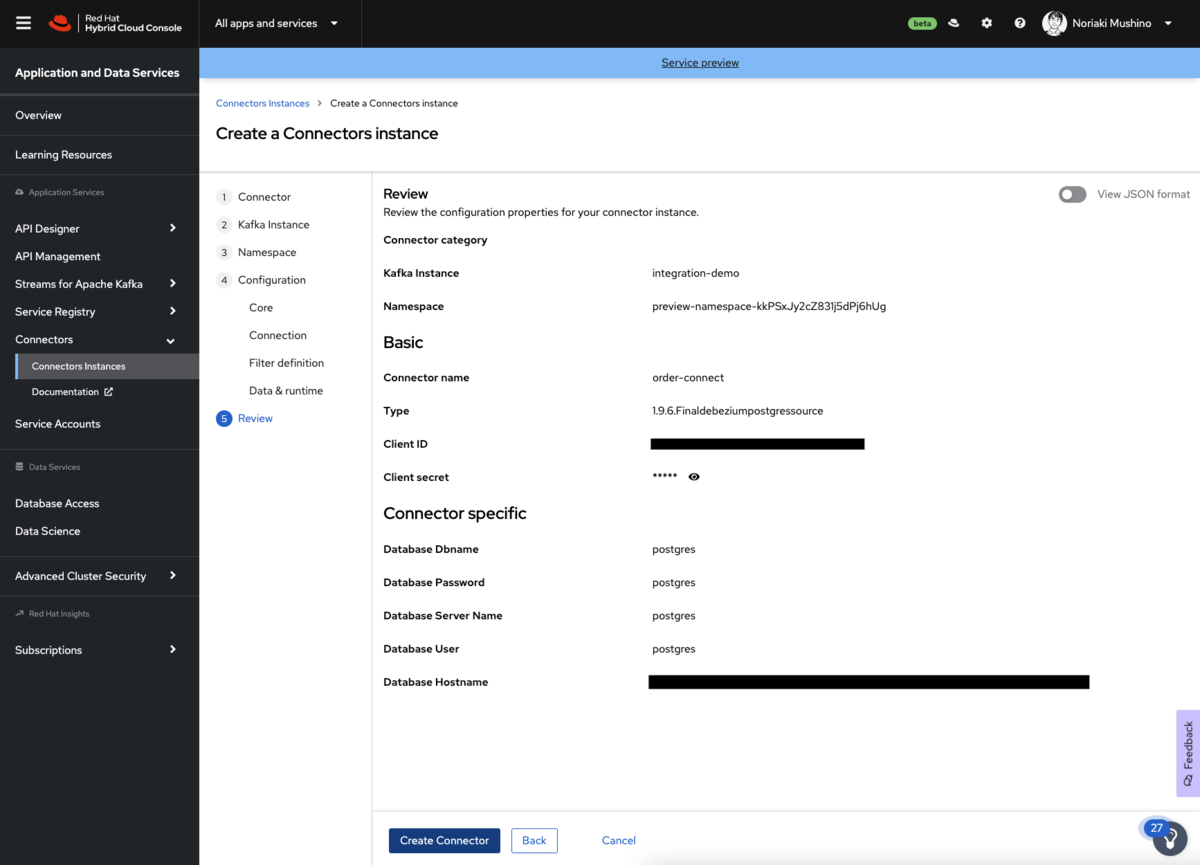
コネクタインスタンスがコネクタのテーブルに追加されます。数秒後〜数分後、コネクタインスタンスのステータスが「Ready」に変わるはずです。コネクタがエラー状態になった場合は、コネクタの横にあるオプションアイコンをクリックして修正することができます。
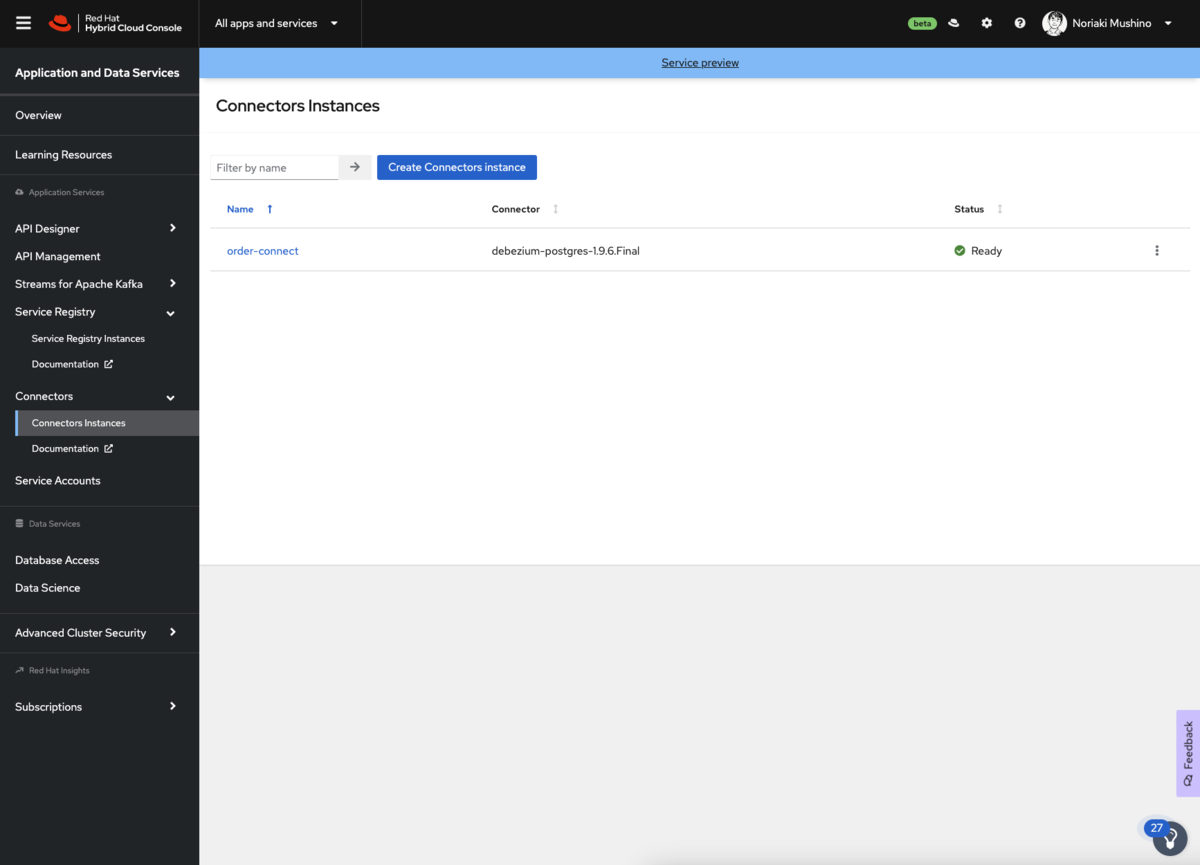
PostgreSQLからデータ変更イベントを取得する
「Debezium PostgrreSQL Connector」 の準備ができると、Postgresql データベースに接続し、監視するテーブルのスナップショットを作成します。テーブルに存在するすべてのレコードに対してデータ変更イベントを作成します。
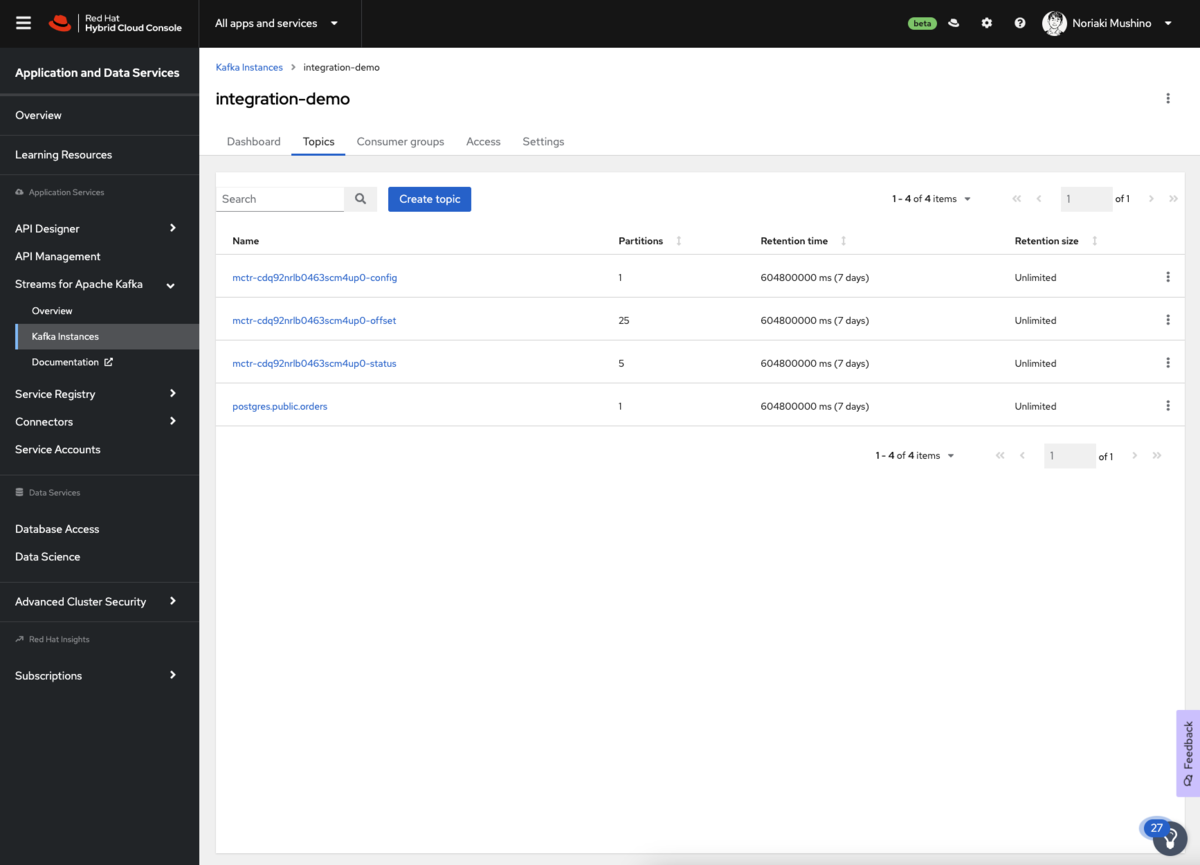
これを確認するには、「OpenShift Streams for Apache Kafka」 の コンソールでメッセージを表示します。 Red Hat コンソールの 「Application and Data Services」 ページに移動し、「Streams for Apache Kafka」→「Kafka Instances」 を選択します。コネクタ用に作成したStreams for Apache Kafkaインスタンスの名前をクリックし「Topics」 タブを選択します。
4つの新しいトピックが表示されるはずです。Debeziumコネクタは、Kafka Connectの上で動作します。Kafka Connectは、その内部状態を維持するために3つのトピックを作成します。これらは、「XXXXXXXXXXX-config」、「XXXXXXXXXXX-offset」、「XXXXXXXXXXX-status」 で終わるトピックです。
そしてもうひとつのトピックは 「postgres.public.orders」 という名前で、データ変更イベントを保持します。
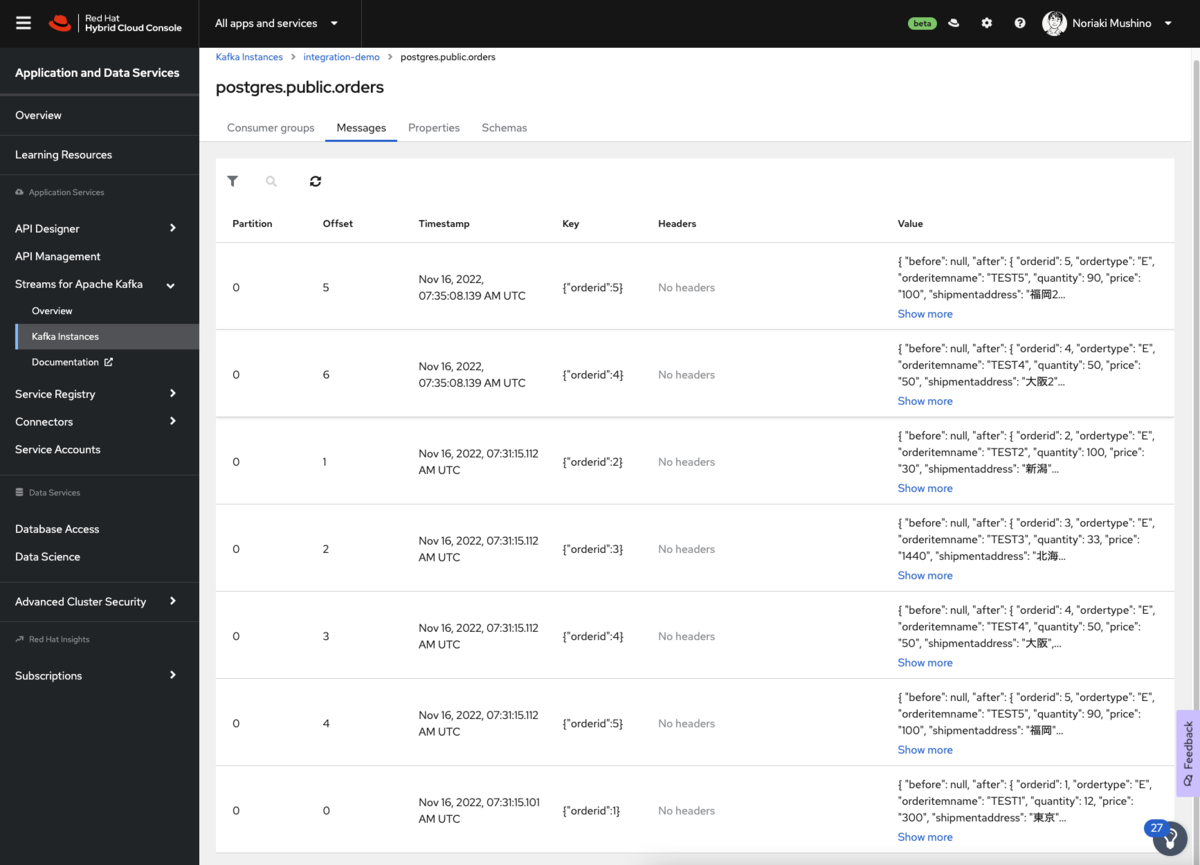
「postgres.public.orders」トピックをクリックし、「Messages」 タブを選択します。サンプルデータから連携された5つのメッセージが表示されているかと思います。

この時点で、PostgreSQL に新しいレコードを追加したり、既存のレコードの変更を検知できるようになります。 例えばサンプルデータを変更するものとし、次のSQL文を発行したとします。
UPDATE "public"."orders" SET "shipmentaddress" = '福岡2' WHERE "orderid" = 5; UPDATE "public"."orders" SET "shipmentaddress" = '大阪2' WHERE "orderid" = 4;
同様にトピックのメッセージビューアを確認することで、変更イベントが生成されていることを確認できます。
Topicのメッセージには、下記のように2つの更新メッセージが追加で表示されます。このようにイベントデータとしてデータベースの変更内容を検知することができます。
次に、イベントデータのValueにある「Show more」をクリックしてみましょう。 イベントデータの詳細が表示されるかと思います。
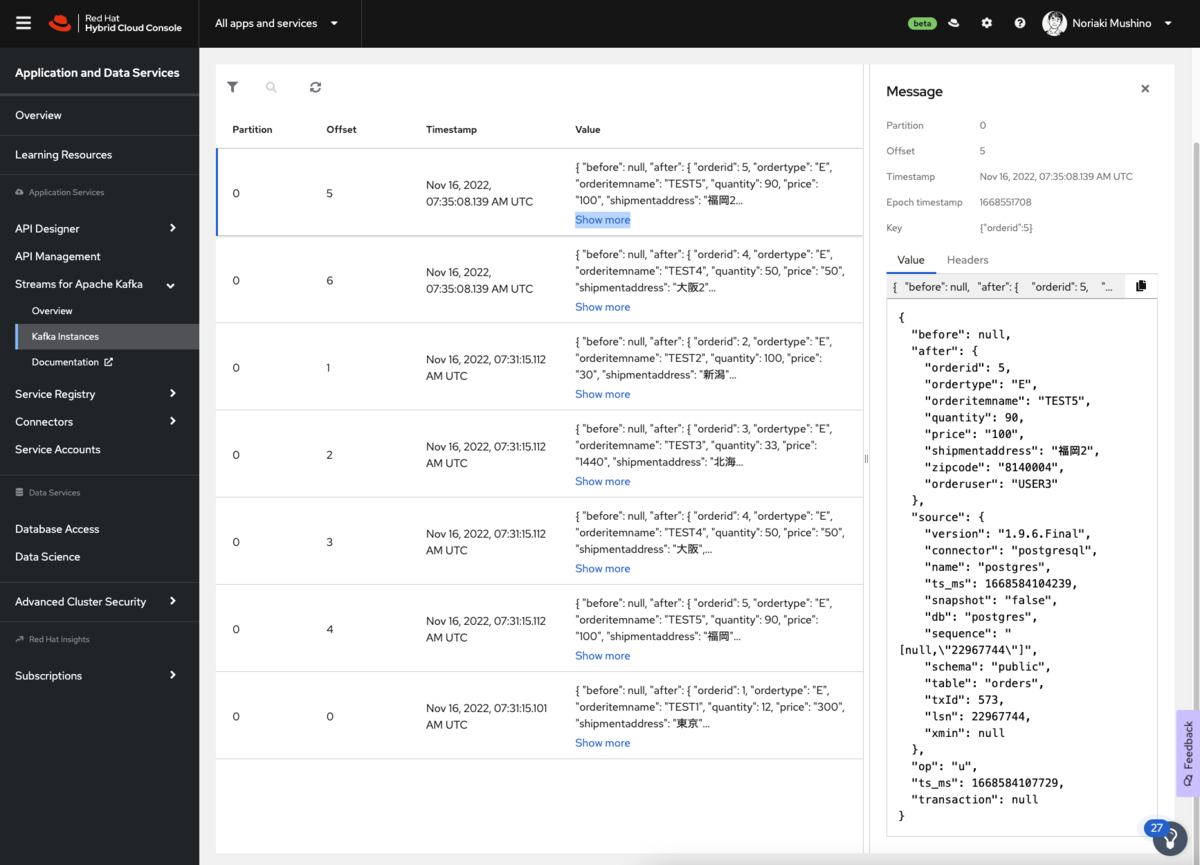
各イベントデータのメッセージは、以下の構造を持つJSONペイロードを持ちます。
- after: メッセージの最新の状態が格納されている。
- source: コネクタと PostgreSQLインスタンスに関するメタデータが含まれる。
- op: この変更を作成した操作を指定します。この場合、操作は「 u」 で、これは update を示しています。
エンドツーエンドのデータパイプラインの例
OpenShift Connector インスタンスでデータベースからデータ変更イベントをキャプチャすることは、データを使用するための最初のステップに過ぎません。通常、データ変更イベントは他のサービスやアプリケーションによって利用され、データのレプリケーションやローカルデータを構築するために使用されます。
次のビデオは、エンドツーエンドのデータパイプラインがどのようなものかを示すデモとなっています。このデモでは、「OpenShift Connectors」を使用して、データ変更イベントを「AWS Kinesis」に連携しています。イベントは、イベントからメッセージの状態を抽出し、「AWS OpenSearch」インデックスを更新する「AWS Lambda」関数をトリガーします。 youtu.be
このデモによりより具体的なユースケースについてご理解いただけるかと思います。「Red Hat OpenShift Connectors」 がデータ収集アプリケーションがどのように利便性を向上させ、処理を高速化させることができるのか是非お試しいただけたらと思います。
Debezium の最近のリリースについて
Red Hat Application Foundationに含まれる Debezium は下記の通りより多くのデータベースに対応しています。
- PostgreSQL
- MySQL
- SQLサーバー
- MongoDB
- DB2
- Oracle
最近のリリースでサポートされるようになったデータベースは下記になります。
- Debezium 1.7(RED HAT INTEGRATION 2022.Q2)にてDB2
- Debezium 1.9.7(RED HAT INTEGRATION 2022.Q3)にてOracleに対応
ただし、Oracle対応はLogMinerをベースにしており、Oracle EE 12.2以降のOracle Real Application Clusters (RAC) はテクノロジープレビューになる点にご注意ください。 詳しくはDebezium でサポートされる構成 - Red Hat Customer Portalを御覧ください。
最後に
如何でしたでしょうか?
前回に引き続き、「Red Hat OpenShift Connectors」を使ったCDCの始め方について具体的に示させていただきました。
是非一度ご利用いただくとともに、ご意見をお待ちしております。
Debeziumをより深く理解したい方は、下記記事についても是非ともご覧ください。 rheb.hatenablog.com