Red Hat で Java Platform Advocate として OpenJDK を担当している伊藤ちひろ(@chiroito)です。
この記事は、Red Hat Developerのブログ記事、Best practices for Java in single-core containers | Red Hat Developer の翻訳記事です。

コンテナで動作するJavaアプリケーションの数が増えています。コンテナの採用は、特定のチームや企業の市場区分や クラウドの成熟度によるので、正確な数を決定するのは困難です。たとえば、New Relic のデータでは、顧客の Java ワークロードの 62% 以上がコンテナで実行されています。他のデータと同様、このデータも市場全体に対する代用として不完全なものです。しかし、このレポートは、Java市場の重要な一部分がすでにコンテナベースの環境に移行していることを証明しています。また、こうした移行の流れがまだ終わっていないことも、さまざまなデータからうかがい知れます。
Javaを使用しているチームは、コンテナベースの導入におけるいくつかの側面に特別な注意を払い、いくつかのベストプラクティスを採用する必要があります。この記事では、ガベージコレクタ(GC)の選択と、利用可能な CPU数とメモリに基づくデフォルトの選択方法に焦点を当てます。
Javaアプリケーションのライフサイクル
従来のJavaアプリケーションのライフサイクルは、いくつかのフェーズで構成されています。起動、大量のクラス読み込み、ジャストインタイム(JIT)コンパイルによるウォームアップ、そして、クラス読み込みやJITが比較的少ない数日から数週間続く長い持続的状態が続きます。これは、Javaがサーバーサイドの技術としてスタートし、JVMがデータセンターのオンプレ上で動作していた時代を思い出せば、納得がいきます。
その世界では、クラスタの拡張には物理マシンを追加注文してデータセンターに配送してもらう必要があり、アプリケーションのバージョンアップはおそらく数カ月ごとに行われ、アプリケーションプロセスは週または月単位で稼働時間を測定していました。Javaアプリケーションの拡張性は、通常、スケールアップに焦点が当てられており、大量のメモリを搭載した大規模なマルチコアマシン上でJavaを効率的に動作させることが目標でした。
このようなJavaアプリケーションの導入モデルは、いくつかの異なるが関連する方法が、クラウド導入の課題となっています。
- コンテナの寿命はもっと短いかもしれない(場合によっては数秒)。
- クラスタサイズは動的に再調整または再構成されるかもしれません(例:Kubernetes)。
- マイクロサービスアーキテクチャは、プロセスサイズが小さくなり、寿命が短くなる傾向があります。
これらのことから、多くの開発者は、Javaアプリケーションをコンテナに移行する際、できるだけ小さなコンテナを使用しようとします。クラウドベースのアプリケーションは通常、使用するRAMとCPUの量によって課金されるため、これは理にかなっています。
しかし、ここには、Javaの専門家ではないエンジニアにはわからない微妙なニュアンスがあります。詳しく見ていきましょう。
動的な実行プラットフォームとしてのJVM
JVMは、それが実行されているマシンの実情に合わせて、起動時に特定の重要なパラメータを設定する、非常に動的なプラットフォームです。これらのプロパティには、JVMが認識するCPUの数と種類、利用可能な物理メモリが含まれます。実行中のアプリケーションの動作は、異なるサイズのマシンで実行された場合には、異なるものになる可能性がありますし、それはコンテナにも当てはまります。
JVMが起動時に確認する動的なプロパティには、次のようなものがあります。
- JVM組み込み関数:特定のCPU機能(ベクトルサポート、SIMDなど)に依存する、パフォーマンスが重要なメソッドの独自にチューニングされた実装
- 内部スレッドプール(共通プールなど)のサイズ
- GCに使用するスレッド数
この一覧だけでも、コンテナイメージに必要なリソースの定義を誤ると、GCや 一般的なスレッド操作に関連する問題が発生することがわかります。
しかし、問題は根本的にこれより深いのです。Java 17を含む現在のJavaのバージョンは、GCがコマンドラインで明示的に指定されていない場合、いくつかの動的チェックを実行し、エルゴノミクスの観点から(自動的に)使用するGCを決定します。
この原因を突き止めるために、OpenJDKのソースコードを見てみましょう。具体的には、src/hotspot/share/gc/shared/gcConfig.cpp ファイルに GCConfig::select_gc() という C++ メソッドがあり、GC が明示的に選ばれない限り GCConfig::select_gc_ergonomically() が呼ばれることが分かります。このメソッドのコードは
void GCConfig::select_gc_ergonomically() { if (os::is_server_class_machine()) { #if INCLUDE_G1GC FLAG_SET_ERGO_IF_DEFAULT(UseG1GC, true); #elif INCLUDE_PARALLELGC FLAG_SET_ERGO_IF_DEFAULT(UseParallelGC, true); #elif INCLUDE_SERIALGC FLAG_SET_ERGO_IF_DEFAULT(UseSerialGC, true); #endif } else { #if INCLUDE_SERIALGC FLAG_SET_ERGO_IF_DEFAULT(UseSerialGC, true); #endif } }
このコード片の意味は、C++マクロ(Hotspotのソースのいたるところで使われている)によって多少不明瞭になっていますが、基本的には次のようなことに集約されます。Java 11と17では、コレクタを指定しなかった場合、次のルールが適用されます。
- マシンがサーバクラスである場合、GC として G1 を選択します。
- マシンがサーバクラスでない場合、GC として Serial を選択します。
マシンがサーバークラスかどうかを判断するHotspotのメソッドは os::is_server_class_machine() です。これのコードを見てみると
// これがサーバークラスのマシンの動作定義です。 // 物理CPUが2つ以上、メモリが2GB以上あること
これは、Java アプリケーションが、CPU が 2 つ未満、メモリが 2GB 未満と思われるマシンまたはコンテナで実行される場合、デプロイ時に特定の GC アルゴリズムを明示的に選択しない限り、Serial アルゴリズムが使用されることを意味します。この結果は、通常、G1よりもStop-the-World(STW)ポーズ時間が長くなるため、チームが望むものではありません。
この効果を実際に見てみましょう。アプリケーションの例として、AmazonのHeapothesysプロジェクトの一部であるHyperAllocを使用することにします。このベンチマークツールは、"ガベージコレクタの待機時間に影響を与える基本的なアプリケーション特性を模した、人工的な負荷 "です。
簡単なDockerfileからコンテナイメージを起動します。
FROM docker.io/eclipse-temurin:17 RUN mkdir /app COPY docker_fs/ /app WORKDIR /app CMD ["java", "-Xmx1G", "-XX:StartFlightRecording=duration=60s,filename=hyperalloc.jfr", "-jar", "HyperAlloc-1.0.jar", "-a", "128", "-h", "1024", "-d", "60"]
使用しているHyperAllocのパラメータは、ヒープサイズが1GB、シミュレーションの実行時間が60秒、割り当て速度が128MB/秒です。これは、1つのCPUで使用するイメージです。
また、2つのCPUのコンテナで使用するために、割り当て速度を256MB/秒にした以外は同一のイメージも作成します。2番目のケースで高い割り当て率を設定したのは、HyperAllocで利用可能なCPUの量を増やして、両方のバージョンで同じ割り当て負荷を経験させるためです。
JDK Flight Recorder (JFR)を使うと、全期間のログを取得できます。それは60秒と非常に短いですが、この単純な例でJVMの全体的な動作を実証するのに十分な時間をもたらします。
2つのケースを比較しています。
- 1 CPU, 2GB イメージで 128MB の割り当て速度 (Serial GC)
- 2 CPUs, 2GB イメージで 256MB の割り当て速度 (G1 GC)
私たちが見たい2つのGCデータは、別々のケースの一時停止時間とGCの処理能力(GCを実行するために費やされた総CPUとして表現さ れる)です。
このサンプルを使って自分のデータで実験したい場合は、JFR HacksのGitHubリポジトリにコードがあります。このプロジェクトはGunnar MorlingのJFR Analyticsに依存しており、JFRの記録ファイルを照会するためのSQL風のインターフェイスを提供しています。
注意: この後のグラフでは、実行のタイムスタンプはVM起動後のミリ秒に正規化されています。
まず、一時停止時間から見ていきましょう。図1は、2つのケースの合計休止時間を示しています。
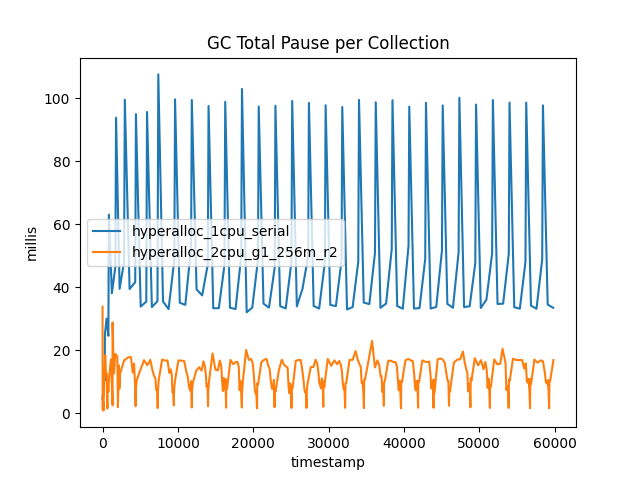
図1:1CPUの実行は、2CPUの実行に比べて、休止時間の合計が非常に多い。
この結果は、G1 を使用することの明確な利点を示しています。すべてのコレクションで、一時停止時間が大幅に短縮されました。G1Newコレクションは、シリアルの若い領域のGC(DefNewとして知られている)よりも 短いです。しかし、G1NewのコレクションはDefNewの3倍近くあります。
この急増の理由は、若い領域のGCは常に完全にSTWであることです。なぜなら、割り当てスレッド(アプリケーションのスレッド)は高いまたは予測できない割り当て速度を持つ傾向があります。これは、GCスレッドと割り当てスレッド間のCPUの競争は必ず勝てる訳ではないことを意味します-若い領域のGCのSTWポーズを受け入れ、できるだけ短く保つ方がよいでしょう。
G1 は「全部実行するか、あるいは実行しないか(all or nothing)」のコレクタではありません。その動作は領域に基づいているため、現在の割り当て速度に先んじるためにいくつかの若い領域を収集し、その後アプリケーションスレッドを再起動し、より短い休止の数を増やします。このような取引関係(トレードオフ)の全体的な効果については、後ほど詳しく説明します。
古い領域のGCでは、その効果はさらに顕著です。G1Old は実際に総休止時間が落ち込みますが、SerialOld は古い領域のGCで明らかに急増します。これは、G1Oldが並行コレクターであるため、コレクションの実行時間の大部分において、アプリケーションスレッドと並行して実行されているためです。2CPUの例では、G1Oldが実行されている間、1CPUはGCに、1CPUはアプリケーションスレッドに使用されています。
図2は、各コレクションの実行経過時間を示し、総停止時間との対比で示したものである。これは、G1Oldの並行性を示しています。
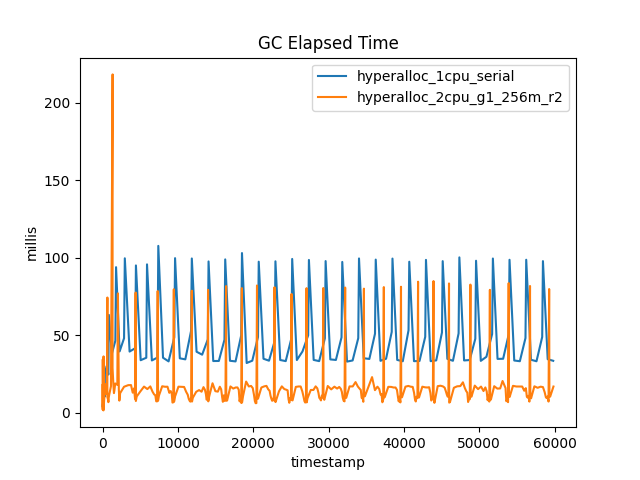
図2:1CPUの実行は、2CPUの実行に比べてGCに費やす時間が非常に長い
案の定、G1Oldの総休止時間が、経過時間ごとで見ると最大になっています。また、G1でもSerialでも、古い領域のGCの数はほぼ同じであることが目視で確認できます。
この時点で問われるかもしれない、ひとつの明白な疑問があります。GCの実行による全体的なコストは、CPU時間でどのくらいでしょうか? 若い領域のG1コレクションが若い領域のSerialコレクションよりも多いため、G1が使用する全体的なCPU時間はより高いという可能性はありませんか?この質問に答えるために、2つのコレクターのGCに費やされた累積時間を示す図3を見てください。
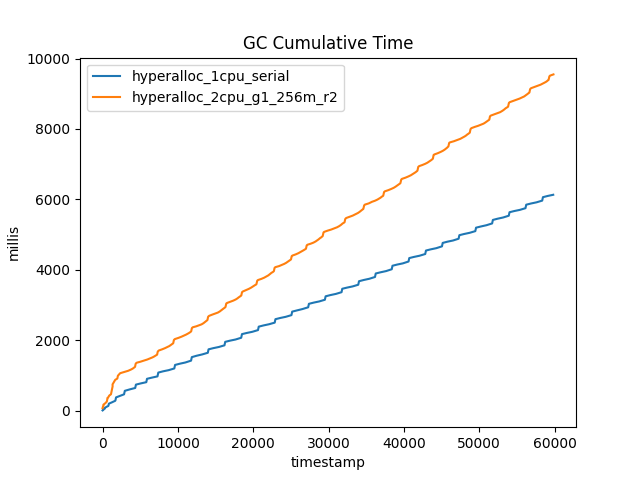
図3:2CPUの実行は、1CPUの実行よりも全体としてGCに費やす時間が長いが、2倍の時間はかからない。
一見すると、G1がSerialよりもCPUを多く使っているように見えます。しかし、G1実行は2つのCPUを使用し、2倍の割り当て率で処理していることを忘れてはいけません。つまり、CPU単位、あるいは割り当てGB単位で見ると、G1はSerialよりもまだ効率が良いということです。
全体として、より小さなコンテナの見かけ上の魅力にもかかわらず、ほとんどすべての場合において、2つのCPUと2GBのメモリを持つコンテナでJavaプロセスを実行し、G1の並行GCに利用可能なリソースを利用させる方が良いということです。
まとめと今後について
このおもちゃの例で効果がはっきり分かったところで、1つ大きな疑問が残りました。この効果は、本番用のコンテナではどのように発揮されるのでしょうか?
答えは、Javaのバージョンとカーネルのサポートに依存します。特に、cgroupsと呼ばれる特定のカーネルAPIがv1かv2のどちらであるかによります。
このシリーズの第2回では、Severin Gehwolfが、Hotspotがどのようにコンテナのプロパティを検出し、それに基づいて自動サイズを決定するのか、その詳細を深く掘り下げて説明します。また、Javaアプリケーションのコンテナ化に関するMicrosoftの最近の記事もご覧になってみてください。