OpenShift Advent Calendar 2022 18日目 の投稿です。
こんにちわ。Red HatでOpenShiftのSolution Architectを担当している北山 ( @spchilden ) です。
さて今日は、既存アプリをKubernetesへのきゃりーぱみゅぱみゅさんについて語りたいと思います。
大事なことなので先にお伝えしておくと、12/21 - 12/23とコーチェラ再現Liveがあるので是非参加しましょう。
「Special Live 2022 -Back To Coachella-」
イマ再び求められる「Twelve-Factor App」
さて、この1年OpenShiftビジネスに携わっていると、モダンなクラウドネイティブアーキテクチャというより、既存アプリケーションのコンテナ化から始めているユーザーさんと会話させてもらう機会が大きく増えました。
たしかにコミュニティ界隈ではマイクロサービス化を推進するため、Kafkaを使ったデータストリーミングやChange Data Captureを活用したデータ移行などが主流ですが、現場では、まず今あるアプリケーションをまずはコンテナに変えていくことから始めているユーザーさんが大半な気がしています。これを「Replatform」と呼んでたりします。
2022/11に開催されたCNDT 2022(Cloud NataiveDays Tokyo)でも少しこの件について触れさせていただきました。
なお、ログインすると動画も見れますので是非。
Kubernetesの利用が浸透してきている一方で、とりあえず既存の仮想マシン上で動いていたアプリケーションをコンテナ化すればよいという発想は回避しないといけません。
つまり、Kubernetesでアプリケーションを動かすためには、そのプロセスはやはり「Twelve-Factor App」に従ってReplatformされるべきです。そうしないと、Kubernetes上で運用していても運用の複雑さが増すばかりで、結果としてコンテナ導入メリットを感じられなくなります。
ただ、これ。。。
言うは易く行うは難し。
全部アプリケーション改修する予算やノウハウがあれば良いのですが、そう言ってられないのがエンタープライズの世界。
こうした開発者さんの悩みに応えるのが「Konveyor Tackle」です。
Konveyor Tackleの概要
「Konveyor Tackle」とは、KubernetesへのアプリケーションのReplatform、Refactoringを評価、優先順位付けしてくれるプロジェクトです。
はじめてこの名前を聞く方もいらっしゃるかもしれませんが、実はCNCFにもJOINしているオープンソースプロジェクトです。
いまのところJavaアプリケーションを対象としたコンテナ化の評価をおこなっていますが、アプリケーション以外にもいくつかの移行ツールが用意されています。
| プロジェクト | 概要 |
|---|---|
| Tackle Application Inventory | アプリケーションの評価(Tackle Pathfinder) および分析(windup)へのゲートウェイ |
| Tackle Pathfinder | Kubernetes上にアプリをデプロイするための適合性を評価するアンケートベースのツール |
| Tackle Controls | Application InventoryとPathfinderの評価にエンティティを付けて管理するツール |
| Tackle Container Advisor | 自然言語処理を使用して、アプリケーションの記述を分析し、アプリケーションをコンテナ化するのに最適なコンテナーイメージを提案 |
| Tackle Data Intensive Validity Advisor (DiVA) | アプリケーションのデータ レイヤーを分析し、さまざまなデータ ストアや分散トランザクションへの依存関係を検出 |
| Tackle-DiVA Database Operator Adaption (DiVA-DOA) | Kubernetesのマニフェスト(YAML)を生成して、レガシーDBMSシステムを使用するアプリケーションを、HA DB クラスターで動作できるように移行を支援 |
| Tackle Test Generator | モダナイズされた後のアプリケーションが同じように動作していることを確認 |
| Tackle Data Gravity Insights | モノリシックアプリケーションのコードを洞察し、ドメイン駆動型マイクロサービスにリファクタリングを支援 |
いっぱいありますね。
今回はこの中からアプリケーションの分析(windup)をご紹介します。
Konveyor Tackleのインストール
今回は「Tackle Operator」を活用して、Tackle v2()をOpenShift v4.11上にインストールします。
事前準備
Tackleをインストールするには、合計5つの永続ボリューム(PV) が必要です。PVC を介して3つの RWO ボリュームと2つのRWX ボリュームが要求されます。
| Name | Default Size | Access Mode | Description |
|---|---|---|---|
| hub database | 5Gi | RWO | Hub DB |
| hub bucket | 100Gi | RWX | Hub file storage |
| keycloak postgresql | 1Gi | RWO | Keycloak backend DB |
| pathfinder postgresql | 1Gi | RWO | Pathfinder backend DB |
| maven | 100Gi | RWX | maven m2 repository |
ここで戸惑っちゃうのが、RWXボリューム。…普通無いですよね。
ということで、事前に万能ストレージ「OpenShift Data Fundation(ODF)」をインストールしておきます。
(1) Operator Hubから「ODF」を検索してインストール

(2) OperatorのSubscriptionを定義してインストール実行
失敗しないための秘訣は、Install後に待つこと。ODFは様々なコンポーネントから出来ているため、「Installed」の表記に頼らず忍耐強く待ちましょう。
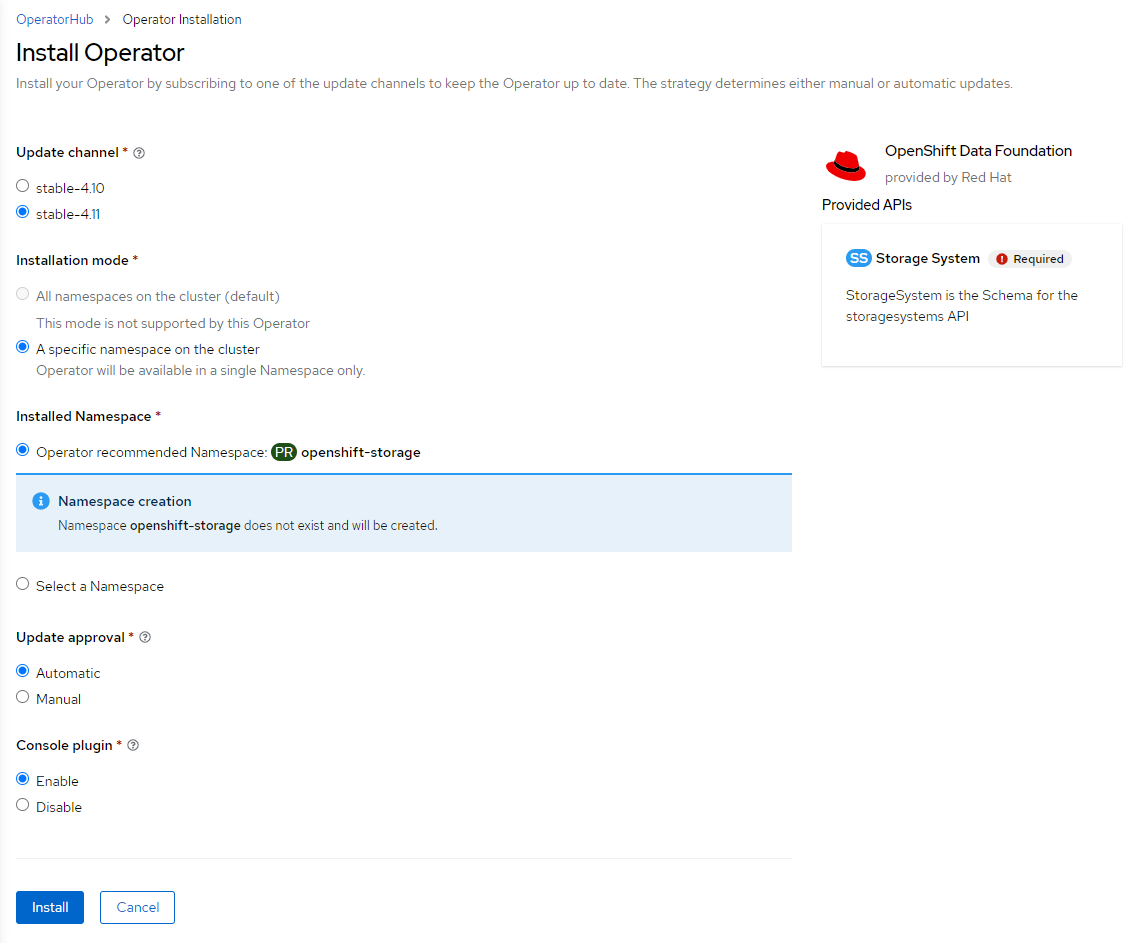
(3) CustomResource(Storage System)の作成
Operatorのインストールが終わったら、今度はCR(Storage System)を作成してODFクラスタを作ります。
今回は以下のCR内容で検証しました。CRを作成した後も忍耐強く待ちましょう。
**Backing storage** Deployment type: Full deployment Backing storage type: gp2 **Capacity and nodes** Cluster capacity: 2 TiB Selected nodes: 3 node CPU and memory: 48 CPU and 181.7 GiB memory Zone: 1 zone Taint nodes: Disabled Security and network Encryption: Disabled Network: Default (SDN)
(4) ODFクラスタの確認
OpenShiftポータルのAdministrator Perspectiveから[Storage]>[Data Fundation]を選択し、以下の表記に変わればクラスタ作成は完了です。
ODFクラスタが立ち上がってそのボリュームが利用できるまで10分くらい待ちます。

Tackle Operatorのインストール
ボリュームが用意できたら、次にTackle Operatorをインストールしていきます。
(1) Operator Hubから「Tackle Operator」を検索してインストール

(2) OperatorのSubscriptionを定義してインストール実行
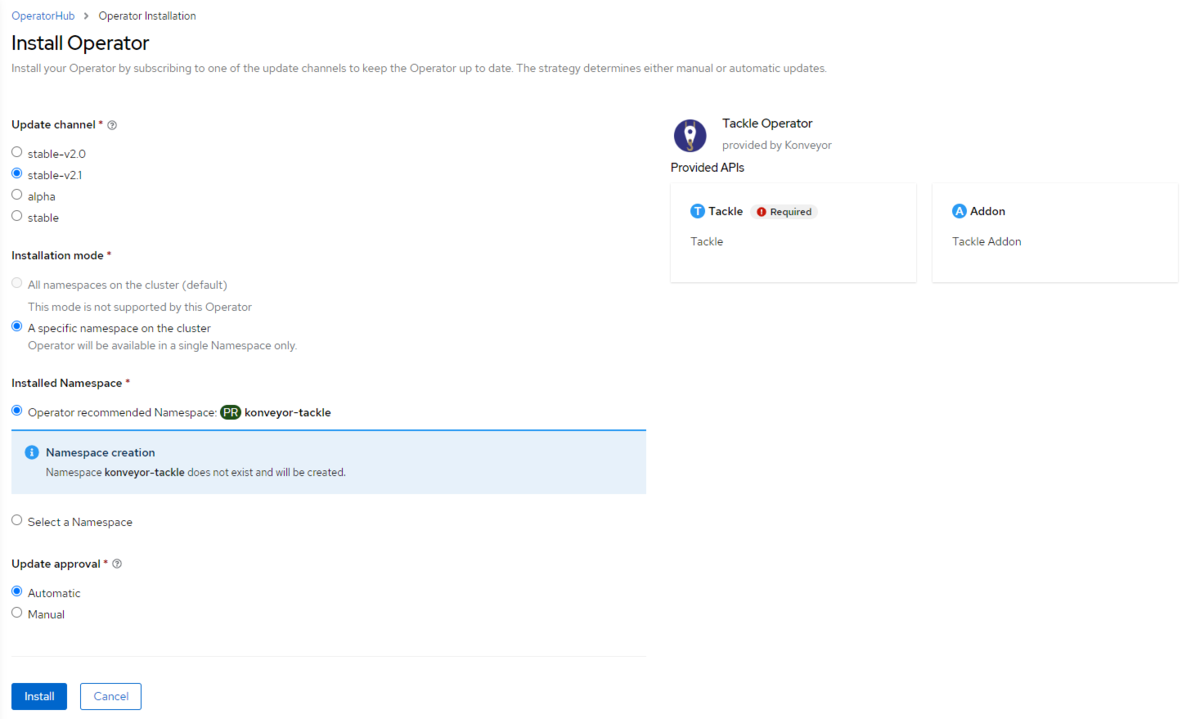
(3) CustomResource(Tackle)の作成
Tackle Operatorには、CR(Tackle)の作成必須です。Operatorのインストール作業が終わるとすぐに作るように求められます。
また、通常通り[Operaors]>[Installed Operators]から「Tackle Operator」を選択し、[Tackle]タブにある「Create Tackle」からも設定が可能です。
ここで注意することは、先ほど作成したODFの領域をRWXストレージ領域として割り当てることです。通常であればフォームから作成しますが、フォームにストレージを設定する項目がないため今回はYAML形式でCRを記載してください。
CRには、hub_bucket_storage_classにODFで作成されたRWXのストレージクラス(ocs-storagecluster-cephfs)を設定します。
なお、CRの詳細はこちらからご確認下さい。
apiVersion: tackle.konveyor.io/v1alpha1 kind: Tackle metadata: name: tackle namespace: konveyor-tackle spec: feature_auth_required: 'true' hub_bucket_volume_size: "50Gi" hub_bucket_storage_class: "ocs-storagecluster-cephfs" cache_data_volume_size: "50Gi"
(4) Tackle UIの確認
CR(Tackle)によってインストールが終わると、Project[konveyor-tackle]のRouteにTackle UIへの接続URLが払い出されます。
OpenShiftポータルのAdministrator Perspectiveから[Networking]>[Routes]を選択し、[Tackle]のURLにブラウザから接続して以下が表示されたら完了です。

ここでのデフォルトのユーザー名とパスワードは以下のとおりです。
Username: admin
Password: Passw0rd!
ログインすると、始めにパスワードの変更が求められます。
Tackle Controlsによるエンティティ登録
Tackleのポータルには「Application Inventory」「Reports」「Controls」が表示されます。まずは「Tackle Controls」から評価対象の構成要素を作成しておきます。
Tackle ControlsはApplication Inventoryで利用されるエンティティの管理です。これらはStakeholders(利害関係者)、Stakeholder groups(利害関係者グループ)、Job functions(職務)、Business Service(ビジネスサービス)、Tags(タグ タイプ)で構成されています。

今回はサンプルのアプリケーション登録のため、必要がない場合は「エンティティ登録」は一旦スキップしていただいても構いません。
(1) Stekeholders(利害関係者)の登録
対象アプリケーションに携わる関係者とその属性を登録します。Tackle Controlsの[Stakeholders] タブから[Create new] を選択して情報を登録します。

(2) Stekeholder groups(利害関係者グループ)の登録
次に彼らのグループを登録します。Tackle Controlsの[Stakeholder groups] タブから[Create new] を選択して情報を登録します。

必要に応じて、先程登録したStakeholdersをメンバーに加えておきます。
(3) Business Service(ビジネスサービス)の登録
次にビジネスサービス名を登録します。Tackle Controlsの[Business Service] タブから[Create new] を選択して情報を登録します。

必要に応じて、先程登録したStakeholdersをメンバーに加えておきます。
以上で最小の登録は完了です。

Windupによる「Analyze(分析)」
次にWindupを使ってアプリケーションを分析してみましょう。
Application Inventryは、Tackle Pathfinderによる評価(Assessment)とWindupによる分析(Analysis)のインターフェイスです。双方行えますが、今回は分析の方を紹介します。

(1) Applicationの登録
まずは、Tackle Application Inventryの[Analysis]タブから[Create new]を選択して以下の情報を登録します。
Name: Customer
Description: Legacy Customers management service
Business Service: Retail
Tags: Tomcat, Java

Applicationの登録が完了するとApplication Inventoryのページに一度戻ります。[Assessment]、[Analysis]の双方にApplicationが登録されていれば完了です。
(2) Analysis(分析)の開始
Tackle Application Inventryの[Analysis]タブから登録したApplicationを選択し、[Analysis]ボタンを押します。

(3) Analysis Mode
立ち上がったポップアップからAnalysisの対象を登録します。
ここではローカルのサンプルをアップロードするため「Upload a local binary」を選択してください。
ダウンロードしたcustomers-tomcat.warファイルをドラッグアンドドロップするか、ローカル ファイル システムからアップロードします。

アップロードが完了するまで、おそらく数秒かかります。「Success: Uploaded binary file.」の表示が出るまで少し待ちましょう。登録が完了したら「Next」を押して次に行きます。
(4) Set Targets
次は変換先のターゲットオプションが表示されます。ここでは、移行するテクノロジーを選択します。
サンプルは Linuxコンテナをターゲットとして、独自JDKディストーションの依存を取り除くため、Containerization、Linux、 OracleJDK to OpenJDKをターゲットとして選択します。
登録が完了したら「Next」を押して次に行きます。
(5) Application Scope
診断するアプリケーションに関する依存関係のスコープが選べます。
今回はアプリケーション内部のライブラリだけで良いため、Application and internal dependencies onlyを選択してください。

(6) Application Scope
分析には、カスタムルールエンジンが使用されており、移行ターゲットに応じて多くのルールが付属されています。
またカスタムルールをXMLで独自に作成することで拡張も可能です。
ここではアプリで使用されている特定のライブラリの使用を検出し、削除を提案するカスタム ルールを提供してみます。
ダウンロードしたカスタムルールファイルをドラッグ アンド ドロップするか、ローカル ファイル システムからアップロードします。

(7) Options
分析を微調整するためのオプションが表示されますが、今回はデフォルトのまま使用します。

(8) Reviews
最後に全体の確認を行います。ここまで登録できると以下が表示されています。
Review analysis details Review the information below, then run the analysis. Applications: Customer Mode: Upload a local binary Targets: - openjdk - linux - cloud-readiness Sources: - java Scope: Application and internal dependencies Included packages: Excluded packages: Custom rules: - corporate-framework-config.windup.xml Excluded rules tags: Transaction Report: Disabled
確認して問題がなければ[Run]を押して分析を実行します。
分析を実行する前に、Windup用のコンテナイメージをプルする必要があるため、分析には数分かかる場合があります。
Windupによる「Analyze(分析)」結果レポート
レポートが完成したら、リンクをクリックしてレポートにアクセスし、アプリケーション(customers-tomcat.war)をクリックします。

レポートのDashboardにはアプリケーションが使用するテクノロジや依存関係などあらゆる情報が提供されますが、修正が必要な点は「Issues」タブに記載されています。

必須の修正箇所は以下の4件です。
- Legacy configuration - 2件
- Hard coded IP address - 1件
- File system - Java IO - 1件
それぞれのリンクを辿りながら、簡単に詳細を見ていきましょう。
(1) Legacy configuration
これは先程カスタムルールで定義した課題がソースコードから見つかったことを示しています。

内容としては、従来のApplicationConfigurationクラスが使用されていることが指摘されています。Springの@PropertySourceアノテーションとEnvironmentクラスを使用したアプローチに置き換えるよう推奨されています。
Kubernetesを利用したアプリケーションでは、内部でパラメータ設定を行うのではなくConfigMapやSecretなどで環境変数として取り扱うことが推奨されています。
冒頭のCNDT 2022の資料とも合わせて確認してください。
(2) Hard coded IP address
次は、ソースコードにDBに接続するためのIPアドレスが定義されていることを指摘されています。

プロパティファイル(WEB-INF/classes/persistence.properties)に、アドレスが記載されているため、Kubernetesではサービス名などに置き換える必要があります。
(3) File system - Java IO
最後はローカルにあるプロパティファイル(/opt/config/persistence.properties)を呼び出していることが指摘されています。

Kubernetes上ではローカルホストに置かれたファイルをマウントすることは推奨されていないため、ConfigMapなどを活用して設定情報を取り扱ってください。
まとめ
Konveryor Tackleいかがでしたでしょうか。今回は簡単なアプリケーションを診断にかけてみました。
クラウドネイティブにマイクロサービス化することも重要なことではありますが、まずはReplatformによってコンテナ化するところから始めてみましょう。
その選択肢の一つとして、Konveryor Tackleを使ってみてはいかがでしょうか。
最後に、大事なこともぅ一度お伝えしておくと、12/21 - 12/23とコーチェラ再現Liveがあるので是非楽しみましょう。 「Special Live 2022 -Back To Coachella-」
*1:これは、Red Hat Modern Application Development Workshopで利用される分析用のサンプルファイルです。
*2:これは、Red Hat Modern Application Development Workshopで利用される分析用のサンプルファイルです。